**IAIC 2025-26**
Ejercicios Propuestos
# Representación, Búsqueda y Optimización
## Lógica
Recuerda que el objetivo de los siguientes ejercicios es que afiances las definiciones y métodos vistos en clase. Por ello, has de ser capaz de resolver los ejercicios a mano, y comprobar su resolución con las implementaciones vistas en clase.
!!!ejercicio:Ej. 1
Para cada una de las fórmulas siguientes, determina todos sus modelos e indica si son satisfactibles, insatisfactibles o tautologías:
* $p → (q → r ∧ q)$
* $q → (p ∧ ¬p) → r$
* $(p ↔ q) ∧ (p → ¬q) ∧ p$
* $(p ∧ r) ∨ (¬p ∧ q) → ¬q$
!!!ejercicio:Ej. 2
Haciendo uso de la definición de consecuencia lógica, decide cuáles de las siguientes afirmaciones son verdaderas:
* $\{p ∨ q\} \models p → r$
* $\{p → q,\ q → p ∧ r\} \models p → (p → q) → r$
* $\{p ∧ ¬p\} \models r → r ∨ q$
* $\{p ∧ q ∧ r\} \models r → ¬p$
!!!ejercicio:Ej. 3
Formaliza los siguientes argumentos y decide si son correctos o no:
* Si la tormenta continúa o anochece, nos quedaremos a cenar o a dormir; si nos quedamos a cenar o a dormir no iremos mañana al concierto; pero sí iremos mañana al concierto. Así pues, la tormenta no continúa.
* Si un triángulo tiene tres ángulos, un cuadrado tiene cuatro ángulos rectos. Un triángulo tiene tres ángulos y su suma vale dos ángulos rectos. Si los rombos tienen cuatro ángulos rectos, los cuadrados no tienen cuatro ángulos rectos. Por tanto, los rombos no tienen cuatro ángulos rectos.
* Si la gorila es atractiva, el gorila sonreirá abiertamente o será infeliz. Si no es feliz, no procreará en cautividad. Por consiguiente, si la gorila es atractiva, entonces, si el gorila no sonríe abiertamente, no procreará en cautividad.
* Si Elvira opina que hay que hacer lo posible para ser feliz, abandonará a su amante o se dedicará a su profesión. Si se dedica a su profesión, no dejará a su marido. En conclusión, si Elvira opina que hay que hacer lo posible para ser feliz, entonces, dejará a su marido aunque no abandone a su amante.
* Si los astrónomos observan un nuevo planeta con atmósfera fuera de nuestro sistema solar, la Tierra no será el único planeta habitable en el Universo. O la Tierra no es el único planeta habitable o hay sistemas inexplorados. Por tanto, o los astrónomos no observan un nuevo planeta con atmósfera, fuera de nuestro sistema solar, o la Tierra es el único planeta habitable en el Universo.
* Si no es cierto que se puede ser rico y dichoso a la vez, entonces la vida está llena de frustraciones y no es un camino de rosas. Si se es feliz, no se puede tener todo. Por consiguiente, la vida está llena de frustraciones.
!!!ejercicio:Ej. 4
Decide la corrección del siguiente argumento. Se sabe que:
* Los animales con pelo o que dan leche son mamíferos.
* Los mamíferos que tienen pezuñas o que rumian son ungulados.
* Los ungulados de cuello largo son jirafas.
* Los ungulados con rayas negras son cebras.
Se observa un animal que tiene pelos, pezuñas y rayas negras. Por consiguiente, se concluye que el animal es una cebra.
!!!ejercicio:Ej. 5
En una isla hay dos tribus, la de los veraces (siempre dicen la verdad) y la de los mentirosos (que siempre mienten).
1. Un viajero se encuentra con tres isleños A, B y C, y quiere saber a qué tribu pertenecen, teniendo como única información lo que le dice cada uno de ellos:
* A dice “B y C son veraces si y solo si C es veraz”.
* B dice “Si A y C son veraces, entonces B y C son veraces y A es mentiroso”.
* C dice “B es mentiroso si y solo si A o B es veraz”.
2. Además, el viajero le pregunta a otro nativo: “¿Hay oro en la isla?”, a lo que este responde:
*Hay oro en la isla si y sólo si yo siempre digo la verdad*
¿Hay oro en la isla? ¿Podemos determinar a qué tribu pertenece este último nativo?
!!!ejercicio:Ej. 6
Tres niños, Manolito, Juanito y Paquito, son sorprendidos después de haberse roto el cristal de una ventana cerca de donde estaban jugando. Al preguntarles si alguno de ellos lo había roto, respondieron lo siguiente:
* Manolito: “Juanito lo hizo, Paquito es inocente”.
* Juanito: “Si Manolito lo rompió, entonces Paquito es inocente”.
* Paquito: “Yo no lo hice, pero uno de los otros dos sí lo rompió”.
¿Son consistentes las afirmaciones anteriores? Si se comprueba que ninguno de los niños rompió el cristal, ¿quiénes han mentido? Si se asume que todos dicen la verdad, ¿quién rompió el cristal?
!!!ejercicio:Ej. 7
1. Sea $S = \{p → q,\ ¬s ∧ r → q,\ ¬q,\ q ↔ r ∧ s\}$. Obtén todos los modelos de $S$ por medio de DPLL.
2. Sea $S= \{p ∨ q → m,\ m ∧ (s ∨ r) → u,\ u ∧ w → j,\ u ∧ r → v,\ p ∧ s ∧ r → v,\ ¬v\}$. Decide, usando DPLL, si $S$ es consistente. En caso de que lo sea, explicita un modelo que devuelva el algoritmo.
!!!ejercicio:Ej. 8: **La perspicacia del inspector Lafrite**
Lafrite está encargado de la investigación sobre un robo de cuadros en una galería de arte. Pidió a Relbou y Gremai, dos de sus asistentes, que le ayudaran en el asunto. La investigación terminó con el arresto de cuatro personas: Jules Rateau, Desiré Lafrange, Michel Boileau y Felicie Ossy.
Los interrogatorios los realizan los dos asistentes, que extraen las siguientes conclusiones tras interrogar a los sospechosos:
1. Relbou: *Jules Rateau es inocente, pero estoy seguro de que por lo menos uno de los otros es culpable*.
2. Gremai: *Si Desiré Lafrange es culpable, no hay más que un cómplice, que está entre los demás*.
3. Relbou: *Y si Michel Boileau es culpable, pienso que tiene dos cómplices entre los otros*.
A raíz de lo cual Lafrite dice:
*Si considero que lo que me dicen es cierto, puedo afirmar la culpabilidad de una de las cuatro personas*.
¿Puedes ayudar a los inspectores a encontrar a esa persona?
!!!ejercicio:Ej. 9
Formaliza los siguientes argumentos en una Lógica de Primer Orden (si es necesario, con igualdad) decidiendo los elementos adecuados del lenguaje (predicados, funciones y constantes):
1. Existe una persona en la Feria tal que si dicha persona paga, entonces todas las personas pagan.
2. Sócrates es un hombre. Los hombres son mortales. Luego, Sócrates es mortal.
3. Hay estudiantes inteligentes y hay estudiantes trabajadores. Por tanto, hay estudiantes inteligentes y trabajadores.
4. Todos los participantes son vencedores. Hay como máximo un vencedor. Hay como máximo un participante. Por lo tanto, hay exactamente un participante.
5. Juan teme a María. Pedro es temido por Juan. Luego, alguien teme a María y a Pedro.
6. Los hermanos tienen el mismo padre. Juan es hermano de Luis. Jorge es padre de Luis. Por tanto, Jorge es padre de Juan.
7. Los aficionados al fútbol aplauden a cualquier futbolista extranjero. Juanito no aplaude a futbolistas extranjeros. Por tanto, si hay algún futbolista extranjero nacionalizado español, Juanito no es aficionado al fútbol.
8. Toda persona pobre tiene un padre rico. Por tanto, existe una persona rica con abuelo rico.
9. Todo lo existente tiene una causa. Luego hay una causa de todo lo existente.
10. Todos los robots obedecen a los amigos del programador jefe. Alvaro es amigo del programador jefe, pero Benito no le obedece. Por tanto, Benito no es un robot.
11. Supongamos conocidos los siguientes hechos acerca del número de aprobados de dos asignaturas A y B:
* Si todos los alumnos aprueban la asignatura A, entonces todos aprueban B.
* Si algún delegado de la clase aprueba A y B, entonces todos los alumnos aprueban A.
* Si nadie aprueba B, entonces ningún delegado aprueba A.
* Si Manuel no aprueba B, entonces nadie aprueba B.
* Por tanto, si Manuel es un delegado y aprueba la asignatura A, entonces todos los alumnos aprueban las asignaturas A y B.
12. Carlos afeita a todos los habitantes de Sevilla que no se afeitan a sí mismos y sólo a ellos. Carlos es un habitante de Sevilla Por consiguiente, Carlos no afeita a nadie.
!!!ejercicio:Ej. 10
Haciendo una adecuada conversión de Primer Orden en Proposicional para poder hacer uso de DPLL, intenta determinar la consistencia de los siguientes conjuntos de clausulas (como es habitual, las primeras letras del alfabeto representan constantes, las últimas son variables, y las mayúscula representan predicados):
* $\{Q(u)∨P(a), ¬Q(w)∨P(w), ¬Q(x)∨¬P(x)\}$
* $\{Q(u)∨P(a), ¬Q(w)∨P(w), ¬Q(x)∨¬P(x), Q(y)∨¬P(y)\}$
* $\{I(a), ¬R(x)∨L(x), ¬D(y)∨¬L(y), D(a)\}$
* $\{I(a), ¬R(x)∨L(x), ¬D(y)∨¬L(y), D(a), ¬I(z)∨R(z)\}$
* $\{¬P(x,y)∨¬P(y,z)∨P(x,z), P(a,x), P(x,b), P(x,f(x))\}$
## Satisfacción de Restricciones
Representa los siguientes problemas como CSP y resuélvelos. El objetivo es que hagas un modelado abstracto (en papel) que después te sirva para hacer un modelado computacional que puedas resolver usando las librerías vistas en clase. En algunos de los problemas planteados se propone una casuística general, que después tendrás que comprobar creando una batería de ejemplos de casos particulares:
!!!ejercicio:Ej. 1: **Criptoaritmética**
Un problema de criptoaritmética establece una relación aritmética entre palabras que codifican números. El objetivo es asignar valores (dígitos entre $0$ y $9$) a las letras que forman esas palabras de forma que se verifiquen las relaciones aritméticas expresadas, con la restricción de que letras distintas tienen asignaciones distintas, y ninguna de las cifras empieza por $0$. Por ejemplo:
`send + more = money`
`dos + dos + tres = siete`
`seis + catorce + setente = noventa`
`send + more + gold = money`
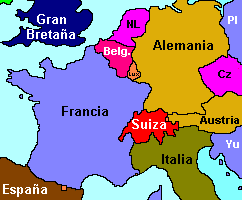
!!!ejercicio:Ej. 2: **Problema del $k$-coloreado de Mapas**
El problema original consiste en ver el número de colores que deben usarse para colorear los países de un mapa con el objetivo de diferenciarlos adecuadamente (dos países con frontera común, deben colorearse con colores distintos):
Lo podemos traducir a un problema de grafos equivalente (y que generaliza el problema fundamental que hay detrás):
Fijado un grafo, $G=(V,E)$, determina (y en caso positivo, proporciona) si existe una coloración válido de $G$ haciendo uso de $k$ colores. Una coloración es una asignación de colores a $V$, y es válida si nodos conectados por $E$ están coloreados con colores distintos.
$$c:V\to \{1,\dots,k\}$$
$$(v_1,v_2)\in E ⇒ c(v_1)\neq c(v_2)$$
Determina el menor $k$ para el que podemos encontrar una $k$-coloración válida de $G$.
!!!ejercicio:Ej. 3: **Sudoku**
Este problema se publicó en Nueva York en el año 1979 bajo el nombre de *Number Place* y se hizo popular en Japón con el nombre de sudoku (*Sudji wa dokushin ni kagiru*: *los números deben aparecer una vez*). Es un problema ampliamente conocido, así que lo describimos muy brevemente. Disponemos de una rejilla de $9×9$ casillas en las que se deben colocar números entre $1$ y $9$ con la condición de que:
1. En cada casilla solo puede ir un número.
1. En cada fila no se repiten números.
2. En cada columna no se repiten números.
3. En cada submatriz de tamaño $3×3$ no se repiten números (estas submatrices dividen la rejilla completa en $9$ espacios disjuntos del mismo tamaño).
4. A veces, se dan algunos valores fijos en la rejilla inicial que hay que respetar.
!!!ejercicio:Ej. 4: **Puzzle de las Esquinas**
Este rompecabezas pide que se coloquen los dígitos del $1$ al $8$ en los bordes del cuadrado (tal y como se indica en la figura siguiente, un dígito en cada celda) de modo que el número de cada celda lateral sea igual a la suma de los números de las esquinas contiguas.
~~~~none
.----+----+----.
| NO | N | NE |
+----+----+----+
| O | | E |
+----+----+----+
| SO | S | SE |
'----+----+----'
~~~~
!!!ejercicio:Ej. 5: **Clases en la E.T.S.I.I**
Alicia, al volver de la escuela, describe las cuatro asignaturas (`IA`, `SI`, `MD` y `PD`) a las que ha asistido a su amigo Juan. A Juan le interesa ir a las cuatro asignaturas, pero ella no recuerda exactamente en qué aula fue cada una ni el orden, solo recuerda haber estado en las aulas `A1.16`, `H1.12`, `I1.32`, y la `F0.10`, y alguna información adicional sobre su mañana. Identifica dónde se imparte cada asignatura y en qué orden:
1. Alicia acudió a la la `H1.12` para `SI`.
2. Después de haber acudido a `MD` no fue la `F0.10`.
3. La segunda clase la recibió en la `A1.16`.
4. Dos clases después de salir de la `I1.32`, acudió a `PD`.
!!!ejercicio:Ej. 6: **Problema de las N reinas:**
Sitúa \(N\) reinas en un tablero de ajedrez de tamaño \(N\times N\) sin que se amenacen entre ellas. Se recuerda que dos reinas se amenazan entre sí si ambas están en la misma fila, columna o diagonal.
El caso más común es el de $N=8$, el trablero de ajedrez estándar, y fue propuesto por el ajedrecista alemán Max Bezzel en 1848. Edsger Dijkstra usó este problema (en su versión general) en 1972 para ilustrar el poder de la llamada programación estructurada. Publicó una descripción muy detallada del desarrollo del algoritmo de backtracking DFS.
!!!ejercicio:Ej. 7: **Tomografía Discreta**
Una matriz que contiene $0s$ y $1s$ se escanea vertical y horizontalmente, dando el número total de $1s$ en cada fila y columna. ¿Es posible reconstruir el contenido de la matriz a partir de esta información? Por ejemplo:
~~~~none
0 7 1 6 3 4 5 2 7 0
0
8 ■ ■ ■ ■ ■ ■ ■ ■
2 ■ ■
6 ■ ■ ■ ■ ■ ■
4 ■ ■ ■ ■
5 ■ ■ ■ ■ ■
3 ■ ■ ■
7 ■ ■ ■ ■ ■ ■ ■
0
~~~~
!!!ejercicio:Ej. 8: **Buscaminas**
Un campo minado viene dado por una matriz numérica que indica cuántas minas son adyacentes a cada posición (si hay un número, no puede haber una mina). Podemos usar la representación siguiente:
* ■ representa contenido desconocido (pudiendo haber, o no, una mina en esa posición),
* □ representa espacio sin mina,
* * representa una mina,
* posiciones con números indican el número de minas que le rodean (pero no hay minas en ellos).
El objetivo consiste en decubrir dónde están todas las minas de un campo minado con información parcial. Por ejemplo:
~~~~none
■ ■ 2 ■ 3 ■ * □ 2 □ 3 *
2 ■ ■ ■ ■ ■ 2 * □ * * □
■ ■ 2 4 ■ 3 ==> □ □ 2 4 * 3
1 ■ 3 4 ■ ■ 1 □ 3 4 * □
■ ■ ■ ■ ■ 3 □ * * * □ 3
■ 3 ■ 3 ■ ■ * 3 □ 3 * *
~~~~
!!!ejercicio:Ej. 9: **Problema de Asignación de Tareas**
Queremos hacer una asignación de tareas (`Programación`, `Diseño`, `Testing`, `Documentación` y `Reunión`) a los trabajadores de un proyecto (`Alice`, `Bob`, `Charlie` y `Diana`) de nuestra empresa considerando sus habilidades y disponibilidad, pero teniendo en cuenta que ninguno de ellos puede tener más de 2 tareas. Las habilidades y disponibilidad que tienen son:
* `Alice` no tiene conocimientos de `Testing`.
* `Bob` solo tiene experiencia en `Programación` o `Testing`.
* `Charlie` no está disponible para hacer `Reuniones`.
* Debido a conflictos de tiempo, ningún trabajador puede hacer `Programación` y `Testing` al mismo tiempo.
!!!ejercicio: Ej. 10: **Planificación de Reuniones**
Tenemos que programar un conjunto de reuniones evitando posibles conflictos entre sus participantes. Las diversas reuniones que tenemos que preparar son las del `Proyecto` en ejecución, la de `Presupuesto`, la de `Marketing` y la de `Recursos Humanos`. Para poder programarlas disponemos de un conjunto de slots de tiempo: `Lunes 10am`, `Lunes 2pm`, `Martes 10am`, `Martes 2pm` y `Miércoles 10am`, y sabemos quiénes deben asistir a cada reunión:
* A la del `Proyecto` deben acudir `Ana`, `Carlos` y `Elena`.
* A la de `Presupuesto` deben acudir `Ana`, `David`, `Fernando`.
* A la de `Marketing` deben acudir `Carlos`, `Elena`, `Gabriela`.
* A la de `Recursos Humanos` deben acudir `David`, `Elena`, `Helena`.
Obviamente, las reuniones con participantes en común no pueden ser al mismo tiempo. Además, `Ana` prefiere no tener reuniones los miércoles.
¿Qué opciones se tienen para programar las reuniones semanales? ¿Habría opciones para hacer más de una reunión semanal de algunas de estas reuniones?
!!!ejercicio: Ej. 11: **Diseño de Horario Docente**
Tenemos como objetivo diseñar un horario para un curso, asignando adecuadamente las materias, profesores, aulas y horarios disponibles. Siguiendo las restricciones mencionadas, debemos asegurarnos de que:
- Un profesor no puede estar en dos aulas al mismo tiempo.
- Un aula no puede estar ocupada por dos materias al mismo tiempo.
Hemos de organizar las siguientes materias: `Cálculo`, `Física`, `Programación`, `Álgebra`, `Química`, `Estadística`, `Lógica`, e `Inglés`. Y tenemos un conjunto de profesores que, según su especialización, pueden encargarse de distintas materias:
* `Martínez` puede impartir `Cálculo`, `Álgebra` y `Estadística`.
* `Rodríguez` puede impartir `Física` y `Química`.
* `García` puede impartir `Programación` y `Estadística`.
* `López` puede impartir `Cálculo`, `Álgebra` y `Física`.
* `Hernández` puede impartir `Lógica` e `Inglés`.
* `Ruíz` puede impartir `Programación`, `Química` e `Inglés`.
Hay algunas materias (`Programación` y `Química`) que deben impartirse en laboratorios, de los que disponemos dos: `LAB1` y `LAB2`. Mientras que `Física` puede impartirse en esos laboratorios o también en las aulas `A101` o `A102`. El resto de materias deben impartirse en un aula normal (`A101`, `A102`, `A103`, `B201`, `B202`).
La universidad funciona de Lunes a Viernes, en horario de 8AM, 10AM y 4PM (aunque el viernes se evitan las clases de la tarde).
Se quiere dar una carga de trabajo equilibrada, haciendo que ninguno de los profesores imparta más de 3 materias. Algunas materias están relacionadas y no deben impartirse simultáneamente, en particular: `Cálculo` y `Física` están relacionadas, así como `Álgebra` y `Estadística`. Además, las materias de `Lógica` e `Inglés` necesitan recursos que no están disponibles a primera hora, así que deben evitar ese horario.
## Búsqueda y Planificación en Espacios de Estados
Los siguientes problemas se pueden resolver por cualquiera de los algoritmos de búsqueda vistos (incluido Templado Simulado). Cuando el problema se plantee de forma general, la idea será dar funciones que permitan describir paramétricamente el problema y después usar las implementaciones para dar soluciones particulares. Además, recuerda que la mayoría de los problemas vistos en los temas anteriores también se pueden resolver como Espacios de Estados.
Identifica previamente si el problema es de decisión, de construcción, de planificación o de optimización, y elige el algoritmo más adecuado para resolverlo.
!!!ejercicio:Ej. 1: **Problema de las 2 Jarras**
Se tienen dos jarras de agua, una de \(4\) litros y otra de \(3\) litros sin escala de medición. Se desea obtener \(2\) litros de agua en la jarra de \(4\) litros. Las operaciones válidas son: llenar completamente cada una de las jarras, vaciar completamente una de las jarras, pasar agua de una jarra a otra (hasta que la primera se vacía o la segunda se llena).
!!!ejercicio:Ej. 2: **Problema de las \(3\) Jarras**
Se tienen \(3\) jarras de \(12\), \(8\) y \(3\) litros de capacidad y un grifo. Las operaciones que se pueden realizar con ellas son: llenar cada una de las jarras de agua, volcar el contenido de una en cualquier otra (hasta que una se vacía o la otra se llena), o bien vaciar su contenido en el suelo. El objetivo es conseguir exactamente \(1\) litro en alguna de las jarras.
!!!ejercicio:Ej. 3: **Humanos y zombies:**
Hay \(3\) humanos y \(3\) zombies a la orilla de un río que desean cruzar a la otra orilla. Tienen una canoa con capacidad para dos personas como máximo, y si intentan cruzar más, se hundirá y morirán los ocupantes.
Hay que considerar que no debe haber más zombies que humanos en ningún sitio porque entonces los zombies se comerían a los humanos. Además, la canoa siempre debe ser conducida por alguien (no puede cruzar el río sola).
¿Cuál es una buena sucesión de movimientos para que al final consigan cruzar todos?
!!!ejercicio:Ej. 4: **El Granjero:**
Un granjero va al mercado y compra un lobo, una oveja y una col. Para volver a su casa tiene que cruzar un río. El granjero dispone de una barca para cruzar a la otra orilla, pero en la barca solo caben él y una de sus compras. El problema que tiene es que si el lobo se queda solo con la oveja, se la come, y si la oveja se queda sola con la col, se la come. El reto del granjero es cruzar el río con todas sus compras. ¿Cómo puede hacerlo?
!!!ejercicio:Ej. 5: **Cuadrado Mágico**
Un cuadrado mágico consiste en una distribución de números en filas y columnas, formando un cuadrado, de forma que los números de cada fila, columna y diagonal suman lo mismo.

Aunque es posible recrear diferentes tipos de cuadrados mágicos, tradicionalmente se forman con los números naturales desde el \(1\) hasta \(n^2\), donde \(n\) es el lado del cuadrado.
!!!ejercicio:Ej. 6: **Montones de Cartas**
Tenemos \(10\) cartas numeradas del \(1\) al \(10\). Sepáralas en \(2\) montones de forma que la suma de las cartas del primer montón esté _lo más cerca posible_ de \(36\) y el producto de las cartas del segundo montón esté lo más cerca posible de \(360\).
!!!ejercicio:Ej. 7: **\(8\)-puzzle**
Es un puzle de deslizamiento que consiste en un conjunto de \(8\) piezas en un marco de tamaño \(3\times 3\), por lo que queda un hueco libre. El objetivo del puzle consiste en encontrar la sucesión de movimientos (moviendo piezas al hueco libre) que llevan la distribución inicial a una distribución ordenada prefijada.

Se pueden pensar variantes con \(m\times n\) huecos. por ejemplo, el 15-puzzle hace uso de un marco de tamaño $4\times 4$.
!!!ejercicio:Ej. 8: **Torres de Hanoi**
Se tienen \(N\) discos de distinto tamaño apilados sobre una base \(A\) de manera que cada disco se encuentra sobre uno de mayor radio. Existen otras dos bases vacías \(B\) y \(C\). Haciendo uso únicamente de las 3 bases, el objetivo es llevar todos los discos de la base \(A\) hasta la base \(C\). Solo se puede mover un disco a la vez, y cada disco puede descansar solamente en las bases (directamente) o sobre otro disco de tamaño superior.

El caso más habitual es $N=3$ y con 3 discos.
!!!ejercicio:Ej. 9: **Problema de las bolsas**
Se pretende encontrar una manera de distribuir un conjunto de objetos, \(O=\{o_1,\dots,o_n\}\), en bolsas usando el menor número posible de ellas. Cada objeto tiene un peso asociado, $p_i$, y las bolsas tienen un límite de peso máximo soportado, \(B\).
!!!ejercicio:Ej. 10: **Suma nula**
Dado un conjunto de enteros \(I=\{i_1,\dots,i_n\}\), el problema es encontrar un subconjunto \(S\subseteq I\) cuyos elementos sumen \(0\).
!!!ejercicio:Ej. 11: **El juego de las Ranas**
Tenemos $N$ ranas negras y $N$ verdes situadas encima de $2N+1$ nenúfares tal y como muestra la imagen adjunta (en el caso particular de $N=3$). Comienza cada grupo de ranas en un extremo distinto de la fila de nenúfares. El objetivo consiste en intercambiar la posición de las ranas negras y verdes con el menor coste. Para ello, los movimientos permitidos son los siguientes:
* Una rana puede moverse a un nenúfar adyacente vacío, con coste 1.
* Una rana puede desplazarse a un nenúfar vacío saltando por encima de una rana como máximo, con un coste igual a 2.
!!!ejercicio:Ej. 12: **Juego de las Cifras (Cifras y Letras)**
Dados \(6\) números, y un objetivo \(O\), encontrar la combinación aritmética (se permite la división entre ellos, pero solo si el resultado es entero) que se aproxima lo más posible a \(O\).
!!!ejercicio:Ej. 13
Trabajaremos con números de 3 cifras (de \(100\) a \(999\)). Inicialmente, tenemos dos números prefijados, que denotaremos por \(S\) (Start) y \(G\) (Goal), y un conjunto de números que denotaremos por \(P\) (de Prohibidos). En cada turno, podemos transformar un número en otro añadiendo/sustrayendo 1 a uno de sus dígitos (por ejemplo, pasando de \(678\) a \(679\), o de \(234\) a \(134\)). El coste de cada movimiento es 1. Adicionalmente, tenemos estas restricciones:
* No se permite añadir \(1\) a \(9\), ni sustraer \(1\) a \(0\).
* No se permite convertir un número en un elemento de \(P\) (están prohibidos).
* No se puede cambiar un mismo dígito 2 veces seguidas.
Además de dar la representación general, resuelve el caso particular \(S = 567\), \(G = 777\) y \(P = \{666, 667\}\).
!!!ejercicio:Ej. 14
Un ayuntamiento tiene que adjudicar 10 proyectos de obra mediante concurso público. Se han presentado al concurso 5 empresas, dando presupuestos para cada uno de los diez proyectos. La adjudicación debe realizarse de manera que a cada empresa solo se le concedan dos proyectos. Encuentra la adjudicación de menor precio.
!!!ejercicio:Ej. 15
Un ganadero tiene un rebaño de ovejas. Cada oveja tiene un peso y se vende por un precio prefijado. El ganadero dispone de un camión que es capaz de cargar un peso máximo. Su problema es seleccionar una colección de ovejas para llevarlas al mercado de ganado en el camión de manera que se maximice el precio total de las ovejas transportadas, sin superar el peso total soportado por el camión.
!!!ejercicio:Ej. 16: **Problema de asignación de tareas:**
Disponemos de un conjunto de agentes que deben resolver un proyecto que costa de un conjunto de tareas a realizar. Cualquier agente puede ser asignado para desarrollar cualquier tarea, pero solo un agente podrá trabajar sobre ella. La ejecución de cada tarea supone un coste que depende del agente y de la tarea concreta. Un mismo agente puede realizar más de una tarea, pero ha de tenerse en cuenta que cada tarea consume una cantidad de recursos del agente (que también depende del agente y de la tarea), y los recursos de cada agente son limitados (el límite depende de cada agente).
El coste de realización del proyecto es la suma de los costes de todas las tareas realizadas. Encuentra una asignación de tareas factible y de coste mínimo.
!!!ejercicio:Ej. 17: **Particionamientos de un grafo: Problema Max-Cut**
Dado un grafo \(G = (V,E)\) sin ciclos, donde cada arista lleva asociado un peso entero positivo, se trata de encontrar una partición de \(V\) en dos conjuntos disjuntos, \(V_0\) y \(V_1\) de tal manera que la suma de los pesos de las aristas que tienen un extremo en \(V_0\) y el otro extremo en \(V_1\), sea máximo.
!!!ejercicio:Ej. 18: **Problema del conjunto de vértices independientes**
Dado un grafo \(G = (V,E)\), se trata de encontrar el denominado conjunto maximal de vértices independientes, es decir el conjunto \(VIM \subseteq V\) de mayor cardinalidad para el cual ninguna de sus aristas se encuentre en \(E\).
!!!ejercicio:Ej. 19
El grafo que se muestra abajo determina un problema de búsqueda. Cada nodo representa un estado; los arcos modelan la aplicación de operadores. Supongamos que A es el estado inicial y que K y E son estados finales.

* Desarrolla el árbol de búsqueda que genera la búsqueda en anchura, sin filtrar estados repetidos. ¿Cuál de los nodos finales se encuentra primero?
* Indica el orden en que se expanden los nodos.
* Explicita el estado de la lista abierta en cada paso del algoritmo.
!!!ejercicio:Ej. 20
El grafo que se muestra a continuación representa un esquema de un mapa de carreteras (concretamente, de Rumanía). Los nodos están etiquetados con el nombre de ciudades, y los arcos con la distancia por carretera entre dichas ciudades. La función $h^*$ que se muestra al lado indica la distancia aérea entre cualquier ciudad y la ciudad de B, que es nuestro destino.
Disponemos de un coche eléctrico que permite recorrer 320km sin recargar. Sólo puede recargar en ciudades con estación de recarga pública, los cuales se indican en el mapa por los cuadrados rellenos (ciudades D, F, O, y V). Inicialmente nos encuentramos en la ciudad A con la batería completamente cargada, y deseamos llegar a B por la ruta más corta posible (y sin quedarnos tirados por el camino con la batería vacía). Conocemos la red de carreteras, la posición de las estaciones de recarga, y las características del vehículo, por lo que en cada momento sabemos a qué ciudades vecinas podemos llegar dado el estado de carga de su batería. Aplica la búsqueda A* para resolver el problema.

* Representa el problema como espacio de estados.
* Desarrolla el árbol de búsqueda que genera el algoritmo $A^*$. Indica el orden en el que se expanden los nodos, los valores de $g$, $h^*$ , y $f^*$ de cada nodo del árbol de búsqueda, así como el estado de la lista abierta en cada paso del algoritmo.
* Resuelve el mismo problema pero sin suponer ninguna restricción respecto a la distancia máxiam que puede recorrer el coche sin repostar.
* ¿Es $h^*$ (distancia área entre ciudades) optimista? Justifica la respuesta.
!!!ejercicio: Ej. 21
Aplica de forma detallada el **algoritmo $A^*$** sobre el grafo de estados siguiente para encontrar un camino de peso mínimo de $A$ a $H$ (en cada arista se muestra su peso, y en la tabla se muestra la heurística desde cada nodo hasta $H$).

Para cada paso del algoritmo indica el conjunto de nodos explorados con sus costes y heurísticas, cuáles están abiertos, cerrados, el nodo seleccionado para el siguiente paso, y los caminos parciales que se consideran.
!!!ejercicio:Ej. 22
La figura siguiente muestra el espacio de estados de un cierto problema, donde $a$ es el estado inicial, $z$ el estado final, y las aristas representan las transiciones válidas. Bajo cada nodo se muestra su valor de heurística, $h$, y en cada arista se muestra su coste.

1. ¿Es $h$ admisible? Razona la respuesta.
2. Modifica alguno de los costes de las aristas mostrados en la figura para que $h$ no sea admisible, y explica por qué es así.
3. Cambia $h$ en alguno de los nodos para que la nueva heurística no sea admisible, y explica por qué es así.
4. Aplica de forma detallada el **algoritmo $A^*$** usando los datos de la figura. Indica por pasos el conjunto de nodos explorados explicitando costes totales y heurísticas, cuáles están abiertos, cerrados, y el nodo seleccionado para el siguiente paso. ¿Qué camino sale?, ¿en qué cambia con las modificaciones que has propuesto en los apartados anteriores?
!!!ejercicio:Ej. 23
Aplica de forma detallada el **algoritmo $A^*$** sobre el grafo de estados de la imagen para encontrar un camino de peso mínimo de $a$ a $z$ (bajo cada nodo se muestra una estimación del camino hasta $z$; en cada arista se muestra su peso).

Indica en cada paso el conjunto de nodos explorados con sus costes y heurísticas, cuáles están abiertos, cerrados, y el nodo seleccionado para el siguiente paso.
!!!ejercicio:Ej. 24
Dada la siguiente red $2D$ regular e infinita, donde el estado inicial es $(0, 0)$, el estado final puede ser cualquier punto $(x, y)∈ \mathbb{Z}\times \mathbb{Z}$, y el movimiento entre estados directamente conectados tiene coste 1:

¿Cuáles de las siguientes funciones heurísticas son optimistas? (las definimos para un estado genérico $(u,v)$)
1. $h^∗ ((u, v)) = |u - x| + |v - y|$
2. $h^∗ ((u, v)) = |u - x| * |v - y|$
3. $h^∗ ((u, v)) = 2 * min(|u - x|, |v - y|)$
4. $h^∗ ((u, v)) = |u| + |x| + |v| + |y|$
5. $h^∗ ((u, v)) = \sqrt{(|u - x|^2 + |v - y|^2)}$
!!!ejercicio:Ej. 25
En el espacio de estados que se muestra con el grafo siguiente:

Considerando que $A$ es el estado inicial y $G$ es el objetivo. Los costes de cada arista (que pueden ser atravesadas en ambas direcciones) se muestran en el grafo.
* Demuestra que la heurística $h_1$ es consistente pero la heurística $h_2$ no lo es.
* Para cada uno de los algoritmos de la siguiente tabla, marca cuál (si lo hay) de los caminos señalados podría devolver. Ten en cuenta que para algunas estrategias de búsqueda el camino específico devuelto podría depender del comportamiento de desempate. En tales casos, asegúrate de marcar todos los caminos que podrían ser devueltos bajo algún esquema de desempate.
|Algoritmo | A-B-D-G | A-C-D-G | A-B-C-D-F-G|
|:--------:|---------|---------|------------|
|BFS | | | |
|DFS | | | |
|$A^*(h_1)$| | | |
|$A^*(h_2)$| | | |
* Supongamos que estamos completando la nueva función heurística $h_3$ que se muestra a continuación, donde todos los valores son fijos excepto $h_3(B)$.
|Nodo | A | B | C | D | E | F | G |
|:---:|---|---|---|---|---|---|---|
|$h_3$|$10$| ? |$9$|$7$|$1.5$|$4.5$|$0$|
Para cada una de las siguientes condiciones, escribe el conjunto de valores posibles para $h_3(B)$:
1. ¿Qué valores de $h_3(B)$ hacen que $h_3$ sea admisible?
2. ¿Qué valores de $h_3(B)$ hacen que $h_3$ sea consistente?
3. ¿Qué valores de $h_3(B)$ harán que la búsqueda $A^*$ del grafo expanda el nodo $A$, luego el nodo $C$, luego el nodo $B$, y luego el nodo $D$ en ese orden?
!!!ejercicio:Ej. 26
Para cada una de las siguientes estrategias de búsqueda para el Espacio de Estados representado por el grafo adjunto, calcula el orden en el que se expanden los estados y el camino devuelto por la búsqueda. En todos los casos, los empates se resuelven de manera que los estados con un orden alfabético anterior se expanden primero. El estado inicial y el estado objetivo son $S$ y $G$, respectivamente.

Resuelve el problema por:
* BFS.
* DFS.
* Búsqueda $A^*$ con la heurística $h$.
!!!ejercicio:Ej. 27
El grafo de la figura siguiente muestra el espacio de estados de un hipotético problema de búsqueda. Los estados se indican con letras, y el coste de cada acción se indica en la arista correspondiente. Obsérvese que las acciones no son reversibles, ya que el grafo es dirigido. La tabla que aparece junto al espacio de estados muestra el valor de una función heurística admisible, considerando $G$ como objetivo (comprueba que esta heurística nunca sobreestima el mínimo coste del camino desde cualquier estado hasta $G$).

Considerando $S$ como estado inicial, resuelve el problema de búsqueda anterior utilizando:
* BFS.
* DFS.
* $A^*$ con la heurística anterior.
Al dar el árbol de búsqueda debe indicarse:
- el orden de expansión de cada nodo (por ejemplo, numerando los nodos expandidos según el orden de su expansión),
- la acción correspondiente a cada arista del árbol,
- el estado,
- el coste del camino, y
- el valor de la heurística de cada nodo.
!!!ejercicio:Ej. 28
$A^∗$ es un algoritmo que se usa profusamente en los sistemas de navegación (por ejemplo, para ayudar a la conducción de vehículos), pero habitualmente la búsqueda se orienta por medio de una heurística de mínima distancia, cuando no siempre es lo deseable. Por ejemplo: promocionar rutas turísticas/paisajísticas, facilitar trayectos en los que se producen giros más sencillos, compensar los tiempos de tráfico denso en determinadas zonas, sistemas de transporte multimodal, etc.
Idea y diseña situaciones en las que tenga sentido el uso de heurísticas distintas (o de combinación de heurísticas) en sistemas de recomendación de rutas o en sistemas de navegación automática.
!!!ejercicio:Ej. 29
Representa los problemas de satisfactibilidad, validez (tautología) y consecuencia lógica como problemas de Espacios de Estados y crea las implementaciones necesarias para poder dar hacer uso de los algoritmos de búsqueda vistos en este tema sobre las estructuras vistas en el tema de Lógica.
!!!ejercicio:Ej. 30
Representa los CSP como problemas de Espacios de Estados y crea las implementaciones necesarias para poder dar hacer uso de los algoritmos de búsqueda vistos en este tema sobre las estructuras vistas en el tema de restricciones.
!!!ejercicio:Ej. 31
El objetivo es sacar a un robot de un laberinto. El robot empieza en el centro del laberinto mirando al norte. Puede girar para que mire al norte, este, sur u oeste. Se puede dirigir al robot para que avance una cierta distancia, aunque se detendrá antes de chocar con una pared:
1. Formula el problema. ¿Qué tamaño tiene el espacio de estados?
2. Al navegar por un laberinto, el único lugar en el que necesitamos girar es en la intersección de dos o más pasillos. Reformula este problema usando esta observación. ¿Qué tamaño tiene el espacio de estados ahora?
3. Desde cada punto del laberinto, podemos movernos en cualquiera de las cuatro direcciones hasta llegar a un punto de giro, y esta es la única acción que debemos realizar. Reformula el problema usando estas acciones. ¿Necesitamos realizar un seguimiento de la orientación del robot ahora?
!!!ejercicio:Ej. 32: **Problema de los Caballos**
Consideremos el problema de la colocación de $k$ caballos en un tablero de ajedrez de tamaño $N×N$, de forma que no haya dos caballos atacándose entre sí, donde $k\leq N^2$:
1. Elige una formulación CSP del problema, explicitando variables, dominios y restricciones.
2. Ahora considera el problema de colocar *tantos caballos como sea posible* en el tablero sin ningún ataque. Explica cómo resolver este problema con búsqueda local definiendo las funciones ACCIONES y RESULTADOS apropiadas y una función objetivo sensata.
## PSO
!!!ejercicio:Ej. 1
Tenemos una lista que representa los pesos de una población (todos los pesos están entre $0$ y $100$). Queremos encontrar 3 números ($0 < a_1 < a_2 < a_3 < 100$) que sirvan para dividir el conjunto anterior en 4 secciones: $[0,a_1), [a_1,a_2), [a_2,a_3),[a_3,100)$, de forma que las sumas de los pesos que hay en cada sección sean _lo más parecidas posibles_.
!!!ejercicio:Ej. 2
Disponemos de un CD de $N$ minutos de duración y queremos grabar el mayor tiempo posible de nuestra colección de $M$ canciones. Queremos saber qué pistas debemos grabar.
Las duraciones en minutos de las canciones se dan en una colección \(L=\{d_1,\dots,d_{M}\}\).
Modifica la solución anterior para que, además, obtengamos un CD con el estilo más uniforme posible. El estilo de una canción viene dado por un código numérico. Dos estilos son más parecidos si sus códigos son más cercanos. El estilo de las canciones de nuestra colección viene dado por una colección: \(E=\{e_1,\dots,e_{M}\}\).
!!!ejercicio:Ej. 3: **Problema de emplazamiento de bloques rectangulares**
Dado un conjunto de \(n\) bloques rectangulares de distintas anchuras y alturas (que no se pueden girar y cuyos lados son paralelos a los ejes principales), se trata de encontrar un emplazamiento de los mismos de tal forma que no haya solapamientos entre los bloques rectangulares, y se minimice la función de coste
$$f = A + \lambda C$$
donde \(A\) es el área del rectángulo que engloba todos los bloques rectangulares, \(\lambda\) es una constante positiva y \(C\) un término de conectividad,
$$C =\sum_{i=1}^{n-1}\sum_{j=i+1}^n w_{ij} d_{ij}$$
siendo \(d_{ij}\) la distancia entre los centros de los bloques rectangulares y \(w_{ij}\) el coste relacionado al unir el bloque rectangular \(i\)-ésimo con el bloque rectangular \(j\)-ésimo.
!!!ejercicio:Ej. 4: **Problema de empaquetamiento de esferas**
Aplica el algoritmo de **Optimización por Enjambre de Partículas** (**PSO**) para resolver el problema de empaquetamiento de esferas: El objetivo es encontrar la disposición óptima de $N$ esferas sólidas del mismo tamaño de forma que se puedan meter todas juntas en una caja rectangular del menor volumen posible. Debe tenerse presente que las esferas, a lo sumo, se pueden tocar, pero son sólidas, no pueden cortarse ni deformarse.
Si quieres, puedes comenzar resolviendo el mismo problema para dimensión 2, que se conoce como **problema de empaquetamiento de círculos**.
Considera una variante en la que se parte de una colección de esferas/círculos, cada una con un radio posiblemente distinto.
!!!ejercicio:Ej. 5
Explica cómo usarías un algoritmo de optimización para obtener el polinomio de grado $4$ que mejor aproxima a una función dada. Es decir, concretamente:
Dada $f : [0, 1] → \mathbb{R}$, calcula el polinomio $p(x) = a_0 + a_1x + a_2x^2 + a_3x^3 + a_4x^4$ que mejor aproxima a la función $f$ en el intervalo $[0, 1]$.
Ten en cuenta las siguientes ayudas:
1. Limitamos los coeficientes de $p(x)$ a valores en $[−1, 1]$.
2. La distancia entre $f$ y $p$ se puede calcular como $d(f, p) =\int_0^1 |f(x)−p(x)|dx$, y supondremos que tenemos procedimientos para calcular esta integral.
3. Una forma alternativa de calcular la distancia sería por medio de un muestreo en un conjunto de puntos del dominio y promediando el error que se comete en cada punto (la diferencia entre el valor de $f$ y el de nuestro polinomio).
## Incertidumbre
!!!ejercicio:Ej. 1
Considera el árbol siguiente de un juego de dos personas, donde los círculos son nodos `max` y los cuadrados son nodos `min`.

Aplica el algoritmo **minimax con poda $αβ$**, propaga los valores de evaluación hasta el nodo raíz, marca la mejor jugada para `max`, y marca todos los subárboles que se podan.
!!!ejercicio:Ej. 2
Dos conductores se plantean competir sobre un circuito de ciudades con las siguientes reglas:
1. El recorrido del circuito se hace por tramos, partiendo de la ciudad marcada como `Salida`.
2. Los jugadores, alternativamente, eligen el tramo a recorrer entre aquellos que parten de la ciudad en la que se encuentran. Una vez elegido el tramo, ambos conductores lo recorren y se notan los kilómetros del tramo seleccionado, sin importar quién llega antes a la ciudad de destino. Es decir, si el `conductor1` empieza el recorrido y decide ir a `B`, el `conductor1` se apuntará 30 kilómetros. A continuación el `conductor2` debe elegir, partiendo de `B`, entre ir a `C` o a `D`, y se anota el recorrido que elija.
3. Un conductor no puede ir a una que haya sido visitada anteriormente por ninguno de ellos, por lo que la competición acaba cuando el conductor al que le toca moverse no tiene ciudades a las que moverse.
4. Gana el conductor que haya acumulado más kilómetros con los tramos recorridos.

Se pide:
* Define una representación eficiente para los estados del juego.
* Desarrolla el árbol de búsqueda Minimax con un máximo de dos jugadas para cada jugador (desde el punto de vista del que empieza primero). Genera los sucesores de un nodo en orden alfabético, es decir, el primer sucesor del nodo Salida sería `A` y el segundo `B`.
* Define una función de evaluación adecuada para los nodos hoja, y propaga sus valores a través del árbol. ¿Qué jugada haría el `conductor1`?
* ¿Qué partes del árbol del apartado anterior no se expandirían si se aplicara la poda $αβ$?
!!!ejercicio:Ej. 3
Implementa jugadores automáticos para los siguientes juegos de tablero haciendo uso de MCTS. Para cada uno de ellos:
1. Da una representación formal del juego: estados y movimientos del juego, explicitando estados y movimientos válidos, y cómo se aplican los movimientos sobre los estados.
2. Haz una implementación visual del juego para dos jugadores humanos. Esta implementación debe contemplar la representación formal dada en 1, y las restricciones impuestas por las reglas del juego. Además, debería estar preparada para los pasos siguientes.
3. Haz una implementación de un jugador automático por medio de MCTS.
4. Conecta el jugador automático a la implementación anterior.
Juegos propuestos:
* El juego del **Nim** en su versión más simple: se juega entre 2 jugadores, se tienen 9 cerillas, alternadamente cada jugador puede retirar 1, 2 o 3 cerillas, pierde el que retire la última cerilla.
* El juego del **Nim** en su versión de montones: se juega entre 2 jugadores, se tienen $N$ montones con cerillas, cada jugador alternadamente puede quitar todas las cerillas que quiera, pero solo de un montón, gana el jugador que se lleve la última cerilla.
* El juego del **3 en raya**.
* **Colección de juegos de Tablero**: [conecta4](https://es.wikipedia.org/wiki/Conecta_4), [Go Moku](http://www.ludoteka.com/go-moku.html), [Othello/Reversi](https://brainking.com/es/GameRules?tp=9), [Damas](https://brainking.com/es/GameRules?tp=7), [4 en Línea](https://brainking.com/es/GameRules?tp=13), [Mancala](https://brainking.com/es/GameRules?tp=103), [Ranitas](https://brainking.com/es/GameRules?tp=54), [4 en Línea múltiple](https://brainking.com/es/GameRules?tp=16), [Asimilación](https://brainking.com/es/GameRules?tp=89), [Gran Avance](https://brainking.com/es/GameRules?tp=84), [6 en raya](http://www.ludoteka.com/6-en-raya.html), [9 hombres de Morris](http://www.ludoteka.com/morris.html), [Havannah](http://www.ludoteka.com/havannah.html), [Isolation]("https://en.wikipedia.org/wiki/Isolation_(board_game)").
!!!ejercicio:Ej. 4
Implementa jugadores automáticos para los siguientes juegos de tablero haciendo uso de MCTS para el juego del **Quarto** en su versión simplificada:
Es un juego que se desarrolla en un tablero cuadrado dividido en 16 casillas ($4\times 4$) en el que se enfrentan 2 jugadores. Además se utilizan 16 piezas que combinan las siguientes características dando como resultado de esta combinación todas las variaciones posibles: `Tamaño` (`grande`/`pequeño`), `Color` (`rojo`/`azul`), `Forma` (`cuadrado`/`círculo`), `Agujero` (`pieza con agujero`/`pieza sin agujero`).
El objetivo del juego para cada jugador es intentar terminar por turno una fila de cuatro piezas que tengan en común al menos una de las características descritas (cuatro grandes, cuatro pequeñas, cuatro azules, cuatro rojas, cuatro redondas, cuatro cuadradas, cuatro con agujero o cuatro sin agujero). Las filas pueden ser horizontales, verticales o diagonales. El ganador es el jugador que consigue colocar la cuarta pieza de una de las filas en el tablero en primer lugar.
El juego se desarrolla añadiendo piezas al tablero en turnos alternos de cada uno de los dos contrincantes. En cada uno de sus turnos cada jugador añade una nueva pieza a una casilla del tablero. La pieza añadida al tablero ya no se moverá a lo largo de la partida. Aquí buscamos una versión simplificada, en la que en cada turno el jugador correspondiente decide qué pieza coloca (de entre las piezas libres) y dónde.
Si se colocan las 16 piezas en el tablero sin que ninguno de los dos jugadores consiga el objetivo, la partida termina en empate.
En la versión original del juego, el jugador que incorpora una pieza decide en qué casilla se incorpora, pero no qué pieza se incorpora, ya que el adversario hace la elección concreta de la pieza. Por tanto, el turno de cada jugador consta de dos decisiones:
1. Colocar la pieza indicada por el adversario en el tablero en el turno anterior;
2. Indicar al adversario la pieza que deberá colocar en su siguiente movimiento.
Al principio de la partida, el jugador que tiene el primer turno sólo indica al adversario la pieza que va a colocar en el tablero.
# Aprendizaje Automático
## Datasets
Además de los datasets que se ofrecen aquí, pueden visitarse sitios como:
* [UC Irvine Machine Learning Repository](https://archive.ics.uci.edu/)
* [Google Dataset Search](https://datasetsearch.research.google.com/)
* [Wikipedia ML datasets](https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research)
* [RDatasets](https://vincentarelbundock.github.io/Rdatasets/articles/data.html)
* [OpenML](https://www.openml.org/)
:::tabs
:::tab:MNIST
El dataset de dígitos tiene como objetivo predecir el dígito a partir de una imagen $28\times 28$ del mismo. Se trata de un problema de clasificación multiclase. Se proporcionan dos ficheros CSV, uno de entrenamiento (con $60.000$ muestras), y otro de test (con $10.000$ muestras). Son grandes, así que se proporcionan en versión ZIP. El número de observaciones de cada clase está equilibrado. La primera columna contiene la salida real, mientras que el resto de columnas contienen una versión aplanada de la matriz de pixels.
[Descarga Test 💾](../../Practicas/datasets/mnist_test.zip)
[Descarga Train 💾](../../Practicas/datasets/mnist_train.zip)
:::tab:Vino
El dataset sobre calidad del vino tiene como objetivo en predecir la calidad de los vinos blancos en una escala a partir de medidas químicas de cada vino. Se trata de un problema de clasificación multiclase, aunque también podría plantearse como un problema de regresión. El número de observaciones de cada clase no está equilibrado. Hay $4.898$ observaciones con $11$ variables de entrada y una variable de salida. Los nombres de las variables son los siguientes:
`Acidez fija`, `Acidez volátil`, `Ácido cítrico`, `Azúcar residual`, `Cloruros`, `Dióxido de azufre libre`, `Dióxido de azufre total`, `Densidad`, `pH`, `Sulfatos`, `Alcohol`, `Calidad` (puntuación de $0$ a $10$).
El rendimiento de referencia de la predicción del valor medio es un RMSE de aproximadamente $0,148$ puntos de calidad.
[Descarga 💾](http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv)
:::tab:PIDD
El dataset sobre diabetes de los indios Pima tiene como objetivo predecir la aparición de diabetes en un plazo de 5 años entre los indios Pima a partir de datos médicos. Se trata de un problema de clasificación binaria (2 clases). El número de observaciones para cada clase no está equilibrado. Hay $768$ observaciones con $8$ variables de entrada y $1$ variable de salida. Los valores faltantes se codifican con valores cero. Los nombres de las variables son los siguientes:
`Número de embarazos`, `Concentración plasmática de glucosa a las 2 horas de una prueba oral de tolerancia a la glucosa`, `Presión arterial diastólica` (mm Hg), `Espesor del pliegue cutáneo del tríceps` (mm), `Insulina sérica en 2 horas` (mu U/ml), `Índice de masa corporal` (peso en kg/(altura en m)^2), `Función pedigrí de la diabetes`, `Edad` (años), `Variable de clase` ($0$ ó $1$).
El rendimiento de referencia de la predicción de la clase más prevalente es una precisión de clasificación de aproximadamente el 65%. Los mejores resultados alcanzan una precisión de clasificación de aproximadamente el 77%.
[Descarga 💾](https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv)
:::tab:Sonar
El dataset del sonar tiene como objetivo predecir si un objeto es una mina o una roca en función de la intensidad de los retornos del sonar en distintos ángulos. Se trata de un problema de clasificación binaria (2 clases). El número de observaciones para cada clase no está equilibrado. Hay $208$ observaciones con $60$ variables de entrada y $1$ variable de salida. Los nombres de las variables son los siguientes:
`Retornos del sonar en diferentes ángulos`, ..., `Clase` (`M` para mina y `R` para roca)
El rendimiento de referencia de la predicción de la clase más frecuente es una precisión de clasificación de aproximadamente el 53%. Los mejores resultados alcanzan una precisión de clasificación de aproximadamente el 88%.
[Decarga 💾](https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data)
:::tabs
:::tab:Iris
El dataset de flores de iris tiene como objetivo predecir la especie de flor a partir de mediciones de flores de iris. Se trata de un problema de clasificación multiclase. El número de observaciones para cada clase está equilibrado. Hay $150$ observaciones con $4$ variables de entrada y $1$ variable de salida. Los nombres de las variables son los siguientes (todas las medidas en cm):
`Longitud del sépalo`, `Anchura del sépalo`, `Longitud de los pétalos`, `Anchura de los pétalos`, `Clase` (setosa, versicolor, virginica).
El rendimiento de referencia de la predicción de la clase más prevalente es una precisión de clasificación de aproximadamente el 26%.
[Descarga 💾](../../Practicas/datasets/iris.csv)
:::tab:Abalón
El dataset sobre el abalón (el molusco más caro del mundo, también llamado oreja de mar) tiene como objetivo predecir la edad del abalón a partir de medidas objetivas de los individuos.
Se trata de un problema de clasificación multiclase, pero también puede plantearse como una regresión. El número de observaciones de cada clase no está equilibrado. Hay $4.177$ observaciones con $8$ variables de entrada y $1$ variable de salida. Los nombres de las variables son los siguientes:
`Sexo` (`M`, `F`, `I`), `Longitud`, `Diámetro`, `Altura`, `Peso entero`, `Peso sin cáscara`, `Peso de las vísceras`, `Peso con cáscara`, `Anillos`.
El rendimiento de referencia de la predicción de la clase más prevalente es una precisión de clasificación de aproximadamente el 16%. El rendimiento de referencia de la predicción del valor medio es un RMSE de aproximadamente 3,2 anillos.
[Descarga 💾](http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data)
:::tab:Trigo
El dataset tiene como objetivo la predicción de especies a partir de medidas de semillas de distintas variedades de trigo. Se trata de un problema de clasificación multiclase (3 clases). El número de observaciones de cada clase está equilibrado. Hay $210$ observaciones con $7$ variables de entrada y $1$ variable de salida. Los nombres de las variables son los siguientes:
`Superficie`, `Perímetro`, `Compacidad`, `Longitud del grano`, `Anchura del núcleo`, `Coeficiente de asimetría`, `Longitud del surco del grano`, `Clase` (1, 2, 3).
El rendimiento de referencia de la predicción de la clase más frecuente es una precisión de clasificación de aproximadamente el 28%.
[Descarga 💾](http://archive.ics.uci.edu/ml/machine-learning-databases/00236/seeds_dataset.txt)
:::tab:Housing
El dataset tiene como objetivo predecir el precio de una casa en miles de dólares a partir de datos sobre la casa y su vecindario. Se trata de un problema de regresión. Hay $506$ observaciones con $13$ variables de entrada y $1$ variable de salida. Los nombres de las variables son los siguientes:
* `CRIM`: tasa de delincuencia per cápita por ciudad.
* `ZN`: proporción de suelo residencial zonificado para lotes de más de 25.000 pies cuadrados.
* `INDUS`: proporción de acres comerciales no minoristas por ciudad.
* `CHAS`: variable ficticia Charles River (= 1 si la zona linda con el río; 0 en caso contrario).
* `NOX`: concentración de óxidos nítricos (partes por 10 millones).
* `RM`: número medio de habitaciones por vivienda.
* `AGE`: proporción de unidades ocupadas por sus propietarios construidas antes de 1940.
* `DIS`: distancias ponderadas a cinco centros de empleo de Boston.
* `RAD`: índice de accesibilidad a las autopistas radiales.
* `TAX`: tipo del impuesto sobre bienes inmuebles por cada 10.000 dólares.
* `PTRATIO`: ratio alumnos-profesor por ciudad.
* `B`: 1000(Bk - 0,63)^2 donde Bk es la proporción de negros por ciudad.
* `LSTAT`: % más bajo de la población.
* `MEDV`: valor medio de las viviendas ocupadas por sus propietarios en miles de dólares.
El rendimiento de referencia de la predicción del valor medio es un RMSE de aproximadamente 9,21 mil dólares.
[Descarga 💾](https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.data)
:::tabs
:::tab:ID3
Algunos datasets adicionales que pueden utilizarse, por ejemplo, para clasificación con ID3, son:
| Nombre | Descripción |
|--------|-------------|
| [Examen](../../Practicas/datasets/Examen.csv) | Resultados de un examen |
| [Golf](../../Practicas/datasets/Golf.csv) | Datos sobre golfistas |
| [Lentes de contacto](../../Practicas/datasets/Lentes.csv) | Información sobre lentes de contacto |
| [Presión Arterial](../../Practicas/datasets/Presion.csv) | Datos de presión arterial |
| [Rutina Deportiva](../../Practicas/datasets/Rutina.csv) | Información sobre rutinas deportivas |
| [Coches](../../Practicas/datasets/cars.csv) | Datos sobre coches |
| [Crédito](../../Practicas/datasets/credit.csv) | Información sobre crédito |
| [Golf (con atributos numéricos)](../../Practicas/datasets/GolfNum.csv) | Datos sobre golfistas (numéricos) |
| [Obesidad](../../Practicas/datasets/Obesity.csv) | Datos sobre obesidad |
| [Calidad vino](../../Practicas/datasets/wine.csv) | Datos sobre la calidad del vino |
:::tab:Clustering
Algunos datasets para clusterización:
| Nombre | Descripción |
|--------|-------------|
| [Blobs](../../Practicas/datasets/blob.csv) | Datos sintéticos en forma de blobs |
| [Sonar](../../Practicas/datasets/sonar.csv) | Datos sobre sonar para detección de minas |
O también aquí: [https://cs.joensuu.fi/sipu/datasets/](https://cs.joensuu.fi/sipu/datasets/)
## Utilidades
!!!ejercicio:Ej. 1.
Crea un Dataframe que almacena la siguiente tabla de datos de forma adecuada, y muestra la descripción de la misma (`?` indica un valor faltante) :
~~~~
exam_data = {
Nombre: ['Ana', 'Diana', 'Manuel', 'Jaime', 'Emilia', 'Miguel', 'Mateo', 'Laura', 'Carlos', 'Juan'],
Nota1: [12.5, 9, 16.5, ?, 9, 20, 14.5, ?, 8, 19],
Nota2: [2.5, 3, 19, ?, 3, 10, 1.5, 4, 16, 9],
Intentos: [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
Trabajo: ['sí', 'no', 'sí', ?, 'no', 'sí', 'sí', ?, 'no', 'sí']
Etiquetas: ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
}
~~~~
1. Genera un dataframe derivado que solo contenga las columnas `Nombre` y las `Notas`.
2. Añade una columna con la nota media (decide qué debe hacerse con los datos faltantes).
3. Crea un dataframe con la misma estructura, pero que contenga solo aquellos alumnos que han superado la puntuación de `10` y hayan presentado el trabajo.
4. Crea un dataframe con la misma estructura, pero que contenga únicamente las filas con algún dato faltante.
5. Repite todo lo anterior, pero asignando un valor `0` a las notas faltantes, y `no` a los trabajos faltantes.
6. Calcula la puntuación media de la clase, y el número total, máximo y mínimo de intentos realizados en el curso.
!!!ejercicio:Ej. 2.
A partir del siguiente fichero CSV:
~~~~
ID Nombre Edad Género Salario Objetivo
1,Sara,25,Mujer,50000,0
2,Pedro,30,Hombre,60000,1
3,Luis,22,Hombre,70000,0
4,Fran,35,Hombre,80000,1
5,Carla,?,Mujer,55000,0
6,Carlos,29,Hombre,?,1
7,Ana,31,Mujer,72000,0
8,Lucía,28,?,68000,1
9,Diego,27,Hombre,59000,0
10,Marta,26,Mujer,61000,1
11,Alberto,32,Hombre,75000,0
12,Elena,24,Mujer,53000,1
13,Javier,33,Hombre,82000,0
14,Laura,23,Mujer,48000,1
15,Andrés,34,Hombre,90000,0
16,Sofía,21,Mujer,45000,1
~~~~
1. Carga el CSV (tras haberlo guardado en un fichero) en un dataframe.
2. Muestra las filas con valores faltantes.
3. Sustituye los valores faltantes por la media del grupo.
4. Convierte las variables categóricas en numéricas.
5. Convierte las categóricas en una codificación one-hot.
6. Normaliza los datos numéricos usando el escala min-max.
7. Normaliza los datos numéricos usando $N(0,1)$.
8. Divide el dataset en conjuntos de Training (70%) y Testing (30%).
!!!ejercicio:Ej. 3.
Crea una función, `train_test_split (df, target_col, train_ratio)` que reciba como entrada:
* un dataframe, `df`,
* el nombre de una columna, `target_col`, y
* un `train_ratio` (entre $0$ y $1$)
y devuelva 4 vectores distintos: `Xtrain`, `ytrain`, `Xtest`, `ytest`, que se correspondan con:
* una división aleatoria del dataframe `df` en train/test según el `train_ratio` elegido (por ejemplo, si `train_ratio=0.8` entonces el 80% irán a `train` y el 20% a `test`),
* `ytrain`/`ytest` almacene los valores de la columna `target_col`, y
* `Xtrain`/`Xtest` almacene el resto de columnas de `df`.
Por ejemplo: `train_test_split (df, :Calidad, 0.75)` devolverá los conjuntos de train/test donde la variable objetivo es la columna `Calidad` y se usa un 75% para train y un 25% para test.
!!!ejercicio:Ej. 4.
Crea una función, `normalize_df (df, method)` que reciba como entrada:
* un dataframe, `df`, y
* un `method` que puede tomar los valores `:min-max` o `:z-score`,
y devuelva un nuevo dataframe donde todas las columnas numéricas han sido normalizadas según el método elegido (`:min-max` o `:z-score`). Las columnas no numéricas deben permanecer sin cambios.
!!!ejercicio:Ej. 5.
Crea una función, `categorical_to_numeric (df, method, col)` que reciba como entrada:
* un dataframe, `df`,
* un `method` que puede tomar los valores `:label` o `:one-hot`, y
* una columna `col` (que se supone categórica),
y devuelva un nuevo dataframe donde la columna `col` ha sido convertida a numéricas según el método elegido (*label encoding* o *one-hot encoding*). El resto de las columnas debe permanecer sin cambios.
!!!ejercicio:Ej. 6.
Crea una función, `handle_missing_values (df, method, col)` que reciba como entrada:
* un dataframe, `df`,
* un `method` que puede tomar los valores `:remove` o `:mean`, y
* el nombre de una columna, `col`,
y devuelva un nuevo dataframe donde los valores faltantes de `col` han sido tratados según el método elegido (`:remove` : eliminando las filas con valores faltantes o, `:mean` : sustituyéndolos por la media de la columna correspondiente).
!!!ejercicio:Ej. 7.
Crea una función, `preprocess_dataframe (df, target_col, miss_method, cat_method, norm_method, train_ratio)` que reciba como entrada:
* un dataframe, `df`,
* el nombre de la columna objetivo, `target_col`,
* un `miss_method` que puede tomar los valores `:remove` o `:mean`,
* un `cat_method` que puede tomar los valores `:label` o `:one-hot`,
* un `norm_method` que puede tomar los valores `:min-max` o `:z-score`, y
* un `train_ratio` (entre $0$ y $1$),
y devuelva cuatro conjuntos: `Xtrain`, `ytrain`, `Xtest`, `ytest`, donde:
1. Los valores faltantes en la columna objetivo han sido tratados según el método elegido.
2. Las columnas categóricas han sido convertidas a numéricas según el método elegido.
3. Las columnas numéricas han sido normalizadas según el método elegido.
4. El dataframe ha sido dividido en conjuntos de entrenamiento y prueba según el ratio elegido.
!!!ejercicio:Ej. 8.
Crea una función, `Matriz_Confusion (y_true, y_pred, class_labels)`, que reciba como entrada:
* los valores reales `y_true`,
* los valores predichos `y_pred`, y
* una lista de etiquetas de clase `class_labels`,
y devuelva la matriz de confusión correspondiente.
La matriz de confusión debe ser una tabla donde las filas representen las clases reales y las columnas representen las clases predichas.
Además, la función debe mostrar la matriz de confusión de forma visual (por ejemplo, usando una tabla o un mapa de calor) y calcular las métricas de *accuracy*, *precision*, *recall*, *specifity* y *F1-score* para cada clase (tanto para las matrices con 2 clases como las multiclase).
## KNN
!!!ejercicio:Ej. 1.
Implementa el algoritmo de los **$K$ vecinos más cercanos** (KNN) visto en clase. Implementa la versión ponderada y también alguna versión que pueda usarse para problemas de regresión.
El algoritmo $K$**NN** (**$K$ vecinos más cercanos**) es un método de aprendizaje automático supervisado para clasificación y regresión. Para clasificar un nuevo punto de datos, busca sus $K$ vecinos más cercanos en el conjunto de entrenamiento, basándose en alguna métrica de distancia como la euclidiana, y asigna al nuevo punto la clase que más se repita entre esos $K$ vecinos.
El algoritmo consta de dos fases principales:
* **Fase de entrenamiento**: No tiene.
* **Fase de clasificación**: Cuando se recibe un nuevo punto, $P$, se calcula la distancia entre este y todos los puntos del conjunto de entrenamiento. Se identifican los $K$ puntos de datos más cercanos a $P$, y se determina la clase más frecuente entre esos $K$ vecinos. Se asigna la clase mayoritaria a $P$.
Uso en clasificación vs. regresión:
* **Clasificación**: Se asigna la etiqueta de la clase (quizás ponderada) más frecuente entre los $K$ vecinos.
* **Regresión**: Se calcula el promedio (quizás ponderado) de los valores de los $K$ vecinos más cercanos para predecir el valor del nuevo punto.
Consideraciones importantes:
* **Elección de** $K$: El número de vecinos es un parámetro clave. Un $K$ pequeño puede hacer que el modelo sea sensible al ruido, mientras que un $K$ grande puede llevar a un subajuste. Se suele elegir un valor impar para evitar empates, sobre todo en problemas de clasificación binaria.
* **Normalización de datos**: Es recomendable normalizar o estandarizar los datos antes de aplicar KNN, ya que el algoritmo es sensible a la escala de las características.
* **Métrica de distancia**: La distancia euclidiana es la más común, pero existen otras como Manhattan, Minkowski o Jaccard. La elección de la métrica influye en el resultado. En general, la distancia depende del problema y la representación de los datos.
* **Maldición de la dimensionalidad**: El algoritmo puede no funcionar bien con datos de alta dimensión, ya que la distancia entre los puntos se vuelve menos significativa.
* **Eficiencia**: KNN puede ser computacionalmente costoso para grandes conjuntos de datos, ya que requiere calcular la distancia a todos los puntos de entrenamiento para cada predicción. Se pueden usar estructuras de datos como KD-Trees o Ball Trees para mejorar la eficiencia.
* **Manejo de datos desbalanceados**: En conjuntos de datos con clases desbalanceadas, KNN puede favorecer la clase mayoritaria. Se pueden usar técnicas de ponderación o muestreo para mitigar este problema.
* **Ponderación de vecinos**: En lugar de considerar todos los vecinos por igual, se pueden ponderar sus contribuciones según su distancia al punto de interés, dando más peso a los vecinos más cercanos.
* **Validación cruzada**: Es recomendable usar validación cruzada para seleccionar el mejor valor de $K$ y evaluar el rendimiento del modelo.
* **Interpretabilidad**: KNN es fácil de entender e interpretar, ya que las predicciones se basan en ejemplos concretos del conjunto de entrenamiento.
* **No paramétrico**: KNN no asume ninguna distribución específica de los datos, lo que lo hace flexible para diversos tipos de problemas. Se suele usar como línea base para comparar con otros algoritmos más complejos.
!!!ejercicio:Ej. 2.
Haz un estudio de cómo afecta el valor de $K$ en el algoritmo KNN sobre conjuntos de datos concretos y en casos de multiclasificación, no solo binaria. No olvides reservar algunos datos para el test posterior, y representa la matriz de confusión asociada a los datos.
!!!ejercicio:Ej. 3: **KNN Condensado**
El algoritmo KNN requiere de mucha memoria y tiempo de ejecución porque hay que almacenar permanentemente todos los datos que forman el espacio de ejemplos inicial. Sin embargo, es muy probable que muchas de las muestras iniciales no sean necesarias para clasificar las demás, ya que su información es redundante con otras existentes.
Para reducir este problema existe un preprocesamiento de los datos que se llama **condensación** (observa que depende del orden dado a los datos y, además, tiene el problema de conservar los datos que introducen ruido al sistema):
1. Se comienza dando un orden en los datos de entrada: $\{x_1, x_2, \dots, x_N\}$.
2. Siguiendo el orden anterior, cada ejemplo $x_n$ del conjunto se clasifica por medio de KNN haciendo uso únicamente de los datos anteriores según el orden anterior (es decir, usando $x_1,\dots,x_{n-1}$).
3. Si la clasificación obtenida coincide con la real, $x_n$ se elimina de los datos.
4. Si no, permanece.
Para que tenga sentido, $x_1,\dots, x_K$ se añaden inicialmente al conjunto para poder contar con $K$ vecinos iniciales.
!!!ejercicio:Ej. 4: **Regla de Reducción para KNN**
Es similar a la anterior, pero se comienza con el conjunto completo de datos, y se eliminan aquellos que no afectan a la clasificación del resto de datos de entrada (en contra de la condensación anterior, es capaz de eliminar las muestras que producen ruido, y guarda aquellas que son críticas para la clasificación).
## Árboles de Decisión: ID3
!!!ejercicio:Ej. 1.
Se han encontrado una gran cantidad de obras de arte realizadas por dos artistas A y B, pero solo para un pequeño número de obras se ha podido asegurar cuál de los dos es el autor. La siguiente tabla muestra los datos de dichas obras, indicando el autor en función del tipo de obra (grabado, óleo o acuarela), del lugar donde se encontró la obra (España, Portugal o Francia), de su estilo (clásico o moderno), y de si tienen marco o no.
| Ejemplo | Tipo | Lugar | Estilo | Marco | Autor |
|---------|-------------|---------------|----------------|-------|-------|
| E1 | grabado | España | clásico | no | B |
| E2 | grabado | España | moderno | no | B |
| E3 | grabado | Portugal | moderno | no | B |
| E4 | grabado | Francia | clásico | si | B |
| E5 | grabado | Francia | moderno | no | B |
| E6 | grabado | Francia | moderno | si | B |
| E7 | óleo | España | clásico | si | A |
| E8 | óleo | España | clásico | no | A |
| E9 | óleo | Francia | moderno | no | A |
| E10 | óleo | Portugal | moderno | si | B |
| E11 | óleo | España | moderno | si | B |
| E12 | acuarela | Francia | clásico | no | B |
| E13 | acuarela | España | clásico | si | A |
| E14 | acuarela | Francia | moderno | no | B |
| E15 | acuarela | España | moderno | no | A |
| E16 | acuarela | Portugal | moderno | si | B |
1. Aplica el algoritmo ID3 para encontrar un árbol de decisión consistente con el conjunto de entrenamiento \(\{E_1,\dots , E_{16}\}\) que permita decidir si una obra de arte fue realizada por A o por B.
2. Usa la siguiente tabla de ejemplos como conjunto de prueba para calcular el rendimiento del árbol de decisión obtenido en el apartado anterior
| Ejemplo | Tipo | Lugar | Estilo | Marco | Autor |
|---------|-------------|---------------|----------------|-------|-------|
| E17 | grabado | España | moderno | si | A |
| E18 | óleo | Portugal | moderno | no | A |
| E19 | óleo | Francia | moderno | si | B |
| E20 | óleo | España | moderno | no | A |
| E21 | acuarela | España | clásico | no | A |
| E22 | acuarela | Francia | clásico | si | B |
| E23 | acuarela | España | moderno | si | A |
| E24 | acuarela | Portugal | clásico | si | B |
$\quad$
!!!ejercicio:Ej. 2.
Unos biólogos que exploraban la selva del Amazonas han descubierto una nueva especie de insectos, que bautizaron con el nombre de _lepistos_. Desgraciadamente, han desaparecido y la única información disponible de este insecto viene dada por el siguiente conjunto de ejemplos encontrados en un cuaderno de notas, en los que se clasifican una serie de muestras de individuos en función de ciertos parámetros como su color, el tener alas, su tamaño y su velocidad. Haciendo uso de la tabla, contesta a las siguiente cuestiones:
| EJEMPLO | COLOR | ALAS | TAMAÑO | VELOCIDAD | LEPISTO |
|---------|----------|-----------|---------|-----------|-----------|
| E1 | negro | sí | pequeño | alta | sí |
| E2 | amarillo | no | grande | media | no |
| E3 | amarillo | no | grande | baja | no |
| E4 | blanco | sí | medio | alta | sí |
| E5 | negro | no | medio | alta | no |
| E6 | rojo | sí | pequeño | alta | sí |
| E7 | rojo | sí | pequeño | baja | no |
| E8 | negro | no | medio | media | no |
| E9 | negro | sí | pequeño | media | no |
| E10 | amarillo | sí | grande | media | no |
1. ¿Cuál es la entropía del conjunto de ejemplos respecto a la clasificación de los mismos que realiza el atributo Lepisto?
2. ¿Qué atributo proporciona mayor ganancia de información?
3. Aplicar (detallando cada uno de los pasos realizados) el algoritmo ID3 para encontrar, a partir de este conjunto de entrenamiento, un árbol que nos permita decidir si un determinado individuo es un lepisto o no.
4. Obtener un conjunto de reglas a partir del árbol obtenido en el apartado anterior.
5. Según las reglas obtenidas, ¿hay algún atributo que sea irrelevante para decidir si un individuo es un lepisto?
!!!ejercicio:Ej. 3.
Una entidad bancaria concede un préstamo a un cliente en función de una serie de parámetros: su edad (puede ser joven, mediano o mayor), sus ingresos (altos, medios o bajos), un informe sobre su actividad financiera (que puede ser positivo o negativo) y, finalmente, si tiene otro préstamo a su cargo o no. La siguiente tabla presenta una serie de ejemplos en los que se especifica la concesión o no del préstamo en función de estos parámetros:
| Ejemplo | Edad | Ingresos | Informe | Otro prestamo | Conceder |
|---------|---------|----------|----------|---------------|----------|
| E1 | joven | altos | negativo | no | no |
| E2 | joven | altos | negativo | si | no |
| E3 | mediano | altos | negativo | no | si |
| E4 | mayor | medios | negativo | no | si |
| E5 | mayor | bajos | positivo | no | si |
| E6 | mayor | bajos | positivo | si | no |
| E7 | mediano | bajos | positivo | si | si |
| E8 | joven | medios | negativo | no | no |
| E9 | joven | bajos | positivo | si | si |
| E10 | mayor | medios | positivo | no | si |
| E11 | joven | medios | positivo | si | si |
| E12 | mediano | medios | negativo | si | si |
| E13 | mediano | altos | positivo | no | si |
| E14 | mayor | medios | negativo | si | no |
Supongamos que modificamos el algoritmo ID3 de manera que el criterio para obtener el “mejor” atributo que clasifica un conjunto de ejemplos es el de menor ganancia de información. En esta situación se pide:
1. En caso de ausencia de ruido, ¿obtendría el algoritmo modificado un árbol de decisión consistente con los ejemplos del conjunto de entrenamiento?, justifica la respuesta.
2. ¿Qué sesgo tendría el algoritmo modificado?, justifica la respuesta.
3. Aplica (detallando cada uno de los pasos realizados) el algoritmo modificado para encontrar, a partir de este conjunto de entrenamiento, un árbol que nos permita decidir sobre la concesión de préstamos.
!!!ejercicio:Ej. 4.
Aplica el algoritmo ID3 para construir un árbol de decisión consistente con los ejemplos de la primer tabla que nos ayude a decidir si comprar o no un CD nuevo. Haz uso de los ejemplos de la segunda tabla para obtener una medida de rendimiento del árbol obtenido.
| Ejemplo | Cantante | Discográfica | Género | Precio | Tienda | Comprar |
|---------|-----------|--------------|---------|--------|--------|---------|
| E1 | Queen | Emi | rock | 30 | Mixup | si |
| E2 | Mozart | Emi | clásico | 40 | Virgin | no |
| E3 | Anastacia | Corazón | soul | 20 | Virgin | si |
| E4 | Queen | Sony | rock | 20 | Virgin | si |
| E5 | Anastacia | Corazón | soul | 30 | Mixup | si |
| E6 | Queen | Sony | rock | 30 | Virgin | si |
| E7 | Wagner | Sony | clásico | 30 | Mixup | no |
| E8 | Anastacia | Corazón | soul | 30 | Virgin | no |
| E9 | Queen | Emi | rock | 40 | Virgin | no |
| E10 | Mozart | Sony | clásico | 40 | Mixup | si |
| Ejemplo | Cantante | Discográfica | Género | Precio | Tienda | Comprar |
|---------|-----------|--------------|---------|--------|--------|---------|
| E11 | Queen | Emi | rock | 30 | Virgin | si |
| E12 | Anastacia | Corazón | soul | 20 | Virgin | no |
| E13 | Queen | Sony | rock | 20 | Virgin | no |
| E14 | Anastacia | Corazón | soul | 30 | Virgin | no |
| E15 | Queen | Sony | rock | 40 | Virgin | no |
| E16 | Mozart | Sony | clásico | 40 | Mixup | si |
$\quad$
!!!ejercicio:Ej. 5.
La siguiente tabla muestra ejemplos de plantas, indicando si sobrevivieron más de un año o no después de ser compradas, en función de su tamaño (grande, medio o pequeño), de su ambiente adecuado (interior o exterior), de si tienen flores y de la estación en la que se compró.
Usa la siguiente tabla para aplicar (detallando cada uno de los pasos realizados) el algoritmo ID3 y encontrar un árbol de decisión consistente con el conjunto de entrenamiento \(\{E_1, \dots , E_{16}\}\) que permita decidir si una planta sobrevivirá más de un año o no después de ser comprada. Suponer que se elige para el nodo raíz el atributo tamaño , y continuar la ejecución del algoritmo a partir de ahí.
| Ejemplo | Tamaño | Flores | Ambiente | Estación | Sobrevive |
|---------|---------|--------|----------|-----------------|-----------|
| E1 | grande | si | interior | verano | no |
| E2 | grande | si | interior | verano | no |
| E3 | grande | si | exterior | primavera | no |
| E4 | grande | si | exterior | invierno | no |
| E5 | grande | no | interior | otoño | no |
| E6 | grande | no | exterior | primavera | no |
| E7 | medio | si | interior | verano | si |
| E8 | medio | si | interior | verano | si |
| E9 | medio | no | interior | primavera | si |
| E10 | medio | no | exterior | otoño | no |
| E11 | medio | no | exterior | verano | no |
| E12 | pequeño | si | interior | invierno | no |
| E13 | pequeño | si | exterior | verano | si |
| E14 | pequeño | no | interior | primavera | no |
| E15 | pequeño | no | interior | verano | si |
| E16 | pequeño | no | exterior | otoño | no |
Usa la siguiente tabla para medir el rendimiento del árbol obtenido:
| Ejemplo | Tamaño | Flores | Ambiente | Estación | Sobrevive |
|---------|----------------|--------|----------|-----------------|-----------|
| E17 | grande | no | exterior | verano | no |
| E18 | medio | no | interior | otoño | si |
| E19 | medio | no | exterior | primavera | no |
| E20 | medio | si | exterior | verano | no |
| E21 | pequeño | si | interior | verano | no |
| E22 | pequeño | si | interior | invierno | no |
| E23 | pequeño | no | interior | verano | no |
| E24 | pequeño | no | exterior | otoño | no |
$\quad$
!!!ejercicio:Ej. 6.
Una empresa de material deportivo quiere hacer un estudio de mercado para encontrar las características principales de sus potenciales clientes. En una primera fase, las características a estudiar son las siguientes: la edad (joven o adulto), ser deportista profesional, el nivel de ingresos (altos, medios o bajos) y el sexo. Para ello, se realiza un cuestionario a 21 personas, obteniendo los resultados que se reflejan en la siguiente tabla:
| Ejemplo | Edad | Profesional | Ingresos | Sexo | Interesado |
|---------|--------|-------------|----------|--------|------------|
| E1 | joven | si | bajos | hombre | si |
| E2 | joven | si | altos | hombre | si |
| E3 | joven | no | altos | mujer | no |
| E4 | joven | si | bajos | mujer | si |
| E5 | joven | no | medios | mujer | no |
| E6 | adulto | si | altos | hombre | no |
| E7 | adulto | no | altos | mujer | no |
| E8 | adulto | si | altos | mujer | no |
| E9 | adulto | no | medios | mujer | no |
| E10 | adulto | si | bajos | mujer | no |
| E11 | adulto | no | medios | mujer | no |
| E12 | adulto | si | medios | hombre | no |
| E13 | adulto | no | altos | hombre | si |
| E14 | joven | si | altos | mujer | si |
| E15 | joven | si | medios | hombre | si |
| E16 | adulto | no | medios | hombre | no |
| E17 | adulto | no | bajos | hombre | no |
| E18 | joven | no | medios | hombre | no |
| E19 | joven | no | bajos | mujer | no |
| E20 | adulto | si | medios | mujer | no |
| E21 | joven | si | medios | mujer | si |
1. Aplica el algoritmo ID3 para obtener un árbol de decisión que sirva para decidir si un cliente potencial está interesado o no en el producto que ofrece la empresa. Tomar como conjunto de entrenamiento los primeros 15 ejemplos de la tabla.
2. Tomando ahora como conjunto de prueba los ejemplos del 16 al 21 de la tabla, calcula el rendimiento del árbol de decisión obtenido en el apartado anterior. Usando ese conjunto de prueba, aplica un proceso de podado a posteriori sobre el árbol de decisión. Expresa mediante reglas el árbol obtenido tras la poda ¿Qué rendimiento tiene este árbol sobre el conjunto de prueba? ¿Y sobre el conjunto de entrenamiento?
## Redes Neuronales
!!!ejercicio:Ej. 1.
Genera y entrena redes neuronales adecuadas para aproximar las siguientes funciones. En las que puedas, haz una representación gráfica comparada de la función y de la aproximación obtenida:
1. $f_1: [-1,1] → ℝ,\ x \mapsto x^2$.
2. $f_2: [-1,1] → ℝ,\ x \mapsto 1 + \log(x^2 + 1)$.
3. $f_3: [-1,1]^2 → ℝ,\ (x,y) \mapsto x^2 + y^2$.
4. $f_4: [-1,1]^2 → ℝ^2,\ (x,y) \mapsto (x^2+y^2, e^y-e^x)$.
5. $f_5: [-2,2] → ℝ,\ x\mapsto \begin{cases} 1, & \text{ si } x ∈ [0,1]\\ 0,& \text{ e.o.c} \end{cases}$.
!!!ejercicio:Ej. 2.
Usa el dataset [`MASS/Crabs`](../../Practicas/datasets/crabs.csv) para:
1. Predecir el sexo del individuo a partir del resto de datos.
2. Predecir el tipo y sexo a partir del resto de datos.
3. Predecir alguna variable numérica a partir del resto de datos.
!!!ejercicio:Ej. 3.
Usa el dataset [`Datasets/iris`](../../Practicas/datasets/iris.csv) para:
1. Modifica la columna `Specie` para convertirla en una codificación one-hot.
2. Predice este valor a partir de las dimensiones del individuo.
!!!ejercicio:Ej. 4.
Crea redes Neuronales que calculen las siguientes funciones binarias:
1. Mayoría: recibe una entrada de \(n\) bits ($n$ impar), y devuelve \(1\) si hay mayoría de \(1's\) y \(0\) en caso contrario.
2. Paridad: recibe una entrada de \(n\) bits, y devuelve \(1\) si hay una cantidad par de \(1's\) y \(0\) en caso contrario.
Para ello, crea los datasets de entrenamiento y test correspondientes para distintos valores de $n$. Prueba distintas arquitecturas y métodos de entrenamiento para conseguir buenos resultados.
!!!ejercicio:Ej. 5.
Explora los datasets presentes en [Datasets](#Datasets) y practica con algunos de ellos tareas similares a las que se han hecho en los ejercicios anteriores.
!!!ejercicio:Ej. 6.
Detalla algún procedimiento por el que podrías usar **Templado Simulado** (o **PSO**) para entrenar una red nueronal. Impleméntalo y pruébalo con redes pequeñas que aproximen datos de baja dimensionalidad.
!!!ejercicio:Ej. 7. Aprendizaje de la Representación
Vamos a usar las Redes Neuronales como un método para **Aprendizaje de la Representación**.
Para ello, usaremos únicamente las entradas del dataset (no la clasificación), y vamos a entrenar una red que calcule la función identidad sobre estos datos (es decir, la red debe aprender a devolver el mismo vector que ha recibido como entrada).
El objetivo habitual del Aprendizaje de la Representación es obtener una representación vectorial de los datos de entrada con una dimensionalidad distinta (normalmente, más baja, pero no es obligatorio) y que sean útiles como representantes de los datos originales (esa utilidad viene dada por el uso que se vaya a hacer posteriormente).
Una forma común para ello es usar una red simétrica que use en su capa media un número inferior de neuronas que en la entrada. Por ejemplo, si la entrada tiene dimensión $n$, podemos interpretar que una red $[n,k,n]$ que sea capaz de calcular la identidad ha conseguido almacenar en la capa intermedia la información que necesita para recuperar todo el dato original (de $n$ dimensiones), pero usando $k$ dimensiones (si $k\leq n$ entonces la red ha sido capaz de comprimir la información).
En las redes Feed Forward, cada capa mantiene la información importante del dato de entrada para obtener la salida. En el caso de la identidad, la información de la capa intermedia es capaz de reconstruir la entrada completa.
Vamos a realizar este experimento con el dataset `iris`:
1. Crea una red simétrica `[4,10,2,10,4]` y entrénala para que calcule la identidad sobre los datos de entrada del dataset `iris`.
2. Divide la red en dos subredes: `cod` y `decod`, donde `cod` es la subred que va desde la entrada hasta la capa intermedia (en nuestro ejemplo, de 2 neuronas), y `decod` es la subred que va desde la capa intermedia hasta la salida. Comprueba que la composición de ambas subredes es la red original.
3. Usa la subred `cod` para obtener una representación en $\mathbb{R}^2$ de los datos de entrada. Vamos a hacer una representación gráfica (de tipo scatter, de puntos) de una codificación en $\mathbb{R}^2$ del dataset `Iris`. Para ver si tiene sentido, vamos a aprovechar la clase de cada muestra como color, asi comprobaremos visualmente si hay una correspondencia entre la representación aprendida y la clase asociada.
**Nota**:
1. Observa que para cada ejecución del proceso anterior se genera una codificación distinta, y podría haber aprendizajes que no proporcionasen representaciones interesantes.
2. Si usamos para la codificación la red que calcula la identidad, no es obligatorio que haya una relación entre la codificación obtenida y la salida esperada en otras tareas, ya que son tareas independientes. Pero podemos hacer lo mismo con una red específica para esa tarea.
## Clustering
!!!ejercicio:Ej. 1. K-Medias
Vamos a implementar y probar el algoritmo **K-medias** a partir de algunas tareas predefinidas básicas:
**Tarea 1: Distancias**
Define las siguientes funciones:
1. `centroide(D)`: recibe una colección de vectores de la misma dimensión, y
devuelve el punto medio (centroide) de ellos.
2. `eucl(p₁, p₂)`: recibe 2 vectores de la misma dimensión, y devuelve la
distancia euclídea entre ellos. Define también `eucl2`, que es el cuadrado
de la distancia.
3. `manh(p₁, p₂)`: recibe 2 vectores de la misma dimensión, y devuelve la
distancia de manhattan entre ellos.
Y pruébalos sobre vectores de distinta dimensión para comproar que funcionan correctamente.
**Tarea 2: K-Medias**
Define la función `k_medias` que recibe:
* `D` : Vector de puntos de muestra.
* `K` : Número de clusters a buscar.
* `T` : Número de pasos a ejecutar del algoritmo (por defecto, $100$).
* `dist`: distancia que se usará en `D` (por defecto, la distancia euclídea al cuadrado).
Y devuelve un par `(Cls, Cs)`, donde:
1. `Cs = [c₁, ..., cₖ]` es un vector de los `K` centroides para los clusters.
2. `Cls` es la colección de `K` clusters asociados a los centroides de `C`.
Una solución es asignar a cada `1 ≤ i ≤ K` el vector de índices de `D` que forman el cluster de `cᵢ`. Es decir, si `cᵢ = {D[j₁], ..., D[jₙ]}`, entonces en el diccionario se asocia la clave `i` con el conjunto de índices `[j₁, ..., jₙ]`.
**Tarea 3: Función Potencial**
Define una función `potencial(D, Cls, Cs, dist)` que calcule el potencial del conjunto `D` para el clustering `(Cls, Cs)` haciendo uso de la distancia `dist`.
**Función Potencial**: Se recuerda que si tenemos una partición de `D` en clusters `C₁, ..., Cₖ`, donde `cᵢ` es el centroide de `Cᵢ`, entonces la función potencial es: $$\sum_{i=1}^{k} \sum_{x \in C_i} d(x, c_i)^2$$
[Partición: `D = C₁ ⋃ ... ⋃ Cₖ`, y si `i ≠ j` entonces `Cᵢ ∩ Cⱼ=∅`]
**Tarea 4: Método del codo**
Usando las funciones definidas en las tareas anteriores, vamos a dar un procedimiento (no muy bueno) para decidir el número de clusters que podríamos considerar adecuado para un conjunto de datos. Para ello:
Crea una función que reciba como entrada `D` y calcule para cada valor de `K` (`1 ≤ K ≤ |D|`) el potencial de una clusterización de `D` por medio de K-medias. Como el algoritmo de K-medias puede dar distintos resultados dependiendo de la elección inicial de centroides, puede ser interesante que esta función no haga una sola ejecución para cada valor de `K`, sino unas cuantas y se quede con la media de los potenciales obtenidos.
Antes de continuar, intenta responder a las siguientes cuestiones de forma razonada:
1. ¿Cuánto vale el potencial si `K=|D|`?
2. ¿Qué puedes decir del comportamiento respecto a `K` (crece, decrece,...)?
Representa los de valores del potencial respecto a `K` para ver el comportamiento de la evolución del número de clusters.
!!!ejercicio:Ej. 2. DBSCAN
A continuación se define la función `dbscan(D, ϵ, min_pts, dist)` que aplica el algoritmo **DBSCAN** sobre el conjunto de datos `D`, usando `dist` como función de distancia, `ϵ` como tamaño de los entornos a comprobar, y `min_pts` como número de puntos mínimo para que un elemento no esté aislado.
!!!ejercicio:Ej. 3. AGNES
En las siguientes tareas vamos a dar una implementación del algoritmo de Clustering Jerárquico **AGNES**. Para ello, vamos a partir de un conjunto de datos indexado, `D` (todos como vectores de un mismo espacio vectorial), y vamos a trabajar con los clusteres como conjuntos (colecciones) de índices (de los elementos que contienen de `D`).
**Tarea 1: Distancia entre clusters**
Define la función `d_cl(C₁, C₂, D)` que recibe una colección de vectores de la misma dimensión, `D`, y una función de distancia, `d`, y devuelve la distancia entre los clusters `C₁` y `C₂`.
Recuersa que se pueden introducir variantes en este algoritmo cambiando la forma de medir la distancia entre clusters. Es lo que se conoce como *Métodos de Conexión*: supuesto que tenemos una distancia, `d`, definida en `D`, las distancias entre clusters más habituales son:
* Conexión completa: `d_max(C₁,C₂) = max{d(x₁,x₂): x₁ ∈ C₁, x₂ ∈ C₂}`
* Conexión simple: `d_min(C₁,C₂) = min{d(x₁,x₂): x₁ ∈ C₁, x₂ ∈ C₂}`
* Conexión media: `d_mean(C₁,C₂) = mean{d(x₁,x₂): x₁ ∈ C₁, x₂ ∈ C₂}`
* Conexión centroide: `d_cent(C₁,C₂) = d(c₁,c₂)`, donde `cᵢ = centroide(Cᵢ)`
**Tarea 2: Algoritmo AGNES**
Haciendo uso de la Tarea 1, define la función `agnes(D, K)` que ejecuta el algoritmo AGNES sobre `D` hasta quedarse con `K` clusters.
Se proporciona una función, `remove(a, item)` que elimina todas las apariciones del elemento `item` de la colección `a`:
```julia
# Elimina item de la colección a
function remove!(a, item)
deleteat!(a, findall(x -> x == item, a))
end
```
!!!ejercicio:Ej. 4.
Utiliza algún algoritmo de Clustering para rebajar adecuadamente el número de colores que se usa en una imagen. Para ello, ten en cuenta que una imagen es un conjunto de pixels (en forma de matriz), cada uno con un color RGB. ¿Se te ocurre alguna forma de restringir la paleta de colores original (no solo el número de colores)?
!!!ejercicio:Ej. 5.
Idea un sistema en el que un algoritmo de clustering podría usarse para agrupar imágenes por similaridad en su contenido.
!!!ejercicio:Ej. 6.
Idea un sistema en el que un algoritmo de clustering podría usarse para agrupar textos cortos por similaridad en su contenido.
!!!ejercicio:Ej. 7.
Considera el siguiente conjunto de entrenamiento sin la columna de clasificación y tomando $m_1 = (1, 1, -1)$ y $m_2 = (0, -1, 1)$, aplica el algoritmo de k-medias para $k=2$ con $m_1$ y $m_2$ como centros iniciales hasta la primera modificación de los centros.
| Ej | Atr1. | Atr2. | Atr3. |
|-------|-------|-------|-------|
| $E_1$ | $1$ | $1$ | $0$ |
| $E_2$ | $1$ | $0$ | $0$ |
| $E_3$ | $1$ | $0$ | $1$ |
| $E_4$ | $0$ | $0$ | $1$ |
$\quad$
!!!ejercicio:Ej. 8.
Considera los puntos $P_1 = (0, 48)$, $P_2 = (0, 78)$, $P_3 = (36, 126)$, $P_4 = (36, 0)$ y los centros $m_1 = (20, 63)$ y $m_2 = (36, 63)$. Se pide aplicar algún algoritmo de Clusetring usando la distancia euclídea sobre los puntos $P_1, \dots, P_4$ tomando $m_1$ y $m_2$ como centros iniciales ($k = 2$) hasta la primera modificación de los centros.
!!!ejercicio:Ej. 9.
Haciendo uso de la siguiente matriz de distancias entre los puntos del dataset:
| | A | B | C | D | E | F | G |
|--------|--------|----------|----------|----------|----------|--------|--------|
| A | $0$ | | | | | | |
| B | $2'15$ | $0$ | | | | | |
| C | $0'7$ | $1'53$ | $0$ | | | | |
| D | $1'07$ | $1'14$ | $0'43$ | $0$ | | | |
| E | $0'85$ | $1'38$ | $0'21$ | $0'29$ | $0$ | | |
| F | $1'16$ | $1'01$ | $0'55$ | $0'22$ | $0'41$ | $0$ | |
| G | $1'56$ | $2'83$ | $1'86$ | $2'04$ | $2'02$ | $2'05$ | $0$ |
Aplica el método AGNES para obtener la jerarquía de clusters asociados usando alguna de las distancias habituales.
!!!ejercicio:Ej. 10.
1. Usa el conjunto `Iris` para comprobar si alguno de los métodos anteriores hace una clusterización de los datos (en 3 clusters de puntos de dimensión 4) que sea coherente con la clasificación de los mismos, es decir, que los clusters encontrados coincidan con las especies de las flores.
2. Como sabes, `Iris` usa 4 medidas para cada muestra de flor (`sl`, `sw`, `pl` y `pw)`, dos de ellas para las dimensiones de los sépalos y dos para los pétalos. Encuentra para cada una de las 4 variables una clusterización (con el número de clusters que consideres adecuado) que discretice el dataset, pasando de un conjunto de muestras con 4 valores continuos a uno de muestras con 4 valores discretos (para cada medida, se sustituye el valor continuo por el cluster al que pertenece). Usa algún algoritmo de clasificación para comprobar si estas discretizaciones son coherentes con la clasificación de las flores. ¿Podrías decir si esta metodología se parece en algo al funcionamiento de ID3 con datos continuos?
5. Repite el punto 2 pero clusterizando bidimensionalmente, es decir, encontrar un clustering para las dimensiones de los sépalos, y otro para los pétalos. De esta forma, en vez de trabajar con 4 dimensiones continuas convertidas en 4 dimensiones discretas, pasamos a 2 dimensiones discretas. ¿Y en este caso, se parece al funcionamiento de ID3 con datos continuos?