**LITI**
Sintaxis y Semántica de la Lógica Proposicional
Como hemos visto en los temas introductorios, a lo largo del tiempo ha habido diversas aproximaciones que persiguen formalizar tanto el conocimiento como los métodos para obtener nuevas verdades de forma deductiva. En este sentido, nosotros vamos a considerar a lo largo de este curso un problema que aúna estos esfuerzos dentro de lo que consideraremos _el problema central de la deducción_, y que se puede expresar como sigue:
!!!def
Dado un conjunto de asertos (afirmaciones que conforman nuestro conocimiento en un determinado ámbito), que denotaremos por $\mathcal{BC}$ (por _Base de Conocimiento_), y una afirmación adicional, $\mathcal{A}$, el problema central que queremos abordar es el de decidir si $\mathcal{A}$ ha de ser necesariamente cierta supuesto que son ciertas todas las afirmaciones de $\mathcal{BC}$.
Si queremos tener la seguridad de que planteamos adecuadamente el problema anterior, es necesario disponer de una serie de elementos básicos que nos permitan descomponer el problema de una forma más abordable. Concretamente, necesitaremos:
* Un lenguaje que permita expresar de manera formal y precisa las afirmaciones, hechos e hipótesis. La definición de este lenguaje requerirá de dos elementos adicionales:
1. Un conjunto de reglas que establezcan si las expresiones usadas tienes la forma correcta. Estas reglas constituyen lo que se denomina la **Sintaxis** del lenguaje.
2. Una definición clara de qué se considera una _afirmación cierta_ o _verdadera_. Las reglas que establecen la veracidad de las expresiones que usemos forman lo que se denomina la **Semántica** del lenguaje.
* Necesitaremos, además, un conjunto de mecanismos o procedimientos que decidan si las deducciones que nos interesan se tienen o no. Dichos mecanismos ha de ser _efectivos_ (es decir, secuencias de pasos repetibles y deterministas que siempre devuelven los mismos valores de salida para los mismos valores de entrada) y, en la medida de lo posible, _eficientes_ (es decir, no utilizar demasiados recursos para responder). Normalmente exigiremos que estos procedimientos sean _correctos_ (es decir, no devuelven resultados erróneos) y, cuando sea posible, también _completos_ (es decir, siempre devuelven una respuesta). Estos mecanismos los daremos por medio de los denominados **Algoritmos de decisión**.
A lo largo de los siguientes capítulos abordaremos estos puntos para las dos lógicas más comunes y que son la base (de alguna forma más o menos directa) de la mayoría de las lógicas existentes: la **Lógica Proposicional** (_LP_) y la **Lógica de Primer Orden** (_LPO_).
Nuestro objetivo central en este primer capítulo será presentar los dos primeros aspectos del lenguaje para estás lógicas (su Sintaxis y Semántica). De forma natural ello nos permitirá dar algunas (interesantes) pinceladas sobre el tercero de los elementos, los Mecanismos o procedimientos. Pero serán los siguientes capítulos los que se dedicaremos, casi en su totalidad, al desarrollo de las herramientas que facilitan el camino hacia las soluciones que presentaremos para el problema central anterior.
# Fundamentos de Lógica Proposicional
En esta primera sección vamos a abordar desde un punto de vista teórico-práctico, los elementos básicos que componen la Sintaxis y la Semántica de la Lógica Proposicional.
La Lógica Proposicional comienza a desarrollarse en la Grecia antigua y, aunque su formalización puede haber variado a lo largo de los siglos para acondicionarla a los nuevos tiempos y facilitar su escritura, se sigue usando esencialmente el mismo esquema sintáctico y bajo los mismos parámetros. Es la lógica más simple que podemos considerar por lo que ofrece unos elementos más rígidos que otras aproximaciones y, por tanto, una menor capacidad expresiva. Esta es la razón por la que ha sufrido ampliaciones sucesivas a lo largo del tiempo que han tenido como objetivo aplicar la lógica a problemas más complejos (la Lógica de Primer Orden que veremos después es realmente una ampliación de LP, aunque no la única posible). Pero no todo es negativo en esta primera aproximación ya que, gracias a ello, la LP presenta características que la hacen especialmente adecuada para su implementación computacional directa, disponiendo, como veremos a lo largo del curso, de herramientas completas para su manipulación.
Informalmente, las características más importantes que definen a la Lógica Proposicional son:
* Sus expresiones (denominadas _fórmulas proposicionales_ o _proposiciones_) modelan afirmaciones que pueden considerarse _ciertas_ o _falsas_. No hay posibles estados intermedios, ni distintos, ni solapables, cada afirmación del lenguaje tiene una, y sólo una, de esas dos opciones.
* Estas fórmulas proposicionales (en adelante fórmulas, si no existe ambigüedad) se construyen mediante un conjunto de expresiones básicas (_fórmulas atómicas_ o _átomos_) y un conjunto de operadores (_conectivas lógicas_). Las conectivas disponibles permiten modelar los siguientes tipos de afirmaciones:
* _Conjunción_: ‘... tal ... Y ... cual ...’
* _Disyunción_: ‘... tal ... O ... cual ...’
* _Implicación_: ‘SI tal ... ENTONCES ... cual ...’
* _Equivalencia_: ‘... tal ... SI Y SÓLO SI ... cual ...’
* _Negación_: ‘NO es cierto tal ...’
Profundizaremos en este aspecto en la próxima sección, cuando presentemos la _Sintaxis Formal de la LP_.
* El lenguaje sólo permite modelar este tipo de afirmaciones, por lo que muchas veces puede ser difícil (o imposible) representar algunos problemas en LP, y será necesario recurrir a otras opciones más expresivas (como la propia _LPO_, o las conocidas como _Lógicas Modales_, _Lógica Difusa_, etc.). Más adelante veremos limitaciones específicas que nos servirán para justificar la ampliación que aporta la LPO.
* Aunque esta Lógica puede resultar de una aparente sencillez, veremos que en ella ya aparecen ciertos retos que (como el problema _SAT_) caen dentro de la categoría de problemas **NP**-completos, esto es, problemas complejos para los que no se conocen algoritmos eficientes para resolverlos. Trataremos de nuevo este aspecto cuando introduzcamos formalmente los algoritmos de decisión.
# Sintaxis de la Lógica Proposicional
## El Alfabeto Proposicional
Un _alfabeto_ hace referencia al conjunto de símbolos que forman parte de un lenguaje y que se pueden combinar para construir las distintas expresiones permitidas (como las letras que permiten construir palabras).
!!!def: Sintaxis de la Lógica Proposicional
En el alfabeto de LP podemos distinguir las siguientes categorías de símbolos:
* **Variables Proposicionales**. Ya hemos señalado previamente que todo problema está representado por relaciones entre un conjunto finito de afirmaciones básicas. En LP estas afirmaciones se representan con variables proposicionales que podemos seleccionar de un conjunto infinito prefijado: $VP = \{p, q, r, s, \dots, p _0, p _1, \ldots, q _0, q _1, \dots \}$.
* **Conectivas Lógicas**. Modelan las relaciones entre las distintas afirmaciones básicas (variables). Según el número de operandos sobre los que actúan (que se denomina _aridad_), podemos distinguir:
* De aridad 1 (o _unaria_) : _Negación_ ($\neg$).
* De aridad 2 (o _binarias_): _Conjunción_ ($\wedge$), _Disyunción_ ($\vee$), _Condicional_ ($\rightarrow$), _Bicondicional_ ($\leftrightarrow$).
* **Símbolos Auxiliares**: Solo consideraremos dos símbolos auxiliares: los paréntesis ‘$($’ y ‘$)$’. Permiten expresar relaciones de prioridad entre conectivas lógicas y evitar ambigüedad en la interpretación de las fórmulas.
## Fórmulas Proposicionales
En todos los lenguajes formales una **expresión** es una sucesión finita (y no vacía) de símbolos del lenguaje.
Así, por ejemplo, si consideramos las expresiones que admite una calculadora numérica, podríamos considerar expresiones como "$3+(4 \times 5)$" o "$+ \times3)4$". Ambas son expresiones, sin embargo, la primera de ellas la consideramos bien formada mientras que la segunda no (en una calculadora, se traduce en que la primera devuelve un resultado, mientras que la segunda produce, como mucho, un mensaje de error en la pantalla).
Algo similar ocurre en el lenguaje de LP, tanto "$a \rightarrow b )ca \vee$" como "$(a \rightarrow b ) \vee c$" son expresiones del lenguaje. Sin embargo, parece claro que la segunda de ellas muestra “una coherencia” que no tiene la primera, por lo que no todas las expresiones posibles son de utilidad. De esta forma, a las expresiones "bien formadas", aquellas que muestran una coherencia informativa que podemos utilizar, las denominaremos **fórmulas proposicionales**. En principio, puede bastar con la intuición acerca de qué fórmulas nos parecen correctas y cuáles no, pero si queremos hacer un tratamiento automático (computacional) de la lógica, hemos de dar algún procedimiento efectivo que permita diferenciar formalmente las expresiones bien formadas de las que no lo son, así que podemos definir:
!!!def:Fórmulas Proposicionales
Formalmente, el conjunto de las fórmulas proposicionales, $PROP$, es el menor conjunto de expresiones construidas usando el alfabeto LP que verifica:
* $VP \subseteq PROP$ (es decir, las variables proposicionales aisladas son expresiones correctas del lenguaje).
* Es cerrado bajo las conectivas lógicas, es decir:
* Si una fórmula $F \in PROP$, entonces $\neg F \in PROP$.
* Si las fórmulas $F, G \in PROP$, entonces $(F \wedge G)$, $(F \vee G)$, $(F \rightarrow G)$, $(F \leftrightarrow G) \in PROP$.
Aunque esta definición puede resultar, a primera vista, un poco oscura, ofrece una vía constructiva para diferenciar las expresiones bien formadas de las que no lo son (en particular, en este caso ofrece una definición recursiva): partiendo de las fórmulas bien construidas más pequeñas posibles, las variables proposicionales, podemos construir nuevas fórmulas bien formadas, más grandes, aplicando conectivas sobre una o dos fórmulas bien formadas más pequeñas (serán una o dos dependiendo de la aridad de la conectiva utilizada).
Observemos que, si usamos conectivas binarias, entonces la expresión resultante debe estar enmarcada por paréntesis... pero no es así en el caso de usar la negación (la única conectiva unaria).
### Árboles de formación
Así pues, cada fórmula proposicional se construye poco a poco a partir de formulas más simples. Siguiendo los pasos de su construcción, cada fórmula se puede asociar a un grafo de tipo árbol (esencialmente único, salvo diferencias de orden), que muestra el proceso de formación de la fórmula.
Por ejemplo, la fórmula $\neg( \neg(p \vee q) \rightarrow ( \neg r \wedge s))$ tiene asociada el **árbol de formación** siguiente:
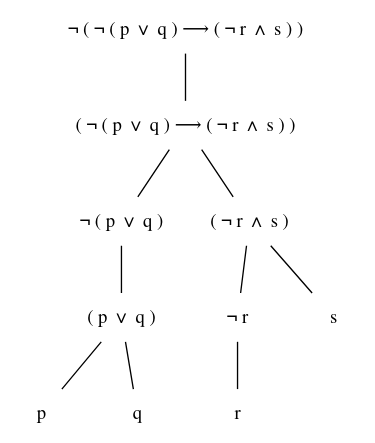
De abajo a arriba, el árbol nos muestra, paso a paso, cómo obtener la fórmula que hay en su raíz partiendo de las variables proposicionales $p$, $q$, $r$ y $s$ que aparecen en sus hojas y las correspondientes conectivas lógicas. De arriba a abajo, el árbol nos muestra cómo descomponer la fórmula en otras más simples, a partir de las cuales ha sido construida mediante las conectivas. Las distintas fórmulas que aparecen en los nodos del árbol de formación de una fórmula $F$ se denominan **subfórmulas** de $F$.
### Simplificación de las expresiones
Para facilitar la escritura y lectura de las fórmulas podemos adoptar algunos criterios adicionales que permitirán simplificar su expresión reduciendo el número de paréntesis que se usan en su representación formal. Para ello:
1. Omitimos los paréntesis más exteriores de la fórmula. Por ejemplo, $F \vee G$ es una representación simplificada de $(F \vee G)$.
2. Tomaremos como orden de precedencia de las conectivas (de mayor a menor precedencia) el siguiente: $\neg$, $\wedge$, $\vee$, $\rightarrow$ y $\leftrightarrow$. Aplicando esta precedencia podemos eliminar paréntesis interiores. Por ejemplo, $F \wedge G \rightarrow H$ es una representación alternativa de $((F \wedge G) \rightarrow H)$. Para la conectiva $\leftrightarrow$ se recomienda mantener los paréntesis en todos los casos.
3. Cuando una conectiva se usa repetidamente, se asocia por la derecha. Por ejemplo, $F _1 \wedge F _2 \wedge F _3$ es una representación alternativa de $(F _1 \wedge (F _2 \wedge F _3))$.
Es importante tener en cuenta que estas reglas solo serán tenidas en cuenta para facilitar nuestra escritura _manual_, pero formalmente no modificamos la definición que hemos dado de las fórmulas proposicionales y, en realidad, las fórmulas bien formadas tendrán tantos paréntesis como formalmente deban llevar.
### Principio de Inducción sobre fórmulas
Gracias a la definición de $PROP$ (y su estructura recursiva), para probar que toda fórmula proposicional satisface una cierta propiedad ($ \Psi$), podemos usar el **Principio de Inducción sobre fórmulas**.
Este principio de inducción es similar al que se tiene para los números naturales y que aprovecha la estructura constructiva que éstos tienen: para construir un número natural cualquiera solo es necesario considerar un símbolo inicial, el $0$, y una única operación constructiva, que podríamos expresar como $+1$, de forma que cualquier número se puede construir a partir de $0$ aplicando tantas veces como sea necesario la operación de sumar $1$.
Así, el **Principio de Inducción en $\mathbb{N}$** dice:
!!!note: Principio de Inducción
Si tenemos una propiedad, $\Psi$, verificando:
1. _Caso Base_: se verifica $\Psi(0)$ (es decir, $0$ verifica la propiedad $\Psi$).
2. _Paso inductivo_: Para cualquier natural, $n$, si se verifica $\Psi(n)$ entonces se verifica $\Psi(n+1)$ (que en un lenguaje matemático podríamos escribir como: $\forall n \in \mathbb{N} \ ( \Psi(n) \rightarrow \Psi(n+1))$).
Entonces, podemos afirmar que para todos los números naturales se verifica $\Psi$ (que, de nuevo usando un lenguaje matemático, podríamos escribir como: $\forall n \in \mathbb{N} ( \Psi(n))$).
De forma análoga podemos dar un **Principio de Inducción en $PROP$**, que diría:
!!!note:Principio de Inducción en $PROP$
Si tenemos una propiedad, $\Psi$, verificando:
1. _Caso base_: se verifica $\Psi$ para todos los elementos de $VP$.
2. _Paso inductivo_:
* Si $F \in PROP$ verifica la propiedad $\Psi$, entonces $\neg F$ verifica la propiedad $\Psi$.
* Si $F, G \in PROP$ verifican la propiedad $\Psi$, entonces $(F \wedge G)$, $(F \vee G)$, $(F \rightarrow G)$, $(F \leftrightarrow G)$ verifican la propiedad $\Psi$.
Entonces, podemos afirmar que todas las fórmulas proposicionales verifican $\Psi$ (que podemos escribir usando un lenguaje matemático como: $\forall F \in PROP \ ( \Psi(F))$).
# Semántica de la Lógica Proposicional
## Interpretaciones, Modelos, Satisfactibilidad y Validez Lógica
Tras haber visto la sintaxis, pasamos a presentar formalmente la semántica de LP. Como ya comentamos, el objetivo fundamental de la semántica es definir qué entendemos por veracidad de una fórmula, que es lo que también nombraremos como la _interpretación_ de las fórmulas. Para ello, previamente, hemos de introducir los conceptos de _valor de verdad_ y _función de verdad_:
!!!def
* **Valor de verdad**. Los elementos del conjunto $\{0,1 \}$ se denominan _valores de verdad_ o _valores booleanos_. Representan si un hecho es cierto o no, de forma que el valor $1$ se asocia a _verdadero_ y el valor $0$ a _falso_. Las lógicas que trabajaremos en este curso solo admiten estos dos posibles valores de verdad, pero hay otras lógicas que admiten más posibilidades (valores de incertidumbre, por ejemplo, o un tercer valor de desconocimiento).
* **Funciones de verdad**. Formalmente, una función de verdad es una función que toma valores de verdad y devuelve un valor de verdad, es decir, $f: \{0,1 \}^n \mapsto \{0,1 \}$. Nos servirán para definir la semántica de los operadores lógicos que se utilizan en la construcción de las fórmulas. Concretamente, en los operadores que hemos definido para LP, las funciones de verdad asociadas serían:
$$\begin{array}{l l}
H_{ \neg}(i) = \left \lbrace \begin{array}{l l}
1 & \textrm{, si } i = 0 \\
0 & \textrm{, si } i = 1 \\
\end{array} \right. &
H_{ \wedge}(i,j) = \left \lbrace \begin{array}{l l}
1 & \textrm{, si } i = j = 1 \\
0 & \textrm{, e.o.c} \\
\end{array} \right. \\ \\
H_{ \vee}(i,j) = \left \lbrace \begin{array}{l l}
0 & \textrm{, si } i = j = 0 \\
1 & \textrm{, e.o.c} \\ \end{array} \right. &
H_{ \rightarrow}(i,j) = \left \lbrace \begin{array}{l l}
0 & \textrm{, si } i = 1, j = 0 \\
1 & \textrm{, e.o.c} \\
\end{array} \right. \\ \\
H_{ \leftrightarrow}(i,j) = \left \lbrace \begin{array}{l l}
1 & \textrm{, si } i = j \\
0 & \textrm{, e.o.c} \\
\end{array} \right. \end{array} $$
Fijados unos valores de verdad de las variables proposicionales (es decir, una indicación acerca de cuáles son verdad y cuáles no, que es lo que se denomina una **valoración** o **interpretación**), podemos extender esta asignación de valores para evaluar si las fórmulas proposicionales que se forman con ellas son ciertas o no bajo ese contexto.
Para ello, basta usar el valor de las variables que intervienen en la fórmula y las funciones de verdad de las conectivas que contiene aplicando sucesivamente las funciones de verdad asociadas a ellas. Así, si $v: VP \mapsto \{0,1 \}$ es la valoración actual de las variables proposicionales, entonces basta tener en cuenta las siguientes extensiones parciales:
$$ \begin{array}{c c}
v((F \wedge G))= H_{\wedge}(v(F), v(G)) & v((F \vee G))= H_{ \vee}(v(F), v(G)) \\ \\
v((F \rightarrow G))= H_{ \rightarrow}(v(F), v(G)) & v((F \leftrightarrow G))= H_{ \leftrightarrow}(v(F), v(G))
\end{array} $$
De esta forma, a partir de cada valoración prefijada, obtenemos un valor de verdad para cualquiera de las fórmulas que podemos construir. Además, es fácil probar (usando el Principio de Inducción que vimos antes) que esta extensión es única, es decir, que este sistema de asignación asigna un solo valor a cada fórmula. Dicho valor depende, exclusivamente, de la valoración inicial de las variables proposicionales.
Haciendo uso del árbol de formación de una fórmula, $F$, podemos ir elevando los valores de $v$ desde las hojas (variables proposicionales que intervienen en $F$) hasta la raíz (que representa a $F$) por los métodos anteriores, obteniendo un valor final para $F$ que representa el valor de verdad de la fórmula.
Por ejemplo, el cálculo del valor de $F \equiv \neg( \neg(p \vee q) \vee( \neg r \vee s))$ respecto de la valoración $v \equiv \{p=1, q=1, r=0, s=0 \}$ (solo indicamos el valor de las variables que intervienen en $F$) sería:
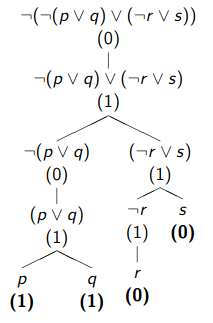
!!!def:Valor de verdad
Dada una fórmula $F \in PROP$, se dice que $v(F)$ es el **valor de verdad** de $F$ respecto de la valoración $v$.
Muchas veces, el conjunto de cálculos que se realizan en el árbol de formación se expresan de forma equivalente a partir de una tabla en la que se anotan en la cabecera de las columnas las diversas subfórmulas que aparecen en el árbol y, bajo ellas, los valores de verdad que toma cada subfórmula al ir aplicando las funciones de verdad de las conectivas. Por ejemplo, para el caso anterior:
| $p$ | $q$ | $r$ | $s$ | $\neg r$ | $p\vee q$ | $\neg(p\vee q)$ | $\neg r \vee s$ | $\neg(p\vee q) \vee \neg(r\vee s)$ | $\neg(\neg(p\vee q)\vee(\neg r\vee s))$ |
|:-----:|:-----:|:-----:|:-----:|:----------:|:-----------:|:-----------------:|:-----------------:|:------------------------------------:|:-----------------------------------------:|
| $1$ | $1$ | $0$ | $0$ | $1$ | $1$ | $0$ | $1$ | $1$ | $0$ |
## Tablas de Verdad
Una **tabla de verdad** es una estructura similar a la anterior (nosotros sólo reflejaremos el valor de las variables proposicionales y el valor de verdad de la fórmula completa), en la que cada fila presenta una posible valoración (es decir, el valor concreto de las variables proposicionales que intervienen en la fórmula) y el valor de verdad de la fórmula respecto a esa valoración.
La tabla de verdad de la fórmula anterior sería:
| $p$ | $q$ | $r$ | $s$ | $\neg(\neg(p\vee q)\vee(\neg r\vee s))$ |
|:-----:|:-----:|:-----:|:-----:|:-----------------------------------------:|
| $0$ | $0$ | $0$ | $0$ | $0$ |
| $0$ | $0$ | $0$ | $1$ | $0$ |
| $0$ | $0$ | $1$ | $0$ | $0$ |
| $0$ | $0$ | $1$ | $1$ | $0$ |
| $0$ | $1$ | $0$ | $0$ | $0$ |
| $0$ | $1$ | $0$ | $1$ | $0$ |
| $0$ | $1$ | $1$ | $0$ | $1$ |
| $0$ | $1$ | $1$ | $1$ | $0$ |
| $1$ | $0$ | $0$ | $0$ | $0$ |
| $1$ | $0$ | $0$ | $1$ | $0$ |
| $1$ | $0$ | $1$ | $0$ | $1$ |
| $1$ | $0$ | $1$ | $1$ | $0$ |
| $1$ | $1$ | $0$ | $0$ | $0$ |
| $1$ | $1$ | $0$ | $1$ | $0$ |
| $1$ | $1$ | $1$ | $0$ | $1$ |
| $1$ | $1$ | $1$ | $1$ | $0$ |
Observa que la tabla anterior contiene toda la información semántica que necesitamos de la fórmula: su interpretación bajo todas las posibles distintas valoraciones de sus variables. Es fácil concluir que, si una fórmula contiene $n$ variables proposicionales distintas, entonces la tabla de verdad asociada tendrá $2^n$ filas. Por lo que, a medida que las fórmulas crecen en número de variables, el tamaño necesario para describir su tabla de verdad asociada crece exponencialmente.
## Modelos, Satisfactibilidad y Validez Lógica
Las valoraciones determinan de alguna forma el _contexto del mundo_, es decir, qué afirmaciones atómicas son ciertas, y cuáles no, en una determinada configuración, y hemos visto que eso determina el valor de verdad de cualquier afirmación que se pueda hacer, sea atómica o no, por medio de la propagación de los valores de verdad a través de las conectivas. Así, fijada una fórmula, habrá valoraciones en las que puede ser verdad, y otras valoraciones en las que, posiblemente, no lo sea. En este sentido, podemos dar las siguientes definiciones:
!!!def:Modelos, Satisfactibilidad y Validez
* **Modelo.** Se dice que una fórmula $F$ es **válida** en una valoración $v$ o, equivalentemente, que $v$ es **modelo** de $F$, si $v(F)=1$, y se denota $v \models F$. En caso contrario, se dice que $v$ es **contramodelo** de $F$ y se denota por $v \not \models F$.
* **Satisfactibilidad.** Una fórmula $F$ se dice **satisfactible** (o **consistente**) si existe una valoración, $v$, que es modelo de $F$ (es decir, hay un _mundo posible_ en el que la fórmula es verdadera). En caso contrario, se dice que $F$ es **insatisfactible** (o **inconsistente**), y se denota por $\perp$.
* **Validez lógica o Tautología**. Una fórmula $F$ se dice **tautología** (o **lógicamente válida**) si toda valoración posible es modelo de $F$, es decir, es cierta en cualquier mundo posible, y se denota $\models F$ (ya que no depende de la valoración).
Observa que decidir si una fórmula $F$ es satisfactible, insatisfactible o tautología es muy fácil usando tablas de verdad:
* Satisfactible: en la tabla de verdad hay alguna fila con valoración 1 para $F$.
* Insatisfactible: en la tabla de verdad todas las filas tienen valoración 0 para $F$.
* Tautología: en la tabla de verdad todas las filas tienen valoración 1 para $F$.
Pero si la fórmula tiene muchas variables (y, en consecuencia, la tabla de verdad es muy grande), entonces podemos gastar mucha memoria y tiempo en almacenar y recorrer toda la tabla para dar una respuesta a esa clasificación.
Además, existe una relación clara entre las posibles clasificaciones, como muestra el siguiente resultado:
!!!note: Lema
Para cada $F \in PROP$ se verifica:
* Si $F$ es tautología, entonces $F$ es satisfactible.
* $F$ es tautología si y sólo si $\neg F$ es insatisfactible.
## Conjuntos de Fórmulas. Modelos y Consistencia
Las definiciones anteriores se han dado para fórmulas individuales, pero podemos extenderlas a conjuntos de fórmulas teniendo en cuenta simplemente que, cuando trabajamos con un conjunto de fórmulas, buscamos que todas las fórmulas del conjunto sean satisfactibles a la vez (es decir, para las mismas valoraciones). La extensión a conjuntos quedaría pues:
!!!Def:Modelos y Consistencia
* **Modelo.** Se dice que una valoración $v$ es **modelo** de un conjunto de fórmulas $U$ si para toda fórmula $F \in U$ se tiene que $v(F)=1$, y se denota por $v \models U$. En caso contrario, se dice **contramodelo**.
* **Consistencia**. Un conjunto de fórmulas $U$ se dice **consistente** si existe una valoración $v$ que es modelo de $U$. En caso contrario, se dice que $U$ es **inconsistente**.
Observa que la consistencia de un conjunto de fórmulas indica que existe un _mundo posible_ (es decir, una valoración) que hace que todas las fórmulas del conjunto sean simultáneamente verdad.
## Consecuencia Lógica
Gracias a haber extendido la idea de consistencia y modelo a conjuntos de fórmulas podemos dar una definición de _consecuencia lógica_ que se corresponde con la idea intuitiva que teníamos en el planteamiento original del problema central de la lógica:
!!!def:Consecuencia Lógica
Una fórmula $F$ es **consecuencia lógica** (o se sigue lógicamente) de un conjunto de fórmulas $U$, y se denota por $U \models F$, si todo modelo de $U$ (de todas las fórmulas de $U$) es también modelo de $F$.
Es decir, intuitivamente, lo que dice esta definición es que $F$ es consecuencia lógica de $U$ si, en todo mundo posible en el que las fórmulas de $U$ sean ciertas, es obligatorio que $F$ también es cierto. Es así como nosotros podemos extraer una condición de consecuencia entre afirmaciones: si $U$ es cierto, entonces $F$ debe ser también cierto.
El siguiente resultado nos da varias dos formas de establecer esta relación de consecuencia. Además, unifica la definición formal de consecuencia con otras intuiciones que proporcionan formas alternativas de reconocer cuándo se produce dicha consecuencia. El resultado confirma que nuestras intuiciones y la definición se corresponden bastante bien:
!!!note:Teorema de la Consecuencia
Sea $U= \{F _1, F _2, \ldots, F _n \} \subseteq PROP$ y $F \in PROP$ son equivalentes:
* $\{F _1, F _2, \ldots, F _n \} \models F$ (es decir, $F$ es consecuencia lógica de $U$).
* $(F _1 \wedge F _2 \wedge \ldots \wedge F _n) \rightarrow F \in TAUT$ (es decir, la intuición de que la veracidad de $U$ obliga a la veracidad de $F$ siempre).
* $\{F _1 , F _2 , \ldots , F _n , \neg F \}$ es inconsistente (es decir, no es posible que sea cierto $U$ y no sea cierto $F$).
Es importante destacar algunos puntos del resultado anterior:
1. Observa que el resultado tiene nombre propio: **Teorema de la Consecuencia**, y esto ocurre porque será un resultado fundamental que usaremos a lo largo del curso continuamente, ya que nos proporciona métodos prácticos para poder probar si una afirmación es consecuencia de otras. Y **no sólo en LP**, sino que **será igualmente útil en LPO**.
2. El resultado anterior convierte el problema de la consecuencia lógica en dos posibles problemas de decisión: 1) decidir se cierta fórmula es tautología o no; 2) decidir si cierto conjunto es consistente o no.
3. Hay infinitas fórmulas proposicionales distintas, así que $U$ podría ser un conjunto infinito. Sin embargo, el resultado anterior se tiene solo para el caso en que $U$ sea un **conjunto finito de fórmulas**.
4. La segunda equivalencia es la que se corresponde con la intuición de que la consecuencia lógica es lo mismo que la implicación lógica siempre cierta: $B$ es consecuencia de $A$ si $A \rightarrow B$ es siempre cierto.
5. Observa que la implicación ($A \rightarrow B$) solo _obliga_ a la veracidad de $B$ **cuando $A$ es cierta**, pero si $A$ es falsa, entonces $B$ puede tomar cualquier valor de verdad y la implicación seguirá siendo cierta. Así que, realmente, esta segunda equivalencia se puede leer como: "_cuando $A$ sea cierta, entonces $B$ es cierta_"... que es exactamente lo que dice la definición de consecuencia lógica.
6. La tercera equivalencia expresa realmente lo que se utiliza para realizar una demostración de un resultado por **reducción al absurdo**:
Si queremos saber si bajo las hipótesis $F _1, \dots,F _n$ es cierta la afirmación $F$ (es decir, si $\{F _1, \ldots, F _n \} \models F$), el método de reducción al absurdo nos dice que supongamos lo contrario a lo que queremos probar (es decir, $\neg F$), y veamos si es posible esta opción conviviendo simultáneamente con las hipótesis (es decir, si $\{F _1, \ldots, F _n, \neg F \}$ es consistente o no). Si no es posible (si es inconsistente), entonces $F$ es necesariamente cierta en estas condiciones.
Es este concepto de consecuencia el que permitirá formalizar el problema básico inicial en el marco de la lógica proposicional (y el que se convierte en central en todas las lógicas, no sólo en LP, como veremos posteriormente en LPO), y que planteamos como objetivo de nuestro estudio.
# Algoritmos de decisión en LP
Como hemos señalado, vamos a presentar de forma muy superficial algo sobre algoritmos de decisión en LP. Será solo algo introductorio porque iremos desarrollando algunos de los algoritmos más importantes a lo largo de los distintos capítulos que componen este curso.
Un _algoritmo de decisión_ para un conjunto de fórmulas es simplemente un algoritmo que me permite decidir si una fórmula está en el conjunto o no:
!!!def
Dado un conjunto de fórmulas, $\Phi$, un **algoritmo de decisión** para $\Phi$ es uno que, dada una fórmula $A \in PROP$, devuelve **SI** cuando $A \in \Phi$, y **NO** cuando $A \not \in \Phi$.
Esto da pie a la definición de algunos problemas especialmente interesantes cuando se toma como $ \Phi$ algunos conjuntos de fórmulas específicos, por ejemplo:
!!!def:Conjuntos Notables
* $\Phi=SAT = \{A \in PROP: \, A \textit{ es satisfactible} \}$, el conjunto de fórmulas satisfactibles.
* $\Phi=TAUT = \{A \in PROP: \, A \textit{ es tautología} \}$, el conjunto de tautologías.
* Fijado $U \subseteq PROP$, la _Teoría de $U$_ corresponde a: $\Phi= \mathcal{T}(U) = \{A \in PROP: \, U \models A \}$, las fórmulas que son consecuencia de $U$.
Los dos primeros ejemplos, que se llaman respectivamente **Problema SAT** y **Problema de la Validez**, tienen fijado el conjunto sobre el que se quiere decidir, pero el tercero depende de $U$, y se llama **Problema de la Consecuencia de $U$**. Si lo observas bien, cuando en el tercero usamos $U$ finito, un algoritmo de decisión para $\mathcal{T}(U)$ proporciona una respuesta al Problema Básico que planteamos al comienzo del capítulo. Por tanto, podemos reducir dicho problema a uno nuevo:
!!!note
Obtener un algoritmo que, dado un conjunto finito de fórmulas proposicionales, $U$, y una fórmula, $F$, decida si $U \models F$.
Y éste, a su vez, aplicando el **Teorema de la Consecuencia**, se reduce a comprobar la validez de una cierta fórmula ($F _1 \wedge \dots \wedge F _n \rightarrow F$) o bien la satisfactibilidad de un conjunto ($\{F _1, \dots,F _n, \neg F \}$), lo que reduce el tercer problema a uno de los dos primeros problemas (dependiendo de si que se usa en el teorema la equivalencia con el apartado 2, o con el apartado 3).
De hecho, ya hemos visto un algoritmo que usa Tablas de Verdad para resolver de forma sencilla cualquiera de estos problemas, pero vimos que la complejidad de dicho algoritmo es exponencial en el número de símbolos proposicionales de la fórmula para la que se construye la tabla, lo que lo hace inabordable para fórmulas de cierta complejidad (por ejemplo, una fórmula que use 1000 variables proposicionales, algo relativamente pequeño para problemas que aparecen en el mundo real, requeriría de la construcción de una tabla con $2^{1000}$ filas, completamente inabordable por medios directos, tanto por la memoria necesaria para almacenarla como por el tiempo empleado para construirla y recorrerla).
El objetivo de los siguientes capítulos será proporcionar métodos alternativos para generar otros algoritmos de decisión para estos problemas. Sin embargo, hemos de aclarar una situación especialmente delicada: algunos de los algoritmos que veremos parecerán más eficientes que otros, pero es importante recordar que no se ha encontrado ninguno capaz de resolver el problema **SAT** de manera eficiente (con complejidad polinomial) para todos sus casos y, de hecho, se duda (con fundamento) de la existencia de un tal algoritmo.
Este decepcionante hecho se debe a que se piensa que las clases **P** (la clase de los problemas que se pueden resolver en tiempo polinomial con **algoritmos deterministas**) y **NP** (la clase de los problemas que se pueden resolver en tiempo polinomial con **algoritmos no deterministas**) son distintas, y el problema **SAT** es **NP**-completo, es decir, está en la bolsa de los problemas más complejos de los que habitan **NP**, lo que quiere decir que, si se pudiera resolver **SAT** en tiempo polinomial y de forma determinista, cualquier otro problema de **NP** se podría resolver en tiempo polinomial y de forma determinista... o lo que es lo mismo, que podríamos convertir cualquier algoritmo eficiente no determinista en un algoritmo eficiente completamente determinista.
Puedes encontrar otro video interesante (esta vez en inglés) sobre este tema [aquí](https://www.youtube.com/watch?v=YX40hbAHx3s).
En consecuencia, en el resto del curso no podemos esperar milagros, pero sí podemos esforzarnos en encontrar algoritmos que funcionen suficientemente bien para muchísimas fórmulas, aunque no todas. La diferencia esencial con que el método de las tablas de verdad es que éste malo siempre porque, sea como sea la fórmula, siempre ha de construir una cantidad exponencial de casos, pero veremos métodos que, aunque las fórmulas tengan muchas variables, pueden encontrar atajos para decidir sobre ellas en pocos pasos (aunque siempre haya algunas fórmulas, esperemos que no muy habituales, en las que estos métodos también necesitarán muchos recursos).