**LITI**
Sintaxis y Semántica de la Lógica de Primer Orden
Aunque la Lógica Proposicional posee un semántica sencilla y existen algoritmos de decisión (aunque no sean eficientes) para los problemas básicos que hemos encontrado (**SAT**, **TAUT** y **Problema de la consecuencia**), su expresividad es bastante limitada, lo que hace que muchas situaciones no sean modelables en LP, bien porque requieren de mucho espacio (un gran número de fórmulas, y/o fórmulas de gran tamaño), o bien porque ni siquiera pueden expresarse en este lenguaje. Una **Lógica de Primer Orden**, también llamada lógica de predicados, es un sistema formal diseñado para estudiar la inferencia en los lenguajes de primer orden, que son lenguajes formales que extienden la Lógica Proposicional por medio de cuantificadores y símbolos que permiten hablar de los objetos de un dominio con predicados y funciones.
# Limitaciones de la Lógica Proposicional
Aunque la Lógica Proposicional posee un semántica sencilla y existen algoritmos de decisión (aunque no sean eficientes) para los problemas básicos que hemos encontrado (**SAT**, **TAUT** y **Problema de la consecuencia**), su expresividad es bastante limitada, lo que hace que muchas situaciones no sean modelables en LP, bien porque requieren de mucho espacio (un gran número de fórmulas, y/o fórmulas de gran tamaño), o bien porque ni siquiera pueden expresarse en este lenguaje.
El siguiente ejemplo presenta un razonamiento que es válido, y que sin embargo no es expresable en LP:
1. Todo hombre es mortal.
2. Sócrates es hombre.
3. Por tanto, Sócrates es mortal.
¿Cómo expresar el concepto de ser hombre?¿Como expresar quién es Sócrates?, pero aún más ¿Cómo expresar que todos los hombres son mortales? Aunque para nosotros hay una relación clara entre las afirmaciones que se dan, para LP esas afirmaciones son independientes, por lo que su formalización sería algo tan simple (e inútil) como:
$$\{p,q \} \models r$$
donde $p$: _Todo hombre es mortal_, $q$: _Sócrates es hombre_, y $r$: _Sócrates es mortal_. Observa que con esta formalización no hay mecanismos en LP para poder asegurar si la consecuencia lógica que indica el razonamiento expresado en lenguaje natural es verificable o no.
Intuitivamente, tendemos a pensar que hay una relación entre las frases anteriores porque hacen referencia a cosas parecidas y relacionadas, en las que no hay una igualdad de conceptos, pero si relaciones de otro tipo. Por ejemplo, _Todo hombre es mortal_ es una afirmación atómica, lo que se traduce en una variable proposicional en LP. Lo mismo le sucede a _Sócrates es hombre_, que es una afirmación, y por tanto se traduce en una variable (otra distinta a la anterior, ya que la afirmación es distinta). Pero internamente, por ejemplo en la primera, tendemos a pensar en algo más parecido a una implicación lógica: _Todo hombre cumple que, si es hombre, entonces es mortal_, que sería algo como $p \rightarrow q$, pero ¿quién sería $p$ y quién $q$?, ¿$p$: _ser hombre_, $q$: _ser mortal_?, pero, ¿son entonces $p$ y $q$ afirmaciones?, en ese caso, ¿afirmaciones de qué?, ¿no serían más bien propiedades de individuos/objetos independientes?, es decir, algunos objetos podrán ser hombres y otros no.
Es aquí precisamente, en esta debilidad que presenta LP, donde comienza el ámbito de la Lógica de Primer Orden, que viene a cubrir las carencias de expresividad observadas extendiendo las capacidades del lenguaje para permitir abordar cuestiones como:
* Trabajar con objetos de un dominio de forma individualizada, no solo a nivel global (por ejemplo, cada _hombre_ por separado, y _Sócrates_ como uno de ellos).
* Representar propiedades de objetos y las relaciones entre ellos (por ejemplo, _ser hombre_ o _ser mortal_).
* Realizar cuantificación sobre los objetos de un dominio, esto es, expresar en qué medida se tiene una propiedad sobre un conjunto de objetos (por ejemplo, _todos los hombres_).
De forma análoga a como se ha visto para LP vamos a estudiar los elementos que definen la Lógica de Primer Orden (Sintaxis y Semántica) dejando para capítulos futuros el desarrollo de los algoritmos de decisión asociados a los problemas equivalentes.
# Sintaxis de LPO
A diferencia de la Lógica Proposicional, que define un único lenguaje que sirve para modelar todas las expresiones neCesarias para la formalización de los problemas, en la Lógica de Primer Orden los lenguajes pueden tener símbolos específicos del dominio sobre el que se quieran expresar afirmaciones (las necesidades expresivas cuando trato relaciones humanas no son las mismas que cuando trato objetos matemáticos, por ejemplo). Concretamente, un Lenguaje de Primer Orden es un lenguaje formal que consta de (observa cómo extiende LP):
!!!def:Sintaxis de la Logica de Primer Orden
* **Símbolos lógicos** (comunes a todos los lenguajes): En los que se engloban:
* Un conjunto de _Variables:_ $V = \{x, x _0, x _1, \ldots, y, y _0, \ldots \}$.
* _Conectivas lógicas :_ $\neg$ (negación), $\wedge$ (conjunción), $\vee$ (disyunción), $\rightarrow$ (implicación), $\leftrightarrow$ (equivalencia).
* _Cuantificadores:_ $\exists$ (existencial), $\forall$ (universal).
* _Símbolos auxiliares:_ "$($" y "$)$".
* **Símbolos no lógicos** (específicos de cada lenguaje): En los que se engloban:
* Un conjunto de _constantes_: $L _{C}= \{a, b, \ldots, a _{0}, a _{1}, \ldots \}$.
* Un conjunto de _símbolos de función_: $L _{F} = \{f _{0}, f _{1}, \ldots \}$, cada uno con su aridad correspondiente.
* Un conjunto de _símbolos de predicado_: $L _P= \{P _{0}, P _{1}, \ldots, Q, Q _0, \ldots \}$, cada uno con su aridad correspondiente.
Donde se debe tener en cuenta que:
* Veremos que los símbolos de predicado de aridad 0 actúan como símbolos proposicionales.
* El símbolo de igualdad (‘$=$’) no es un predicado común a todos los lenguajes de primer orden, pero sí es corriente su aparición, por lo que si es neCesario lo introducimos. La familia de lenguajes que incluyen este predicado es denominada _Lenguajes de Primer Orden con Igualdad_.

A diferencia de LP, en LPO las variables no son proposicionales y no tienen valores de verdad, sino que sirven para identificar objetos del mundo. Para cubrir la funcionalidad que tenían las variables proposicionales tenemos los _predicados_, que expresan afirmaciones sobre los objetos del mundo, y cuya veracidad sí es evaluable (su función es más rica que las variables proposicionales de LP). Por ello, a LPO también se le denomina **Lógica de Predicados**.
Una posible formalización del razonamiento anterior nos podría llevar a definir el siguiente LPO (los superíndices indican la aridad):
$$L= \{ \underbrace{ \mathbf{s} } _{constante}, \underbrace{Hombre^{1}, Mortal^{1} } _{ \textit{símbolos de predicado} } \ \}$$
Este aparato permite la construcción de distintas expresiones en LPO. Vamos a exponer una diferenciación de dichas expresiones, distinguiendo entre _términos_ y _fórmulas_ según hablen de objetos del mundo o indiquen afirmaciones. Al igual que vimos en LP, existen expresiones bien formadas y expresiones mal formadas. Todo aquello que no pueda ser reconocido como un término o como una fórmula se considerará una expresión mal formada.
## Términos en LPO
!!!def: Términos
Los **términos** son las expresiones del lenguaje que se identifican con posibles objetos del mundo. Engloban los siguientes elementos:
* Las **Constantes** son términos del lenguaje (sirven para hablar de objetos específicos).
* Las **Variables** son términos del lenguaje (sirven para hablar de objetos genéricos).
* Las **Funciones** aplicadas a otros términos son también términos del lenguaje. Es decir, si $f$ es un símbolo de función del lenguaje, de aridad $n$, y $t _1$,...,$t _n$ son términos del lenguaje, entonces $f(t _1, \dots,t _n)$ es también un término del lenguaje.
!!!Tip: Ejemplo
Por ejemplo, si tenemos el Lenguaje de Primer Orden siguiente:
$$L _A = \{ \underbrace{\boldsymbol{0}, \boldsymbol{1} } _{constantes}, \underbrace{Par^{1}, <^{2}, =^{1} } _{\textit{símbolos de predicado} }, \underbrace{s^{1}, +^{2} } _{\textit{símbolo de función}} \}$$
entonces, los términos del lenguaje son:
* Por las _constantes_: **0**, **1**.
* Por las _variables_: $x$, $y$, $x _1$, ...
* Por las _funciones_: $s(\boldsymbol{0})$, $s(x)$, $s(s(\boldsymbol{1}))$, $+(x, \boldsymbol{1})$, $+(s(\boldsymbol{0}),s(s(y)))$, ...
En algunos casos, se utiliza la notación infija con las funciones binarias, por ejemplo: $\boldsymbol{0}+ \boldsymbol{1}$, $s( \boldsymbol{0})+s(s( \boldsymbol{1}))$.
## Fórmulas en LPO
!!!def: Fórmulas en LPO
Las fórmulas son las expresiones que se identifican con afirmaciones sobre los objetos del mundo, y tendrán (cuando veamos la semántica) la posibilidad de ser evaluadas como verdaderas o falsas. Están formadas a partir de predicados sobre términos (que son las fórmulas más sencillas), y construcciones lógicas de estos predicados (conjunciones, implicaciones, cuantificaciones, etc.):
* **Átomos o Fórmulas atómicas**. Si $p$ es un símbolo de predicado de aridad $n$ y $t _1$,...,$t _n$ son términos del lenguaje, entonces la expresión $p(t _1, t _2, \ldots, t _n)$ es una fórmula del lenguaje (se llaman _atómicas_ porque no pueden descomponerse en fórmulas más sencillas).
* **Fórmulas no atómicas**. Corresponden a expresiones formadas a partir de fórmulas atómicas mediante el empleo de conectivas y/o cuantificadores.
* Si F y G son fórmulas del lenguaje, entonces $ \neg F$, $(F \wedge G)$, $(F \vee G)$, $(F \rightarrow G)$, $(F \leftrightarrow G)$, también son fórmulas del lenguaje.
* Si $x$ es una variable y $F$ es una fórmula del lenguaje, entonces $\exists x \, F$ y $\forall x \, F$ son también fórmulas del lenguaje.
!!!Tip
Volviendo al lenguaje anterior, algunas posibles fórmulas del lenguaje $L _A$ podrían ser:
* _Fórmulas atómicas_: $<(x, \boldsymbol{0})$, $=(\boldsymbol{0}, \boldsymbol{1})$, $<(s(s(\boldsymbol{1})),y)$,...
En algunos casos, se usa la notación infija con los predicados binarios, por ejemplo: $x < \boldsymbol{0}$, $\boldsymbol{0}= \boldsymbol{1}$, $s(s(\boldsymbol{1})) < y$,...
* _Fórmulas no atómicas_: $\forall x \exists y \, (x < y)$, $\forall x (Par(x) \rightarrow \left( (0 < x) \wedge (1 < x) \right)$,...
Al igual que hicimos en LP, definimos una serie de reglas que permiten reducir el número de paréntesis neCesarios para escribir las fórmulas:
* Se omitirán los paréntesis más externos.
* Las prioridades de las conectivas lógicas siguen el mismo orden que el expuesto en LP: $\neg, \wedge, \vee, \rightarrow, \leftrightarrow$ (para la última se recomienda mantener los paréntesis).
* Los cuantificadores tienen prioridad sobre las conectivas lógicas.
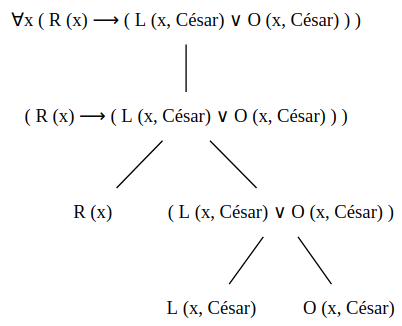
## Árboles de Formación
Al igual que en las fórmulas de LP, la definición de las fórmulas en LPO presenta una estructura recursiva, donde los constructores básicos son las fórmulas atómicas, y las operaciones constructivas se realizan por medio de la aplicación de las conectivas lógicas y los cuantificadores. Así que también se puede plasmar esta estructura recursiva en un grafo de tipo árbol (que es esencialmente único salvo orden), de forma que el nodo raíz corresponde a la fórmula completa y las hojas corresponden a las fórmulas atómicas que participan en la fórmula (podríamos continuar con las hojas expresando también la formación de los términos que intervienen). Al igual que en LP, toda fórmula que aparezca en cualquiera de los nodos del árbol (ya sea un nodo interno o una hoja) diremos que es **subfórmula** de la fórmula original.
Por ejemplo, para la fórmula $\forall x (R(x) \rightarrow \left( L(x, \boldsymbol{Cesar}) \vee O(x, \boldsymbol{Cesar}) \right)$, se tendría el Árbol de Formación asociado:
## Alcance de los cuantificadores y renombramiento de variables
Hemos estudiado la sintaxis formal de las fórmulas, pero aún faltan algunos detalles para establecer qué fórmulas están bien formadas y cuáles no. Para ello hemos de profundizar en el tratamiento de la cuantificación, concretamente, en analizar qué ocurrencias concretas (estancias) de una variable están bajo la influencia de un cuantificador:
!!!Def:Ocurrencias
Una ocurrencia de una variable está bajo la influencia de un cuantificador (se dice que es **ligada**) si la ocurrencia pertenece al subárbol que hay bajo el cuantificador en el árbol de formación. En otro caso diremos que es **libre**.
En el siguiente ejemplo:
$$ \underbrace{ \forall x} _{1} \, \boxed{( P( \underbrace{x} _{ \begin{array}{c} \textit{ocurr. de} \\
\textit{x ligada} \end{array} }, \underbrace{y} _{ \begin{array}{c} \textit{ocurr. de} \\
\textit{y libre} \end{array} }) \rightarrow \underbrace{ \exists y} _{2} \, \boxed{R( \underbrace{y} _{ \begin{array}{c} \textit{ocurr. de} \\
\textit{y ligada} \end{array} }, \underbrace{x} _{ \begin{array}{c} \textit{ocurr. de} \\
\textit{x ligada} \end{array} } ) } _{2} ) } _{1}$$
podemos ver que el cuantificador $\forall x$ ($1$), afecta a toda la subfórmula siguiente (encuadrada con el índice $1$), por tanto todas las ocurrencias de $x$ que aparezcan en esta subfórmula serán ligadas. Sin embargo, $P(x,y)$ no está afectado por ningún otro cuantificador, por tanto, la ocurrencia de $y$ en $P(x,y)$ es libre, ya que no está bajo la influencia de ningún cuantificador. Por otra parte, $R(x,y)$ sí está afectado por el cuantificador $\exists y$ (2), por tanto, las ocurrencias de $x$ e $y$ en $R(y, x)$ son ligadas (una bajo la influencia del primer cuantificador, y otra bajo la influencia del segundo).
En general, se definen las variables _libres_ y _ligadas_ como:
!!!def:Variables libres y ligadas
* Una variable, $x$, se dice **libre** en una fórmula, $F$, si existe alguna ocurrencia libre de $x$ en $F$.
* Una variable, $x$, se dice **ligada** en una fórmula, $F$, si existe alguna ocurrencia ligada de $x$ en $F$.
De forma que en una fórmula una variable puede ser al mismo tiempo _variable libre_ y _variable ligada_, porque puede aparecer como ligada en una parte de la fórmula y como libre en otra.
En el ejemplo anterior $x$ es una variable _exclusivamente ligada_ (todas sus ocurrencias son ligadas), sin embargo, $y$ es una variable _libre_ y _ligada_ (hay una ocurrencia libre y otra ligada).
En base a lo anterior se definen los conceptos:
!!!def:Términos cerrados
Se dice que un **término** es **cerrado** si no contiene ninguna variable.
Observa que en los términos no puede haber cuantificadores, por lo que si aparece una variable, ésta siempre es libre. Por ejemplo: $\boldsymbol{0}$, $s(\boldsymbol{1})$, $\boldsymbol{0}+ \boldsymbol{1}$ son términos cerrados en el lenguaje $L _A$ (no tiene variables libres).
!!!def:Fórmulas cerradas
Se dice que una **fórmula** es **cerrada** si no contiene variables libres, o equivalentemente si todas las estancias de todas las variables que aparecen son ligadas.
!!!Tip:Ejemplos
Por ejemplo las fórmulas:
$$ \forall x (x < \boldsymbol{1} \vee x= \boldsymbol{0})$$
$$ \forall x \, L(x, Cesar) \rightarrow \neg \exists y \, O(Cesar, y)$$
$$O(Cesar, Marco)$$
son cerradas, mientras que las fórmulas:
$$ \forall x \, L(x, Cesar) \vee O(Cesar, x)$$
$$ \forall x \, L(x, Cesar) \rightarrow \neg \exists y IA(y, x)$$
no lo son.
!!!def:Fórmula abierta
Se dice que una fórmula es **abierta** si no contiene cuantificadores. En consecuencia, todas sus variables son, exclusivamente, _variables libres_.
!!!Tip:Ejemplos
Por ejemplo, son fórmulas abiertas: $P(x)$, $R(Cesar)$, $P(x) \leftrightarrow \neg IA(f(x), Marco)$.
Téngase en cuenta que los conceptos de fórmula abierta y fórmula cerrada no son opuestos, por lo que pueden existir fórmulas que son abiertas y cerradas a la vez. Simplemente, hay que buscar por una parte fórmulas que no usen cuantificadores, y a la vez que no tengan variables libres (ambas condiciones a la vez implican que no puede tener variables), por ejemplo:
$$(\boldsymbol{0}< \boldsymbol{1}) \rightarrow (s( \boldsymbol{0}) < s( \boldsymbol{1}))$$
Incidiremos más en este aspecto cuando veamos la semántica en LPO.
Aunque las fórmulas estén bien escritas sintácticamente, incluso aunque sean cerradas, es posible que su interpretación sea ambigua, esta ambigüedad suele venir dada por un mal uso de los cuantificadores y las variables, por ejemplo, supongamos la fórmula:
$$\forall z \, \forall x \, \exists y \, \left( P \left(x, y \right) \rightarrow \left( P \left(x, z \right) \vee \exists z \, \left( P \left(y, \boxed{z} \right) \wedge P \left(x, y \right) \right) \right) \right)$$
La ocurrencia de $z$ señalada, es claramente ligada, pero ¿bajo la influencia de qué cuantificador? Para evitar esta ambigüedad restringiremos las fórmulas bien formadas a aquellas que no presentan este tipo de problemas, y en caso necesario realizaremos un renombramiento de las variables, manteniendo el sentido original de las fórmulas, de forma que la fórmula anterior podríamos renombrarla mejor como:
$$\forall z _1 \, \forall x \, \exists y \, \left( P \left(x, y \right) \rightarrow \left( P \left(x, z _1 \right) \vee \exists z _2 \, \left( P \left(y, z _2 \right) \wedge P \left(x, y \right) \right) \right) \right)$$
No es el único caso en el que es necesario renombrar las variables, por ejemplo, si en una fórmula aparece una variable que a la vez se usa como libre y como ligada, aunque sea en distintas subfórmulas, las renombraremos para que no haya confusión. Por ejemplo, en la fórmula:
$$\forall x \, \exists y \, \left( P \left(x, y \right) \rightarrow \left( P(x, \boxed{z}) \vee \exists z \, \left( P(y, \boxed{z}) \wedge P \left(x, y \right) \right) \right) \right)$$
la primera ocurrencia de $z$ señalada es libre y la segunda es ligada, por lo que claramente el mismo símbolo de variable representa objetos distintos, lo que produce cierta ambigüedad en la fórmula. Sin embargo, podemos renombrar la fórmula como:
$$\forall x \, \exists y \, \left( P \left(x, y \right) \rightarrow \left( P \left(x, z \right) \vee \exists z _1 \, \left( P \left(y, z _1 \right) \wedge P \left(x, y \right) \right) \right) \right)$$
## Sustituciones en LPO
!!!def:Sustituciones
Una **sustitución**, **$\theta$**, corresponde a una función que asigna a un conjunto finito de variables, $dom( \theta)= \{x _1, \dots,x _n \}$, un conjunto finito de términos, $\theta(x _i)=t _i \, (i=1, \ldots, n)$. Para denotar una sustitución, lo hacemos por $\theta= \{x _1/t _1, \ldots, x _n/t _n \}$, o también por $\theta= \{(x _1,t _1), \ldots, (x _n,t _n) \}$.
La forma en que se aplican las sustituciones en las expresiones del lenguaje es la natural (aunque pueda parecer más complicado al escribirlo formalmente).
En los términos consiste simplemente en cambiar la aparición de las variables que intervienen en la sustitución por los términos correspondientes.
!!!note
Si $t$ es el término sobre el que se hace la sustitución, entonces la sustitución aplicando $\theta$, que se denota por $\theta(t)$ (o también $t \{x _1/t _1, \ldots, x _n/t _n \}$) es, formalmente:
$$ \theta(t) = \left \lbrace \begin{array}{lll}
\theta(x _i) & \text{si } t=x_i & [t \text{ es una variable}]\\
f(\theta(t _1), \ldots, \theta(t _m)) & \text{si } t=f(t _1, \ldots, t_m) & [t \text{ es una función de aridad } m ]
\end{array} \right.$$
Por ejemplo, si tenemos la sustitución $\theta = \{x/(x+y), z/ \boldsymbol{0}, u/ \boldsymbol{1} \}$ y el término $t=(x+y)+z$, entonces:
$$\theta(t)=((x+y) + y) + \boldsymbol{0}$$
Nótese el carácter simultáneo de la sustitución, por lo que la sustitución de una variable, $x _i$ por un término en el que intervenga otra variable, $x _j$ no está afectado por la sustitución de $x _j$.
En las fórmulas el mecanismo es el mismo, pero se realiza solo sobre las ocurrencias **libres** de las variables que aparecen en la sustitución.
!!!note
Si $F$ es la fórmula sobre la que se hace la sustitución, entonces la sustitución aplicando $\theta$, que se denota por $\theta(F)$ (o también $F \{x _1/t _1, \ldots, x _n/t _n \}$) es, formalmente:
$$ \theta(F) \equiv \left \lbrace \begin{array}{ll}
P( \theta(t _1), \ldots, \theta(t _n)) & \text{si } \, F \equiv P(t _1, \ldots, t _n) \\
\neg \theta(G) & \text{si } \, F \equiv \neg G \\
\theta(G) \wedge \theta( H) & \text{si } \, F \equiv G \wedge H \\
\theta(G) \vee \theta( H) & \text{si } \, F \equiv G \vee H \\
\theta(G) \rightarrow \theta( H) & \text{si } \, F \equiv G \rightarrow H \\
\theta(G) \leftrightarrow \theta( H) & \text{si } \, F \equiv G \leftrightarrow H \\
\exists x \, G \{x _i/t _i : x _i \neq x \} & \text{si } \, F \equiv \exists x \, G \\
\forall x \, G \{x _i/t _i : x _i \neq x \} & \text{si } \, F \equiv \forall x \, G
\end{array} \right.$$
Sin embargo, no todas las sustitución son **admisibles** para una fórmula, por ejemplo, la acción directa de la sustitución $\theta = \{y/x \}$ sobre la fórmula $F \equiv \exists x \, \neg(x=y)$ daría como resultado $\theta(F) = \exists x \neg (x=x)$. Claramente, el sentido de la fórmula ha cambiado profundamente: mientras que en la primera fórmula se establece que debe haber, al menos, dos objetos distintos, en la segunda se tiene que existe al menos un objeto que es distinto de sí mismo (que no puede ser cierto nunca).
Para evitar estos casos, definimos cuándo una variable de una sustitución es, de hecho, sustituible en una fórmula de la siguiente forma:
!!!def:Variables sustituibles
Una variable, $x _i \in dom( \theta)$, de una fórmula, $F$, es sustituible por el término correspondiente, $t _i$, si y sólo si la aplicación de la sustitución, $\theta(F)$ no produce nuevas ocurrencias ligadas.
En cada posible caso de construcción de $F$, una variable $x _i$ de $F$ es sustituible por $t _i$ si se da alguna de las siguientes condiciones:
1. $F$ es atómica.
2. $F \equiv \neg G$ y $x _i$ es sustituible por $t _i$ en $G$.
3. $F \equiv G \left( \wedge | \vee | \rightarrow | \leftrightarrow \right) H$ y $x _i$ es sustituible por $t _i$ en $G$ y en $H$.
4. $F \equiv \exists x G$ tal que o bien $x=x _i$ (porque en este caso la sustitución no realiza ningún cambio ya que $x _i$ no es libre en $F$), o bien $x \neq x _i$, $x$ no ocurre en $t _i$ y $x _i$ es sustituible en $G$.
5. $F \equiv \forall x G$ tal que o bien $x=x _i$ (porque en este caso la sustitución no realiza ningún cambio ya que $x _i$ no es libre en $F$), o bien $x \neq x _i$, $x$ no ocurre en $t _i$ y $x _i$ es sustituible en $G$.
En lo que sigue, cuando escribamos $F \{x/t \}$ supondremos que $x$ es sustituible por $t$ en $F$.
**NOTA**: Si dada una fórmula $F(x _1, \ldots, x _n)$, el orden de las variables está claro podemos abreviar $F \{x _1/t _1, \ldots, x _n/t _n \}$ por $F(t _1, \ldots, t _n)$.
# Semántica de LPO
Como en el resto de lenguajes formales, el objetivo de la semántica es dotar de significado a los términos y fórmulas de un Lenguaje de Primer Orden. Para ello vamos a ver los elementos que conforman la semántica:
!!!Def:$L$-estructura
Sea $L$ un lenguaje de primer orden. Una **$L$–estructura** (o $interpretación$) corresponde a un par $\mathcal{M}= (M, I)$ donde $M$ es un conjunto no vacío, llamado **universo** (o dominio) de la $L$-estructura, e $I$ es una aplicación que:
1. Para cada constante de $c \in L _C$, asocia un objeto $c^{ \mathcal{M} } \in M$.
2. Para cada símbolo de función $n$-ario de $f \in L _F$, asocia una función $n$-aria: $f^{ \mathcal{M} } : M^{n} \longrightarrow M$.
3. Para cada símbolo de predicado $n$-ario de $P \in L _P$, asocia un predicado $n$-ario: $P^{\mathcal{M} } : M^{n} \longrightarrow \{0,1 \}$, o equivalente, un conjunto $P^{n} \subseteq M^{n}$. Si $n=0$, entonces el símbolo está asociado directamente con un valor de verdad, por eso podemos identificar los predicados 0-arios con las variables proposicionales.
En caso de trabajar con la igualdad, su interpretación siempre será: $=^{ \mathcal{M} }: \{(a,a): a \in M \}$.
(Para facilitar la lectura, si no hay ambigüedad escribiremos $M$ en vez de $\mathcal{M}$)
!!!Tip:Ejemplos
Por ejemplo, para el lenguaje $LA = \{\underbrace{\boldsymbol{0}, \boldsymbol{1}}_{const.}, \overbrace{<^{2}, =^{2} }^{pred.}, \underbrace{·^{2}, +^{2} }_{func.}\}$, podemos dar las siguientes subestructuras distintas (entre otras muchas):
1. $\mathcal{M _1} = \left \lbrace \begin{array}{l}
M _1 = \mathbb{N} \\
\boldsymbol{0}^{M _1} = 0; \boldsymbol{1}^{M _1} = 1; \\
+^{M _1} : \mathbb{N^2} \longrightarrow \mathbb{N}, \, +^{M _1}(n _1, n _2) = n _1 + n _2 \\
·^{M _1} : \mathbb{N^2} \longrightarrow \mathbb{N}, \, ·^{M _1}(n _1, n _2) = n _1 · n _2 \\
<^{M _1} : \mathbb{N^2} \longrightarrow Bool, \, <^{M _1} = \{(i,j): (i,j) \in \mathbb{N^2} \wedge (i < j) \} \\
=^{M _1} : \mathbb{N^2} \longrightarrow Bool, =^{M _1} = \{(i,i) : i \in \mathbb{N} \} \\
\end{array} \right.$
2. $\mathcal{M _2} = \left \lbrace \begin{array}{l} M _2 = \mathbb{Q} \\
\boldsymbol{0}^{M _2} = \frac{1}{2}; \boldsymbol{1}^{M _2} = 2; \\
+^{M _2} : \mathbb{Q}^2 \longrightarrow \mathbb{Q}, \, +^{M _2}(n _1, n _2) = | n _1 - n _2 | \\
·^{M _2} : \mathbb{Q}^2 \longrightarrow \mathbb{Q}, \, ·^{M _2}(n _1, n _2) = n _1 \\
<^{M _2} : \mathbb{Q}^2 \longrightarrow Bool, \, <^{M _2} = \{(i,j): (i,j) \in \mathbb{Q^2} \wedge (i < j) \} \\
=^{M _2} : \mathbb{Q^2} \longrightarrow Bool, =^{M _2} = \{(i,i) : i \in \mathbb{N} \} \\
\end{array} \right.$
Recordemos que el predicado de igualdad es invariante en cualquier $L$-estructura y expresa la igualdad entre objetos.
## Interpretación de las fórmulas en LPO
Al igual que en LP extendimos los valores de verdad de las variables proposicionales (cuya semántica venía dada por las valoraciones) a las expresiones válidas del lenguaje (las fórmulas), en LPO podemos extender la interpretación de los símbolos básicos del lenguaje a las construcciones que podemos hacer en él: términos y fórmulas.
!!!note
Dada una $L$-estructura $\mathcal{M}$ a cada término término $t$ de $L$, **sin variables** , le corresponde un objeto o elemento de $M$, que viene dado por la interpretación de la $L$-estructura ($t^{\mathcal{M}}$), de forma que:
$$t^{\mathcal{M} } = \left \lbrace \begin{array}{ll}
c^{\mathcal{M} } & \textrm{si } t \equiv c \, (\textrm{con } c=cte) \\
f^{\mathcal{M} }(t _1^{\mathcal{M} }, \ldots, t _n^{\mathcal{M} }) & \textrm{si } t \equiv f(t _1, \ldots, t _n)
\end{array} \right.$$
Es decir, consiste, simplemente, en ir aplicando de forma sucesiva las interpretaciones de los elementos que forman el término (subiendo por el árbol de formación del término).
Y, haciendo uso de cómo interpretar los términos, podemos extender de forma similar las interpretaciones sobre las fórmulas para hablar de su satisfacción en $\mathcal{M}$:
!!!def:Fórmulas cerradas
Dada una $L$-estructura $\mathcal{M}$ decimos que una fórmula **cerrada**, $F$, de $L$, se satisface en $\mathcal{M}$ (o que $\mathcal{M}$ es modelo de $F$, y se denota por $\mathcal{M} \models F$) si se da alguno de los siguientes supuestos:
1. $F \equiv P(t _1, \ldots, t _n)$ y además $P^{ \mathcal{M} }(t _1^{\mathcal{M}}, \ldots, t _n^{\mathcal{M}}) = 1$ o, equivalentemente, $(t _1^{\mathcal{M}}, \ldots, t _n^{\mathcal{M}}) \in P^\mathcal{M}$.
2. $F \equiv \neg F _1$ y además $\mathcal{M} \not \models F _1$.
3. $F \equiv F _1 \vee F _2$ y se tiene que $\mathcal{M} \models F _1$ o $\mathcal{M} \models F _2$ (análogo para el resto de conectivas).
4. $F \equiv \exists x \, F _1$ y además hay algún elemento $e \in M$ (representado por el término $\boldsymbol{e}$) tal que $\mathcal{M} \models F _1 \{x/ \boldsymbol{e} \}$.
5. $F \equiv \forall x \, F _1$ y además todo elemento $e \in M$ (representado por el término $\boldsymbol{e}$) verifica $\mathcal{M} \models F _1 \{x/ \boldsymbol{e} \}$.
En caso de que $F$ no sea cerrada trabajaremos con lo se conoce como su cierre universal, es decir:
Si $F(x _1, \dots,x _n)$ tiene variables libres $\{x _1, \dots,x _n \}$ entonces diremos que $F$ se satisface en $\mathcal{M}$ (o que $\mathcal{M}$ es modelo de $F$, y se denota por $\mathcal{M} \models F$) si:
$$\mathcal{M} \models \forall x _1 \ldots \forall x _n \ F(x _1, \ldots, x _n)$$
!!!Tip:Ejemplos
En las estructuras que vimos antes para $LA$, vemos que las interpretaciones para $\mathcal{M} _1$ son las naturales (es decir, se interpretan como normalmente lo hacemos), pero $\mathcal{M} _2$ da interpretaciones básicas completamente distintas, por lo que produce una semántica diferente y, por ejemplo:
$$((\mathbf{0} \cdot \mathbf{1})+ \mathbf{1})^{M _1} = \mathbf{1}$$
$$\begin{array}{lcl}
((\mathbf{0} \cdot \mathbf{1})+ \mathbf{1})^{M _2} & = & (( \mathbf{0} \cdot \mathbf{1})^{M _2}+^{M _2} \mathbf{1}^{M _2}) \\
& = & ( \mathbf{0}^{M _2} \cdot^{M _2} \mathbf{1}^{M _2})-2 \\
& = & ( \frac{1}{2} \cdot^{M _2} 2)-2 \\
& = & \frac{1}{2}-2=- \frac{3}{2} \\
\end{array} $$
En virtud de la interpretación de este término en cada estructura, tenemos que:
$$\mathcal{M} _1 \models \mathbf{0} < (( \mathbf{0} \cdot \mathbf{1})+ \mathbf{1})$$
pero
$$\mathcal{M} _2 \not \models \mathbf{0} < (( \mathbf{0} \cdot \mathbf{1})+ \mathbf{1})$$
Así que vemos que, claramente, la veracidad de una fórmula concreta de un lenguaje LPO no depende solo de la fórmula y del universo, sino de la interpretación concreta de los símbolos del lenguaje en dicho universo.
# Satisfactibilidad, Validez y Consecuencia Lógica en LPO
Podemos extender los conceptos de **satisfactibilidad**, **validez** y **consecuencia lógica** de forma similar a como se dieron en LP:
!!!Def: Satisfactibilidad, Consistencia y Validez
En LPO se dice que una fórmula es **satisfactible** si existe, al menos, un modelo para dicha fórmula, esto es, si existe una $L$-estructura, $\mathcal{M}$, que verifica $\mathcal{M} \models F$.
Un conjunto de fórmulas, $\Sigma$, del lenguaje es **consistente** si existe una $L$-estructura, $\mathcal{M}$, que es modelo de todas las fórmulas de $\Sigma$.
Una fórmula se dice **lógicamente válida** si para toda $L$-estructura, $\mathcal{M}$, se tiene $\mathcal{M} \models F$.
Por último, en LPO se tiene que una fórmula $F$ es **consecuencia lógica** de un conjunto de fórmulas $\Sigma$ (y se denota por $\Sigma \models F$) si para toda $L$-estructura, $\mathcal{M}$, que verifique $\mathcal{M} \models \Sigma$ se tiene que $\mathcal{M} \models F$.
Obviamente, los Lenguajes de Primer Orden son mucho más expresivos que los proposicionales, pero hay que pagar algo a cambio. Al contrario que en LP, en el que existían algoritmos (aunque ineficientes) que permitían determinar **los problemas de consistencia, validez y consecuencia lógica, en LPO** estos mismos problemas **no son decidibles**, es decir, no existen algoritmos que permitan decidir, de forma completa, ninguno de ellos.
Durante los siguientes temas estudiaremos algoritmos que tratarán de resolver el problema, aunque en el caso de LPO sean soluciones parciales.