**Bases de Datos en Grafo**
En los últimos años ha aparecido una buena colección de bases de datos basadas en grafo para dar soluciones a diversos problemas que venían apareciendo en el mundo de las bases de datos clásicas. Algunas de estas soluciones se han convertido en productos disponibles en el mercado (como [Neo4j](http://www.neo4j.org/), [InfiniteGraph](http://www.objectivity.com/infinitegraph) o [Dex](http://www.sparsity-technologies.com/dex)), mientras que otras se han creado como soluciones particulares para ser integradas en sistemas que precisaban de soluciones inmediatas.
Pese a que el panorama se va aclarando y podemos hacernos una idea de qué opciones tenemos y qué propiedades tiene cada una de ellas, sigue quedando en un terreno más difuso cuándo puede ser conveniente usar una base de datos en grafo y cuándo no.
# ¿Qué es una Base de Datos en Grafo?
Una **Base de Datos en Grafo** (**BDG**, a partir de ahora) es una base de datos que tiene como propósito almacenar estructuras de datos que tienen topología de grafo, es decir, que la información que se almacena se puede representar por medio de nodos y aristas entre ellos.
Por definición, una BDG agruparía a cualquier solución de almacenamiento en la que los elementos que están conectados se enlazan sin hacer uso de una referencia por medio de índices (que sería el método habitual de *simular* una relación en una Base de Datos relacional), de esta forma, los vecinos de una entidad son accesibles directamente por ella por medio de una referencia directa, sin pasar por estructuras intermedias que hagan el proceso de *dereferenciado*. En esta definición no tenemos en cuenta el tipo de grafo (en su sentido más amplio) que nuestros datos seguirán, ni en el tipo de aristas (dirigidas o no), ni en la multiplicidad de las mismas entre dos nodos (unirelacional o multirelacional), ni en la aridad que reflejen las aristas (grafo o hipergrafo).
Por tanto, una BDG debe cumplir los siguientes criterios:
!!!side:1
Por ello, una BDG está optimizada para realizar consultas en los datos en las que intervengan relaciones de proximidad (conexiones) entre datos, y no para la realización de consultas globales.
* El almacenamiento está optimizado para **representar datos como un grafo**, proporcionando los nodos y las aristas que lo forman.
* El almacenamiento está optimizado para **realizar los traversals** a través del grafo, sin uso de índices que *representen* las aristas [1].
!!!side:2
El tipo de nodo o arista sería equivalente a las distintas tablas que se definen en un modelo relacional.
* El **modelo de datos es flexible**... lo que en algunas ocasiones nos permite no declarar tipos de nodos o de aristas [2].
* Integra funciones para aplicar los **algoritmos clásicos de la Teoría de Grafos** (caminos más cortos, $A^*$, medidas de centralidad, etc.)
# El movimiento NoSQL
!!!side:3
De hecho, muchas de las soluciones actuales son híbridas, y ofrecen simultáneamente, en un solo paquete, soluciones clásicas, SQL, con estas nuevas aproximaciones.
En los últimos años ha surgido un movimiento que pretende buscar soluciones a diversos problemas a los que las Bases de Datos Relacionales no han encontrado soluciones satisfactorias. Genéricamente, a todas estas soluciones alternativas se les ha dado el nombre de **NoSQL**, donde **No** no es una negación del SQL, sino un **Not only SQL**, en el sentido de que no pretenden rechazar el uso de las soluciones clásicas, sino de complementarlas allá donde no son capaces de llegar. Entre estos problemas, podemos destacar [3]:
* Disponibilidad para el procesamiento de grandes conjuntos de datos.
* Particionamiento de bases de datos.
* Mayor flexibilidad en el esquema de datos.
* Dificultad para modelar y procesar estructuras de datos complejas o con muchas relaciones.

Todavía no se ha presentado un modelo general de bases de datos que sea capaz de abordar de forma única todos los problemas anteriores, y han surgido diversas soluciones que atacan algunos de estos puntos. Las BDG se centran, principalmente, en la capacidad para tratar los dos últimos problemas:
* Tienen capacidad para procesar datos altamente conectados.
* Son capaces de manipular modelos de datos flexibles y muy complejos.
* Ofrecen unos rendimientos muy buenos en las operaciones locales y en los traversals del grafo.
# BDG vs BDR
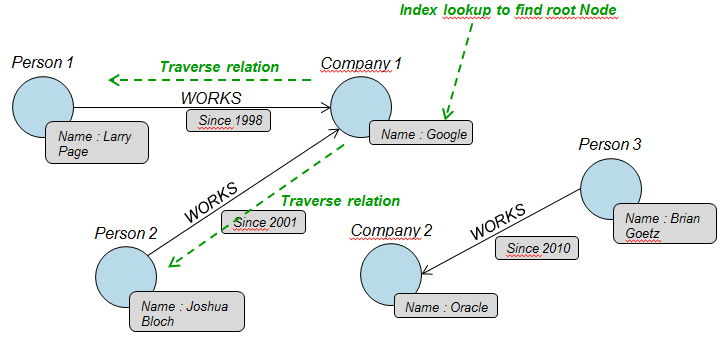
Sin duda, una BDG facilita en general la exploración de datos que tienen una estructura de grafo, especialmente cuando las relaciones entre esos datos son tan significativas como los datos mismos. El caso ideal de una consulta sería comenzar por uno o varios nodos y ejecutar un traversal en el grafo, y aunque es posible realizar consultas como *todos los nodos de un tipo*, estas se basan en el uso de tablas de índices para que los resultados sean óptimos. Sin embargo, incluso este tipo de consultas se podrían convertir en consultas locales en el grafo añadiendo al grafo un supernodo que reflejara cada uno de los tipos involucrados y conectándolo con todos los nodos de ese tipo.
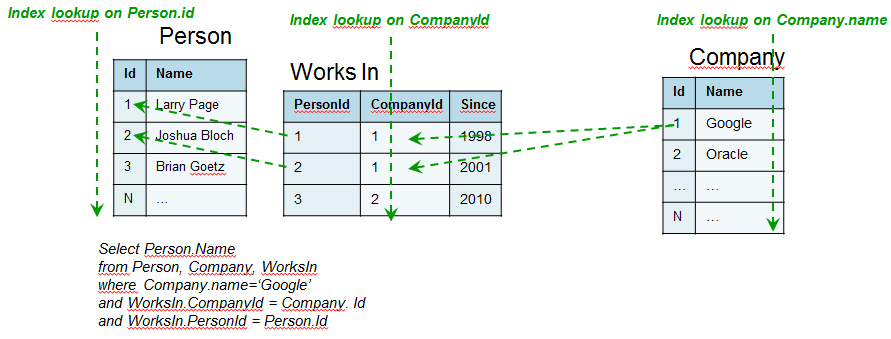
En contra, las BDR están especialmente diseñadas para ejecutar consultas de tipo más global, gracias a la estructura interna en forma de tablas. Sin embargo, a pesar de su nombre, estas bases de datos están poco preparadas para explorar relaciones de forma masiva, en donde necesita, por regla general, usar claves foráneas accediendo a tablas intermedias.
Aunque el siguiente ejemplo es muy simple, muestra un escenario en el que el rendimiento de una BDG es muy superior al de una BDR. En ambos casos tenemos la misma información (almacenada de distinta forma: tabla vs. grafo), y pretendemos extraer todos los trabajadores de una determinada empresa. En el caso de la BDR mostramos las referencias que es necesario extraer para poder recorrer las relaciones que hay entre los datos reales. Esta diferencia de rendimientos puede parecer algo inocente cuando se trabaja con pocos datos, pero a medida que el volumen se incrementa, esta diferencia se hace notable. A pesar de que muy probablemente en la primera parte de la consulta la BDG también deba mirar un índice para encontrar el nodo de origen, en el resto de los pasos se hace por uso directo de los punteros físicos que relacionan los nodos, mientras que en la BDR es necesario buscar en, al menos, un índice (a menudo, dos) cada una de las referencias buscadas (lo que habitualmente se hace en $O(log_2 N)$ si la indexación está correctamente hecha).
!!!side:4
Y facilidad de uso para definir la consulta concreta que queremos hacer.
En cualquier caso, comparar modelos de bases de datos entre sí suele ser un reto debido a las diferentes concepciones que tienen y a los problemas distintos que intentan resolver. Podemos decir que, en general, si el traversal que se usa como patrón de búsqueda es largo, las BDG son más eficientes que las BDR, pero si la consulta se puede estructurar mucho, entonces hay herramientas de optimización para BDR que pueden ofrecer resultados más eficientes. Uno de los casos en los que las BDR no pueden optimizar sus consultas es precisamente cuando la búsqueda es parametrizada y no se tiene a priori una forma estructurada uniforme, sino que depende de los resultados intermedios que se vayan obteniendo a medida que el traversal se va ejecutando. Un terreno donde las BDG muestran una capacidad muy superior [4].
# Comparación con herramientas de procesado
Una posible comparación que suele hacerse se produce entre las BDG y las herramientas específicas de análisis de grafos que han surgido recientemente. Se debe tener en cuenta que, a pesar de que ambas trabajan sobre estructuras en forma de grafo, el objetivo de ambas es completamente distinto y, por tanto, la forma de abordar desde un punto de vista técnico y logístico los datos, también. Si queremos reflejarlo en la diferenciación de un problema que caería dentro de cada uno, podríamos nombrar, por ejemplo:
* Navegar por un grafo de datos y encontrar un camino de longitud mínima entre dos nodos es una labor adecuada para una BDG.
* Encontrar medidas globales del grafo (como una medida de centralidad) es más adecuado para una herramienta de procesado.
Entre los problemas que se habían plenteado como complicados para la BDR todavía encontramos algunos que no son apropiados para una BDG, como por ejemplo el de partición de la BD en función de propiedades globales (presentando las mismas dificultades que se dan en una BDR), lo que complica poder trabajar con grandes volúmenes de datos. Pese a ello, se debe tener presente que sí proporciona soluciones para la mayoría de los problemas habituales, y que es capaz de almacenar cientos de millones de nodos en un servidor pequeño. Normalmente, se dará una relación entre el tamaño de la estructura de grafo que se puede manipular y la velocidad de respuesta para operaciones locales, de forma que las herramientas de procesado, que pueden manipular grafos mucho más grandes, tendrán lenta respuesta para estas preguntas y serán más eficientes para cálculos globales, mientras que las BDG tendrán muy poco tiempo de latencia en las búsquedas locales, pero mucho más ineficientes para dar respuestas globales.
# Modelo de Datos
!!!side:5
Esta afirmación es voluntaria y exageradamente simplista, pero refleja un hecho muy cercano al mundo real.
Por último, una característica en la que las BDG no tienen rival es en su facilidad para modelar y adaptarse a modelos cambiantes. En BDR, lo habitual tras diseñar un modelo de datos es pasar a normalizarlo para asegurarnos el correcto funcionamiento del modelo relacional sobre los datos, pero el modelado usando BDG es tan natural que el modelado puede hacerse sin conocimientos técnicos explícitos, puesto que el modelo de datos de la BDG y el de los datos que se quieren almacenar es, en la mayoría de los casos, el mismo [5].
# Como resultado, ¿qué solución elegir?
Como siempre suele ocurrir, no hay una respuesta sencilla a esta pregunta, y todo depende de cómo son los datos con los que tenemos que trabajar. Si tus datos tienen una estructura compleja que necesitas explorar con detalle, y en la que importan tanto las relaciones como los propios datos, entonces una BDG puede ser una buena elección. Si además quieres tener accesos en tiempo real y el volumen de datos no es excesivo, incluso puedes optar por una BDG que admita representación en memoria. Si, por contra, el volumen de datos es muy alto, también puedes hacer uso de una BDG, pero has de tener claro que el procesamiento de los datos posiblemente no funcione en tiempo real.
Por último, si no sabes qué necesidades tendrás, porque se irán destapando a medida que el proyecto avance, y no tienes muy claro el modelo de datos que seguirás, quizás la flexibilidad del esquema que te ofrecen las BDG puede ser un punto a favor. Recuerda que si una BD está bien construida no tiene porqué resultar complicada la conversión de un tipo de modelo en otro,... e incluso trabajar simultáneamente con varios modelos, conectados adecuadamente, de forma que las partes más relacionadas se almacenen en una BDG mientras que las más estructuradas lo hagan en una BDR.
Aquí es donde entramos en el principio de *Not only SQL*...
(insert menu.md.html here)