**Computación Científica y Julia**
La Computación Científica es una disciplina fundamental en el desarrollo moderno de la ciencia, que se sitúa en la intersección entre las matemáticas aplicadas, la informática y los dominios científicos tradicionales como la física, la biología o la economía. Su objetivo es resolver problemas complejos del mundo real mediante la terna de formulación de modelos matemáticos, implementación computacional y análisis numérico de los resultados.
Desde finales del siglo XX, la computación científica ha transformado profundamente el proceso de descubrimiento científico. Experimentos que antes requerían años de trabajo en laboratorios físicos hoy pueden simularse en cuestión de horas gracias al poder de cálculo de los ordenadores. Esta capacidad ha permitido explorar sistemas complejos —desde la dinámica de galaxias hasta la propagación de epidemias— que serían inaccesibles mediante métodos analíticos o experimentales tradicionales. Esta transformación está siendo acelerada por los nuevos modelos de Inteligencia Artificial (IA) y Aprendizaje Automático (ML), que están revolucionando la forma en que se analizan y comprenden los datos científicos. La IA y el ML permiten a los investigadores descubrir patrones ocultos, optimizar procesos y predecir comportamientos en sistemas complejos, lo que amplía aún más las fronteras del conocimiento científico.
Paralelamente, el desarrollo de lenguajes de programación ha sido crucial en este avance, al proporcionar herramientas cada vez más expresivas, eficientes y accesibles para científicos e ingenieros. En este contexto, Julia ha emergido como una solución innovadora diseñada específicamente para la computación científica. Julia combina la facilidad de uso de lenguajes como Python o MATLAB con el rendimiento de lenguajes compilados como C o Fortran. Esta combinación permite a los investigadores escribir código de alto nivel sin sacrificar la velocidad, facilitando el trabajo colaborativo, el prototipado rápido y la ejecución eficiente de algoritmos numéricamente intensivos.
Además, Julia ofrece características avanzadas como la tipificación múltiple, paralelismo nativo y un rico y vivo ecosistema de bibliotecas científicas. Estas cualidades han llevado a su adopción en áreas tan diversas como la simulación de sistemas físicos, el aprendizaje automático, la optimización y la estadística bayesiana. Sin embargo, su velocidad de adopción no es tan rápida como la de otros lenguajes, como Python, que ha dominado el campo de la ciencia de datos y el aprendizaje automático. Esto se debe en parte a la inercia de la comunidad científica y a la amplia disponibilidad de bibliotecas y recursos en Python.
# Sobre la Computación Científica (SC)
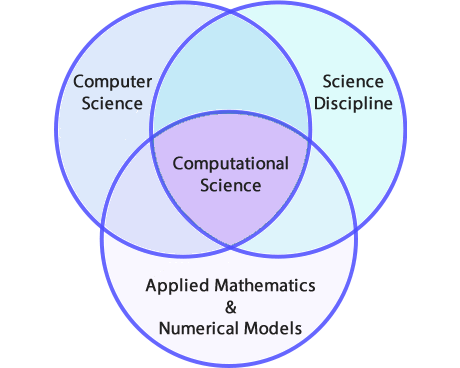
La **Computación Científica** es un campo multidisciplinario en rápido crecimiento que utiliza capacidades informáticas avanzadas para comprender y resolver problemas complejos. Es un área de la ciencia que abarca muchas disciplinas, pero en esencia implica el desarrollo de modelos y simulaciones para comprender los sistemas naturales. Podemos indicar las siguientes áreas principales de interés:
* Algoritmos (numéricos y no numéricos), modelado y simulación matemáticos y computacionales desarrollados para resolver problemas científicos (por ejemplo, biológicos, físicos y sociales), de ingeniería y de humanidades.
* Ciencias de la computación y de la información que desarrollan y optimizan los componentes avanzados de hardware, software, redes y gestión de datos del sistema necesarios para resolver problemas computacionalmente exigentes.
* La infraestructura informática que sustenta tanto la resolución de problemas científicos y de ingeniería como el desarrollo de las ciencias de la información y la computación.
En la práctica, se trata de la aplicación de técnicas como el modelado y la simulación por ordenador (y otras formas de computación derivadas del análisis numérico y la informática teórica) para resolver problemas en diversas disciplinas científicas con el fin de ampliar su comprensión, principalmente mediante el análisis de modelos matemáticos implementados en computadoras. En algunos casos, estos modelos requieren cantidades masivas de cálculos (generalmente de punto flotante) y suelen ejecutarse en supercomputadoras o plataformas de computación distribuida.
En este contexto, el término _científico computacional_ se utiliza para describir a una persona experta en computación científica... suele ser un científico, ingeniero o matemático que aplica la computación de alto rendimiento de diversas maneras para impulsar el estado del arte en sus respectivas disciplinas aplicadas. Un científico computacional debe ser capaz de:
* Reconocer problemas complejos.
* Conceptualizar adecuadamente el sistema que contiene estos problemas.
* Diseñar un marco de algoritmos adecuados para estudiar este sistema: la simulación.
* Elegir una infraestructura informática adecuada (computación paralela/computación en cuadrícula/supercomputadoras).
* Evaluar en qué nivel el resultado de la simulación se asemeja al sistema real: validación del modelo.
* Ajustar la conceptualización del sistema en consecuencia.
* Repetir el ciclo hasta obtener un nivel adecuado de validación: el científico computacional confía en que la simulación genere resultados adecuadamente realistas para el sistema, en las condiciones estudiadas.
La Computación Científica se considera actualmente una tercera columna de soporte para la ciencia, que complementa la _experimentación/observación_ y la _teoría_.
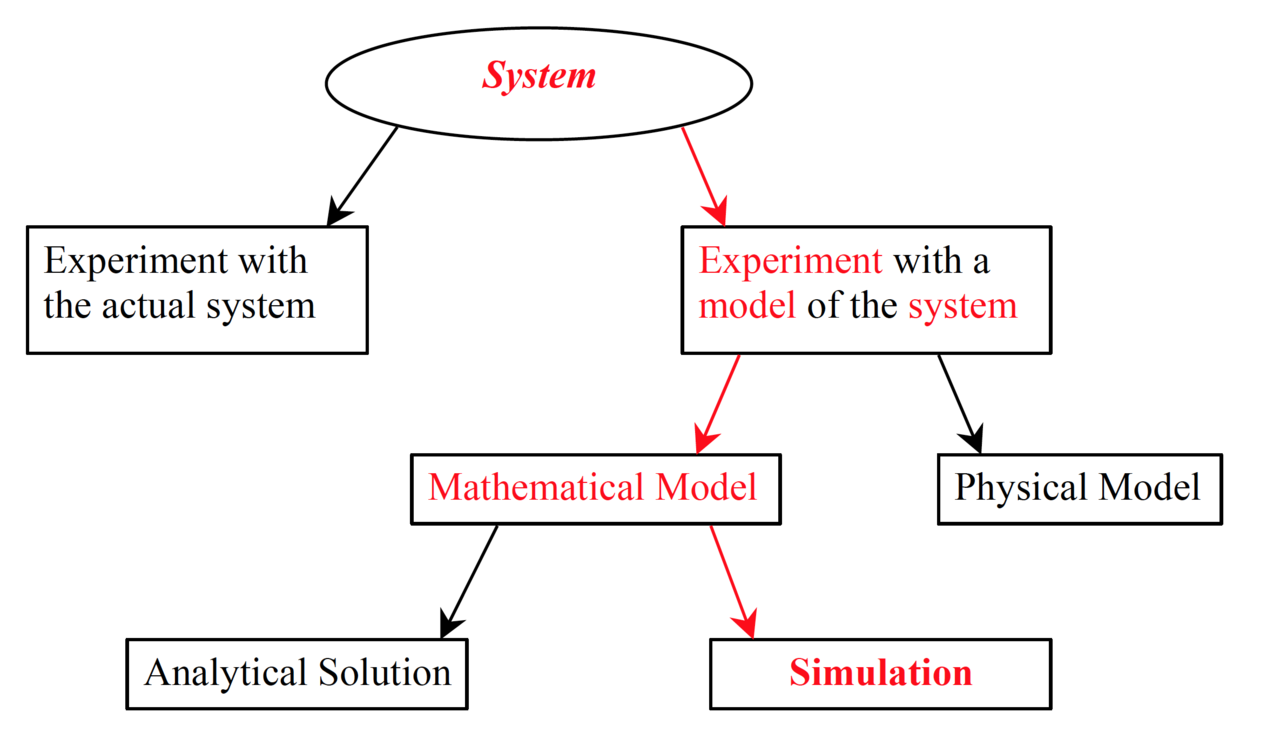
De hecho, un esfuerzo considerable en _Ciencias de la Computación_ se ha dedicado al desarrollo de algoritmos, la implementación eficiente en lenguajes de programación y la validación de resultados computacionales.
Es interesante apuntar que desde el punto de vista de la _Filosofía de las Ciencias_ se ha abordado la cuestión de hasta qué punto la SC puede considerarse Ciencia, abordando la cuestión general de la epistemología: cómo obtenemos información desde la SC. En cualquier caso, parece que las limitaciones que se encuentran son las habituales en la relación entre el conocimiento que se puede extraer del sistema original y de la simulación. Pero este problema se ve mitigado en cierta forma con la SC, ya que, a diferencia de otras aproximaciones, en ella se usan modelos matemáticos que representan la teoría subyacente de forma ejecutable.
## SC y Ciencia de Datos
Como hemos comentado, la SC estudia/desarrolla la aplicación de simulaciones por computadora, generalmente basadas en una combinación de modelos matemáticos y métodos numéricos, para resolver problemas en Ciencia e Ingeniería. Por otra parte, la Ciencia de Datos (DS) se refiere al análisis estadístico y la interpretación de datos resultantes de mediciones o simulaciones experimentales.
El aumento continuo en la potencia computacional disponible ha hecho posible simulaciones científicas a escala cada vez mayor que producen cantidades cada vez mayores de datos. En algunos casos, el procesamiento y la interpretación de estos datos se han convertido en un cuello de botella que limita la utilidad de las simulaciones. Al mismo tiempo, la creciente capacidad para registrar y almacenar flujos de datos en muchos entornos, por ejemplo, estaciones de monitoreo meteorológico, entornos minoristas, tráfico web en línea, etc., ha impulsado la necesidad de herramientas eficientes de DS. Estos desarrollos han creado nuevas oportunidades en el nexo de los ámbitos tradicionalmente separados de la SC y DS.
En cualquier caso, podemos dar el siguiente resumen de diferencias:
| Aspecto | Computación Científica | Ciencia de Datos |
|---------|------------------------|------------------|
| Enfoque | Modelado y simulación de sistemas físicos | Extracción de información a partir de datos |
| Técnicas Matemáticas | Métodos numéricos, EDO/EDP | Estadística, probabilidad, ML |
| Técnicas Informáticas | HPC, desarrollo de algoritmos | Manipulación de datos, ML, big data |
| Aplicaciones | Ingeniería, Física, Química,... | Analítica empresarial, ciencias sociales, salud |
Aunque ambos campos se basan en técnicas matemáticas y computacionales, sus objetivos y metodologías difieren considerablemente. SC se ocupa principalmente de resolver problemas científicos complejos mediante la simulación y el modelado, mientras que DS se centra en el análisis y la interpretación de datos para obtener información útil.
## SciML: SC + ML
El **Aprendizaje Automático Científico** (SciML) es un componente central de la Inteligencia Artificial (IA) y una tecnología computacional que puede entrenarse con datos científicos para aumentar o automatizar las habilidades humanas y transformar la investigación científica. La naturaleza transversal del ML y la IA proporciona un fuerte incentivo para formular una agenda de investigación priorizada que maximice las capacidades y los beneficios científicos.
Se debe tener presente que SciML no es ML estándar sino la combinación de técnicas de SC con ML. Por lo tanto, el objetivo no es diseñar bibliotecas de ML, sino el desarrollo de herramientas de SC que funcionen a la perfección junto con los flujos de trabajo de ML de próxima generación. Esto incluye:
* Herramientas de alto rendimiento y precisión para modelado y simulación de SC estándar.
* Compatibilidad con programación diferenciable y diferenciación automática.
* Herramientas para construir modelos complejos multiescala.
* Métodos para manejar problemas inversos, calibración de modelos, controles y análisis bayesiano.
* Herramientas de modelado simbólico para generar código eficiente para solucionadores de ecuaciones numéricas.
* Métodos para el descubrimiento automático de ecuaciones (bio)físicas.
La comunidad de SciML ha identificado seis direcciones prioritarias de investigación (PRD) que son fundamentales para el desarrollo de métodos SciML. Estas PRD se centran en la integración de la ciencia computacional y el aprendizaje automático, y abordan tanto los desafíos fundamentales como las capacidades necesarias para avanzar en el campo.
Los tres primeros PRD describen temas de investigación fundamentales que son comunes al desarrollo de todos los métodos SciML y corresponden a la necesidad de conocimiento del dominio, interpretabilidad y robustez. Los otros tres PRD describen temas de investigación sobre capacidades y corresponden a los tres principales casos de uso para el análisis masivo de datos científicos, el modelado simulación mejorados por ML, la automatización inteligente y el apoyo a la toma de decisiones para sistemas complejos:
1. **SciML consciente del dominio**. Es poco probable que los métodos de SciML lleguen a sustituir a los modelos establecidos basados en mecanismos físicos y conocimientos científicos; sin embargo, existe una importante oportunidad para que SciML complemente los modelos tradicionales. El conocimiento del dominio incluye principios físicos, simetrías, restricciones, opiniones de expertos, simulaciones computacionales, incertidumbres, etc. Por tanto, el objetivo de esta dirección es integrar dicho conocimiento con los métodos SciML, mejorando la precisión, interpretabilidad y defendibilidad de los modelos SciML, reduciendo al mismo tiempo los requisitos de datos y acelerando el entrenamiento de los modelos SciML. Para la consecución de estos objetivos se requieren nuevos métodos matemáticos para aprender características mejoradas del modelo que estén limitadas por el conocimiento del dominio, incluida la fusión de fuentes de datos multimodales y heterogéneas para extraer características.
2. **SciML interpretable**. Tradicionalmente, la comprensión física ha sido la base del modelado. La confianza de un usuario en las predicciones de un modelo está directamente vinculada a la convicción de que el modelo tiene en cuenta su conocimiento del dominio (por ejemplo, las variables, los parámetros y las leyes físicas correctas). En general, existe una tensión entre la necesidad de aumentar la complejidad de los modelos de ML para mejorar los resultados y la necesidad de que los usuarios interpreten los modelos y extraigan nuevas ideas y conclusiones. Este reto es ampliamente reconocido. Sin embargo, las aplicaciones SciML presentan retos y oportunidades únicos para utilizar el conocimiento del dominio existente con el fin de aumentar la interpretabilidad de los modelos ML. El progreso en esta dirección requiere el desarrollo de nuevos enfoques de exploración y visualización para interpretar modelos complejos utilizando el conocimiento del dominio, así como nuevas métricas para cuantificar las diferencias entre modelos.
3. **SciML robusto**. Para ocupar su lugar como metodología científica y ser aceptados para su uso común en ciencias y aplicaciones de alto riesgo, los métodos SciML deben ser robustos y fiables. Aunque los métodos de ML son muy utilizados, la integración de protocolos de verificación, validación y reproducibilidad están en pañales. La credibilidad de la investigación basada en SciML requiere que los resultados procedan de un proceso que no sea sensible a las perturbaciones en los datos de entrenamiento, la elección del modelo y/o los errores computacionales. El progreso en esta dirección requiere investigación para demostrar que los métodos e implementaciones de SciML están bien planteados y son estables y robustos.
4. **SciML intensivo en datos**. SciML en modelos y datos complejos a gran escala se enfrenta a una serie de retos, incluyendo datos de entrada de alta dimensión, ruidosos e inciertos, así como información limitada sobre la validez del modelo. La incorporación de la estadística, la cuantificación de la incertidumbre y la modelización probabilística en SciML proporciona un marco para gestionar algunos de estos retos. En particular, estos enfoques pueden abordar el mal condicionamiento, la no unicidad y el sobreajuste, y permitir la cuantificación de la incertidumbre requerida en las predicciones ML. Además, los métodos estadísticos y probabilísticos pueden ayudar a descubrir la estructura de los datos para mejorar la comprensión científica. Al mismo tiempo, la aplicación de estos métodos en SciML se ve dificultada por el gran volumen y complejidad de los datos, así como por la estructura altamente dimensional de los modelos probabilísticos SciML. El progreso en esta dirección requiere el desarrollo de métodos mejorados para el aprendizaje estadístico en sistemas SciML de alta dimensión con datos ruidosos y complejos, para identificar la estructura en datos complejos de alta dimensión, y para el muestreo eficiente en espacios paramétricos y de modelos de alta dimensión.
5. **Modelización y simulación mejoradas por ML**. Los códigos de simulación que modelan fenómenos físicos complejos, a menudo presentan variaciones drásticas de escala y comportamiento incluso dentro de una misma simulación. Para obtener rendimiento, robustez y fidelidad, la experiencia humana suele ser integral en el proceso de simulación para obtener soluciones de calidad. La tendencia creciente es que los modelos, discretizaciones y solucionadores numéricos en el corazón de los códigos de aplicación sean más adaptables, normalmente mediante el uso de controles teóricos simples y/o heurísticos. La utilización juiciosa de los algoritmos SciML (lo que se denominan en algunos ámbitos como modelos surrogados) para adaptar mejor los aspectos de los modelos numéricos y sus interacciones con el hardware informático, cada vez más complejo, puede reportar enormes beneficios. Del mismo modo, los algoritmos numéricos tradicionales están en el núcleo de los algoritmos SciML, por lo que SciML puede hacerse más eficiente, robusto y escalable aprovechando los amplios conocimientos de la comunidad de SC. Catalizar la interacción de la SC y los algoritmos de ML tiene el potencial de mejorar el rendimiento de ambos, pero se requiere el desarrollo de nuevos métodos para cuantificar las compensaciones y gestionar de forma óptima la interacción entre los modelos e implementaciones tradicionales y de ML.
6. **Automatización inteligente y apoyo a la toma de decisiones**. Las aplicaciones que iteran en torno a una simulación directa (por ejemplo, en optimización, cuantificación de la incertidumbre, problemas inversos, asimilación de datos y control) constituyen un objetivo importante para muchas de las capacidades de simulación y modelización, en muchos casos en apoyo de decisiones. En la frontera de las decisiones basadas en la simulación en Ciencia e Ingeniería se plantean varios retos importantes: cómo hacer manejable la tarea de evaluar un modelo de simulación complejo y costoso en un espacio de parámetros de alta dimensión; cómo combinar mejor los datos experimentales y de simulación para fundamentar las decisiones; cómo validar las evaluaciones resultantes y traducir su incertidumbre en confianza cuantificable para un responsable de la toma de decisiones; y cómo gestionar la interacción entre la automatización y la toma de decisiones humana. Estos retos son especialmente acuciantes para SciML. Además de los avances en las anteriores direcciones, también se requieren nuevos métodos matemática y científicamente justificados para guiar la adquisición de datos y garantizar su calidad y adecuación, métodos SciML mejorados para los datos multimodales que se encuentran en las aplicaciones científicas, y nuevos métodos para cuantificar las compensaciones y gestionar de forma óptima los recursos utilizados en el apoyo a la toma de decisiones y las tareas relacionadas.
Estas seis direcciones prioritarias proporcionan una base sólida para aplicar una estrategia de investigación y desarrollo coherente y a largo plazo. Afortunadamente, durante las 2 últimas décadas, las matemáticas y la SC han marcado algunas directrices para el tipo de investigación básica que puede sostener los avances necesarios.
# Julia para Computación Científica
La combinación de velocidad, facilidad de uso y capacidades numéricas avanzadas de Julia lo convierte en una opción destacada para la computación numérica y científica. Ya sea para manipular matrices, resolver ecuaciones diferenciales o realizar simulaciones a gran escala, Julia proporciona las herramientas y la eficiencia necesarias para abordar problemas complejos. Su creciente ecosistema y su activa comunidad garantizan la innovación continua y el soporte para aplicaciones de vanguardia.
Históricamente, Python ha sido el lenguaje dominante para la investigación en ML, incluso en el ámbito científico. Python es intuitivo y cuenta con un rico ecosistema en todas las ciencias naturales. Sin embargo, su auge como lenguaje de referencia para el ML ha sido, en muchos sentidos, antinatural. Python es un lenguaje de _scripting_, extremadamente lento y difícil de mantener. La llegada de Julia se diseñó, en muchos sentidos, para abordar estas limitaciones de Python. Julia cuenta con un conjunto de características a nivel de lenguaje diseñadas para cálculos numéricos intuitivos y rápidos que superan con creces las capacidades de Python.
Desde la introducción de Julia en 2012, el lenguaje ha experimentado un crecimiento constante entre los profesionales. Dada la intención específica de Julia de resolver problemas en SciML, es natural preguntarse por qué Julia no ha desafiado a Python en popularidad dentro de las ciencias naturales. Parte de esto se puede atribuir al impulso que Python ha acumulado a lo largo de los años dentro de la comunidad. Sin embargo, con el rápido crecimiento del SciML en los últimos años, está por verse si Julia experimentará una adopción más amplia.
En cualquier caso, resulta interesante explorar la idoneidad de Julia como herramienta clave para SciML. Para ello, es importante centrarse no solo en la amplia gama de bibliotecas disponibles, sino también en su rendimiento, filosofía de diseño y ergonomía general. Un tema clave es que los diferentes lenguajes de programación proporcionan diferentes abstracciones que cambian significativamente la forma en que un usuario interactúa con un problema de SciML, y Julia ofrece un conjunto de abstracciones muy diferente al de otros ecosistemas.
A pesar de todo esto, y aunque el ecosistema de Julia ofrece multitud de abstracciones útiles para este tipo de problemas, parece que presenta algunas limitaciones que son lo suficientemente graves como para impedir su adopción generalizada. Intentaremos describirlas a lo largo del texto.
## Áreas y características
Hay multitud de proyectos que se desarrollan en Julia y que, haciendo uso de sus capacidades en cuanto a computación numérica han demostrado su utilidad en el ámbito de la SC. Algunos áreas fundamentales en las que podemos encontrar usos de Julia son:
1. **Investigación científica**: ampliamente en física computacional, biología, bioinformática, astronomía y química.
2. **DS y ML**: la integración del lenguaje con los marcos de ML y AI lo convierte en una opción ideal para investigación y desarrollo.
3. **Finanzas**: Julia se utiliza para finanzas cuantitativas, modelado de riesgos y comercio algorítmico.
4. **Problemas de optimización**: simplifica el modelado y la resolución de problemas de optimización.
5. **Simulación**: simulaciones de Monte Carlo, métodos de elementos finitos y simulaciones de sistemas dinámicos.
Todos estos proyectos tienen en común un uso intensivo de computación numérica, lo que hace que Julia sea una elección ideal. A continuación se presentan algunas características clave de Julia que la hacen destacar en estos ámbitos:
* **Alto rendimiento**: El rendimiento de Julia es comparable al de lenguajes de tipado estático como C y Fortran. Esta velocidad se logra mediante varias decisiones de diseño clave, como la _compilación Just-In-Time_ (JIT) por medio de LLVM (máquina virtual de bajo nivel) para compilar el código en código de máquina nativo eficiente justo antes de la ejecución; una _inferencia de tipos_ agresiva para optimizar la ejecución; y una _gestión eficiente de la memoria_, garantizando una sobrecarga mínima de recolección de basura en tiempo de ejcución.
* **Tipado dinámico** con anotaciones de tipo robustas que mejoran la claridad del código y permiten al compilador generar código máquina optimizado.
* **Bibliotecas numéricas** que incluyen funcionalidades de Álgebra lineal (soporte nativo para operaciones con vectores, matrices y tensores, incluidas factorizaciones de matrices, autovalores y descomposición en valores singulares), Generación de números aleatorios (con capacidades potentes y extensibles que hacen que Julia sea ideal para simulaciones) y Funciones especiales (implementaciones eficientes de funciones matemáticas como funciones de Bessel, Gamma, etc.).
* **Despacho Múltiple**, que permite especializar las funciones según el tipo y el número de sus argumentos, lo que resulta especialmente útil en computación numérica.
* **Paralelismo nativo**, que incluye _multithreading_ (para paralelismo de memoria compartida), _computación distribuida_ (para cálculos a gran escala en múltiples máquinas) y compatibilidad con GPU (no solo CUDA).
* **Sintaxis de alto nivel**, que de forma concisa y expresiva facilita la traducción directa de fórmulas matemáticas a código (usando Unicode de forma extensiva).
* **Interoperabilidad**, que le permite integrarse con otros lenguajes como Python, R y C/C++.
* **Análisis de datos**, con una amplia gama de paquetes para la manipulación y visualización de datos. Como `DataFrames.jl` (similar a `Pandas` de Python), `Plots.jl` (una biblioteca de visualización versátil que se integra con múltiples backends, incluidos `GR`, `PyPlot` y `Plotly`).
* **Metaprogramación**, lo que permite a los usuarios generar y manipular código dinámicamente. Esto puede ser especialmente ventajoso en computación numérica para automatizar tareas repetitivas.
* **Ecosistema de código abierto y extensible**, con un dinámico ecosistema de paquetes que está creciendo rápidamente. Algunos paquetes destacados para el procesamiento numérico incluyen: `DifferentialEquations.jl` (EDOs y EDPs), `JuMP.jl` (problemas de optimización), `Flux.jl` (aprendizaje profundo), `Distributions.jl` (distribuciones estadísticas), etc.
## Comparativa de ecosistemas
Teniendo en cuenta que su uso depende, en mayor o menor medida, de la elección que se haga frente a otros lenguajes para la resolución de problemas habituales en SC, vamos a comparar los ecosistemas de Julia con sus contemporáneos, principalmente con Python, ya que es la opción preferida por la mayoría de los investigadores que trabajan con SC (lenguajes como C, C++, Fortran y Cuda tienen un uso similar a menor escala).
### Álgebra lineal
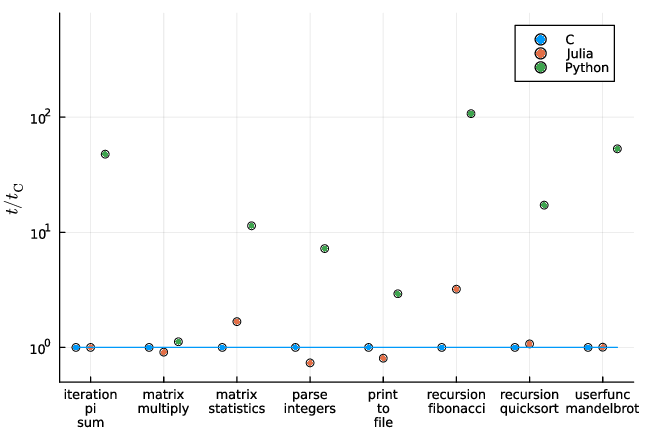
Podría decirse que la parte más importante del ecosistema de Julia es la biblioteca estándar para álgebra lineal. Los cálculos numéricos rápidos motivaron la creación de Julia. Para lograrlo, Julia emplea un compilador Just-in-Time (JIT) para acelerar su velocidad de cálculo y cuya utilidad se puede observa en todos los usos del lenguaje, pero especialmente en su biblioteca de álgebra lineal. Por ejemplo, Julia es significativamente más rápida que Python y casi tan rápida como C en términos de multiplicación de matrices aleatorias y estadísticas de matrices aleatorias. Aunque las operaciones matriciales de Python se pueden compilar JIT con Jax, la mejora exacta del rendimiento en comparación con C o Julia aún no se ha evaluado adecuadamente. Julia también cuenta con una gran cantidad de funciones fáciles de usar para la factorización de matrices y bibliotecas para trabajar con grafos dispersos que pueden agilizar aún más las operaciones con matrices.
### Optimización restringida
De forma similar al álgebra lineal numérica, los algoritmos de optimización restringida se integran bien con el resto de fortalezas de Julia. Estos algoritmos son rápidos y matemáticamente sólidos, y en comparación con Python, mucho más completos.
Julia ofrece el soporte más sofisticado para especificar problemas de optimización en variedades. Normalmente, los enfoques ingenuos para resolver problemas de SC no tienen en cuenta los sesgos inductivos ni las restricciones físicas. Un enfoque para incorporar restricciones físicas a un problema es especificar una variedad en la que residen los datos. Esto se implementa en Julia con `Manopt` que, aunque tiene versiones para Python y Matlab, éstas ofrecen solo un subconjunto estricto de lo que ofrece en Julia. La adaptación de Python, en particular, es muy limitada, y los paquetes similares en R y C++ no se mantienen de forma activa.
`Manopt` está diseñado para restringir las actualizaciones iterativas y mantenerlas en una variedad específica. Sin embargo, a menudo las restricciones se especifican de forma flexible mediante funciones de pérdida, como en el caso de las _Redes Neuronales Basadas en Física_ (PINN), que pueden considerar las condiciones iniciales y de contorno al resolver una ley física especificada como una ecuación diferencial. Julia gestiona este tipo de particularidades de forma excelente con `Flux.jl` y `Lux.jl`, que proporcionan backends de redes neuronales compatibles con los paquetes `DiffEqFlux.jl` y `NeuralPDE.jl`. Incluso más allá de los métodos neuronales, Julia cuenta con un ecosistema extremadamente rico para resolver ecuaciones diferenciales. `Lux.jl`, por ejemplo, admite tipos arbitrarios, lo que lo hace compatible con solucionadores de EDO/EDP arbitrarios e incluso con otros lenguajes. Por el contrario, no existen soluciones de facto para el aprendizaje automático basado en la física en Python. Es decir, ninguna solución existente se adapta a las redes neuronales especificadas en TensorFlow, Haiku, o PyTorch simultáneamente. Como resultado, observamos arquitecturas estándar distribuidas en diferentes subecosistemas sin bibliotecas disponibles para conectarlas. Por ejemplo, observamos las implementaciones canónicas para _redes neuronales lagrangianas_ y de normalización de flujos implementado en Jax, y las implementaciones canónicas de _Kolmogorov Arnold Networks_ (KAN) y redes de operadores profundos implementado en PyTorch.
Julia completa su conjunto de bibliotecas de optimización restringida con `GeometricFlux.jl`, que se basa nuevamente en el marco `Flux.jl`, y `GraphNeuralNetworks.jl`, con capas y funcionalidades específicas para los objetos de _Geometric DL_, que incluyen grafos, conjuntos, mallas, espacios euclidianos, grupos y espacios homogéneos, geodésicas y variedades, y todas las funcionalidades de Geometría Algebráica. Al igual que con los PINN, estas mismas funcionalidades aparecen dispersas en diferentes bibliotecas de Jax y Torch, que a menudo son incompatibles entre sí. Esta compatibilidad convierte a Julia en una opción muy atractiva para trabajar con problemas de SciML.
### Diferenciación automática
Julia mantiene varios paquetes diferentes para la _diferenciación automática_ (AD) tanto en _modo directo_ como en _modo inverso_ con `ForwardDiff.jl` y `Zygote.jl`, respectivamente. En otros ecosistemas, los diversos modos de AD se manejan normalmente dentro de la misma biblioteca, como es el caso de PyTorch y Jax. En general, las bibliotecas de AD de Julia tienen un alcance mucho más ambicioso, lo que permite una mayor sobrecarga del usuario a costa de la posible facilidad de uso.
Debido a esta sobrecarga, se suele identificar esta como una de las pocas áreas donde existe mucha fricción al escribir código de Julia. Una forma de lograrlo es mediante intervenciones y definiciones de gradientes personalizadas. En Julia, las macros para anular y especificar reglas de diferenciación se encuentran en varias bibliotecas independientes, incluyendo el propio `Zygote.jl` y la biblioteca de propósito general `DiffRules.jl`. Navegar por la complejidad de las diferentes herramientas suele ser contraintuitivo y requiere un conocimiento del dominio mucho mayor que con otras herramientas. En cambio, las reglas de diferenciación personalizadas son muy fáciles en Jax con las macros `@custom_JVP` y `@custom_VJP`.
`Zygote.jl` se utiliza principalmente como backend de la biblioteca de aprendizaje automático `Flux.jl`. Además, las herramientas de diferenciación automática mencionadas anteriormente también permiten usar `Optim.jl` con `SymbolicRegressions.jl`, donde Julia ofrece una clara ventaja en términos de soporte. De hecho, la alternativa de Python, `PySR`, es simplemente un contenedor para esta biblioteca, que a su vez es una dependencia de PyTorch.
### Programación probabilística
Julia cuenta con numerosos lenguajes de _programación probabilística_ (PPL) que hacen que los problemas con estadística bayesiana sean extremadamente fáciles de expresar e incluyen paquetes como `SOSS.jl` y `Turing.jl`. SOSS.jl proporciona un conjunto único de herramientas para trabajar con objetos de la _Teoría de la Medida_ que no se encuentras en otros lenguajes. Salvo por el soporte teórico, existe una biblioteca similar en Python con `PyAutoFit`, y en Jax `NumPyro` hace que sea excepcionalmente fácil especificar problemas probabilísticos.
## Filosofía de diseño
Julia se fundó sobre claros ideales de diseño que han conformado su estructura interna y sus fortalezas. Algunos de estas directrices son:
### Despacho múltiple
Julia hace un uso extensivo del _Despacho Múltiple_, un método para seleccionar automáticamente el comportamiento de una función según los tipos de entrada y que, en la práctica, puede hacer que la escritura de código sea mucho más ergonómica para el usuario final. Por ejemplo, la biblioteca de Python/C++ para calcular funciones de correlación, `TreeCorr`, tiene 18 diferentes subclases que el usuario debe recordar para correlacionar distintos tipos de objetos (por ejemplo, `KVCorrelation` para correlaciones escalar-vector y `VVCorrelation` para correlaciones vector-vector). Obviamente, puede ser difícil recordarlas todas. Con el despacho múltiple de Julia podemos definir con seguridad la misma función 18 veces para los diferentes tipos de entradas sin tener que preocuparnos por especificar cuál llamar en la práctica. Bibliotecas como `JuMP.jl`, `ForwardDiff.jl` y la biblioteca estándar de Julia hacen un uso extensivo del despacho múltiple.
Los siguiente contenidos desplegables profundizan un poco en cómo funciona el despacho múltiple, ya que es una característica distintiva de Julia frente al uso de ls otras alternativas más usuales.
!!!note:Dos vías tradicionales
Los elementos fundamentales con los que se construye una solución en un lenguaje de programación son _funciones/programas_, _tipos de datos_ y _bibliotecas/módulos/paquetes_. Brevemente:
* Las funciones o programas son procedimientos para tomar alguna entrada, hacer algo con ella y producir alguna salida.
* Los tipos de datos son colecciones de unidades de información (atómica o estructurada) sobre los que operan las funciones.
* Las bibliotecas, paquetes y módulos son colecciones de funciones, junto con descripciones de los tipos de datos con los que trabajan, agrupadas para realizar un conjunto de tareas relacionadas. Por ejemplo, un conjunto de funciones para dibujar gráficos, donde las funciones individuales podrían ser para dibujar diferentes tipos de gráficos (circulares e histogramas) y el tipo de dato para un gráfico circular sería, por ejemplo, una lista de pares de elementos, donde el primero es una palabra o frase y el segundo un porcentaje.
Ahora que está de moda el mundo de la cocina, podemos dar una analogía muy intuitiva de esta misma división en este ámbito:
* La biblioteca o el paquete se convierte en el recetario (un libro centrado en la preparación de postres o sopas, por ejemplo).
* Las funciones o programas pueden considerarse recetas completas para preparar un plato o técnicas o procedimientos, como saltear. Podemos visualizarlos como engranajes, ya que son la maquinaria para procesar las materias primas.
* Los tipos de datos son las materias primas con las que construir los platos.
La diferencia entre _lenguajes de la cocina_ vendrá dado por cómo podemos organizar nuestro recetario.
Imaginemos que nuestro recetario está organizado de tal manera que las recetas solo funcionan con ciertos ingredientes. Por ejemplo, podemos buscar _cómo saltear_ y encontrar el procedimiento para saltear cebollas o camarones. Todos estos procedimientos son diferentes, ya que utilizan ingredientes distintos. Si las recetas funcionan como un lenguaje de programación, las listas de ingredientes forman parte de ellas y, de hecho, están incluidas en ellas.
Si queremos actualizar nuestro recetario añadiendo una nueva receta o describiendo una nueva técnica (por ejemplo, cosas que se pueden hacer con una licuadora), es sencillo añadir las nuevas recetas. Simplemente escribe una nueva que describa los ingredientes de interés, incluyendo aquellos que puedan formar parte de otras recetas existentes.
No será necesario revisar ninguna de las recetas existentes: _agregar nuevas recetas no significa que las antiguas queden obsoletas_.
¿Y si queremos incorporar un ingrediente nuevo? Sin duda, podemos crear recetas completamente nuevas con él. Pero si ninguna de las recetas anteriores del libro menciona pescado, tendremos que revisarlas si queremos incorporarlo. Nos veremos obligados a modificar el trabajo que ya hemos realizado.
Sin embargo, hay más de una manera de organizar un recetario. ¿Qué pasaría si se organizara en torno a los ingredientes, en lugar de a los métodos de cocción? Para cada ingrediente, habría un conjunto de técnicas o métodos que lo acompañan. Aquí los métodos no existen por sí solos, sino que están vinculados a los ingredientes con los que se utilizan. Ahora es fácil añadir un nuevo ingrediente.
 Si la versión revisada de nuestro recetario necesita una receta de pescado, simplemente escribimos los procedimientos para su manipulación y agrupamos esa información con el pescado en un paquete ordenado.
Podemos añadir ingredientes al libro sin tener que modificar ninguna receta existente, que siguen siendo perfectamente utilizables. ¿Pero qué pasa si queremos añadir una nueva técnica al libro? ¿Y si la versión revisada pretende mostrarte lo que puedes hacer con la licuadora?
No podemos añadir nuevas técnicas sin modificar el trabajo ya realizado, ya que los métodos ahora están empaquetados dentro de los ingredientes. Para añadir un método novedoso, necesitamos modificar nuestros paquetes previamente ordenados y modificar los métodos ya escritos dependiendo del ingrediente al que se va a aplicar.
Estas dos formas de organizar un recetario son análogas a dos tipos de lenguajes de programación:
* Los recetarios organizados en torno a procedimientos están escritos en un _lenguaje funcional_.
* Los organizados en torno a ingredientes están escritos en un _lenguaje orientado a objetos_.
En un caso, no se pueden añadir nuevos ingredientes sin reescribir los procedimientos existentes, mientras que en otro caso no se pueden añadir nuevos procedimientos sin reescribir el trabajo existente.
Para repasar la terminología del diseño de lenguajes de programación:
* En un lenguaje funcional, se pueden añadir nuevas funciones sin modificar las existentes, pero añadir nuevos tipos de datos implica reescribir las existentes.
* En un lenguaje orientado a objetos, se pueden añadir nuevos tipos de datos a voluntad, pero si se quieren añadir nuevas funciones es necesario rediseñar los objetos existentes.
El problema es que, al usar cualquiera de estos paradigmas tradicionales, existen obstáculos para extender un paquete (libro de recetas) a nuevos dominios, y aún más obstáculos para combinar paquetes existentes de nuevas maneras. Que un paquete pueda extenderse sin modificar lo ya existente es crucial a la hora de reutilizar y combinar código existente, que que permite a los autores de bibliotecas escribir código de forma genérica, sin tener que mantener versiones especiales para cada aplicación, y permite a los usuarios finales extender módulos existentes sin introducir los errores que inevitablemente aparecen al realizar modificaciones y sin tener que mantener versiones privadas de cada biblioteca.
!!!note:Una tercera vía
Obviamente, si hubiera una manera de organizar el recetario de forma que pudiera ampliarse libremente para incluir nuevos ingredientes y métodos, añadiendo contenido al libro sin modificar lo ya escrito, sería una gran ventaja. En lugar de organizar el libro estrictamente en torno a métodos o ingredientes, quizá exista una forma más general y flexible.
Este diagrama pretende sugerir la libre asociación de métodos con ingredientes, sin subordinar uno al otro. Los engranajes repetidos en diferentes colores sugieren que, en lugar de una colección aleatoria de funciones no relacionadas, normalmente crearíamos variaciones de funciones existentes para operar con diferentes conjuntos de ingredientes.
Por ejemplo, nuestro recetario hipotético y ampliable podría contener un procedimiento para freír pollo. Si queremos ampliarlo añadiendo un procedimiento para freír pescado, no necesitamos empezar desde cero: podemos escribir nuestro procedimiento para freír pescado indicando al lector que proceda igual que con el pollo, pero a una temperatura ligeramente superior y que retire el ingrediente después de 10 minutos, en lugar de 30.
Otra forma de comprender las tres formas de organizar un recetario en este experimento mental es imaginar cómo sería el índice en cada caso. Un extracto del contenido de la versión _funcional_ podría ser algo como:
```none
Capítulo 1: Freír
Pollo
Pez
Capítulo 2: Ebullición
Pollo
Remolachas
```
Podemos agregar un nuevo método simplemente agregando un nuevo capítulo, mientras que agregar un nuevo ingrediente significa editar los capítulos existentes.
El índice de la versión _orientada a objetos_ podría ser algo como:
```none
Capítulo 1: Pollo
Fritura
Hirviendo
Capítulo 2: Remolachas
Hirviendo
Salteado
```
Ahora podemos agregar un nuevo ingrediente agregando un nuevo capítulo, pero agregar un nuevo método significa editar capítulos ya terminados.
El índice de nuestro tercer enfoque sería:
```none
Capítulo 1: Pollo frito
Capítulo 2: Pollo hervido
Capítulo 3: Hervir la remolacha
Capítulo 4: Salteado de remolacha
```
Es evidente que cualquier procedimiento aplicado a cualquier ingrediente o conjunto de ingredientes puede añadirse como un nuevo capítulo, sin necesidad de modificar los capítulos existentes. Se pueden añadir libremente nuevos métodos e ingredientes.
Esta versión final podría parecer desorganizada en comparación con las otras dos, pero en una biblioteca de software real las relaciones entre los métodos y los ingredientes formarían parte de la estructura de la biblioteca. En nuestra metáfora del libro de cocina, el pollo y el pescado serían subconjuntos de la carne, las fresas y las cerezas podrían clasificarse como subconjuntos de los frutos rojos, freír y saltear podrían considerarse variaciones de un método más general, y así sucesivamente.
Esta tercera vía de organización es una metáfora de lo que, en diseño de lenguajes, se denomina _despacho múltiple_, un término que simplemente se refiere a la selección automática de un método en función de los tipos de datos a los que se aplica.
El despacho múltiple es la solución de Julia al problema de la organización. Es central al lenguaje, que, por lo tanto, no es ni orientado a objetos ni funcional, sino algo más potente y general que ambas aproximaciones. Es la fórmula mágica que le da a Julia el poder de simplificar lo que resulta tan difícil en la mayoría de los demás lenguajes: la combinación libre y directa de bibliotecas para realizar tareas que no fueron imaginadas por quienes las escribieron.
!!!ejemplo:Ejemplo: Series temporales y finanzas
Vamos a crear un ejemplo que muestre cómo podemos definir nuestros propios tipos y extender funcionalidades de librerías existentes en Julia mediante el despacho múltiple. En concreto, vamos a crear un tipo de dato para representar series temporales y extender algunas funciones de las librerías estándar de Julia para trabajar con este nuevo tipo.
Vamos a definir dos tipos personalizados nuevos:
- `TimeSeries`: Para representar una serie temporal con fechas, valores y un nombre
- `FinancialData`: Para agrupar varias series temporales financieras (precios de apertura, cierre, etc.)
```Julia
using Statistics # Librería estándar para operaciones estadísticas
using Dates # Librería estándar para manejo de fechas
using LinearAlgebra # Librería estándar para operaciones con matrices
# Definimos un tipo personalizado para representar una serie temporal
struct TimeSeries{T<:Number}
dates::Vector{Date}
values::Vector{T}
name::String
# Constructor interno para validación
function TimeSeries(dates::Vector{Date}, values::Vector{T}, name::String) where T<:Number
if length(dates) != length(values)
throw(ArgumentError("Las fechas y valores deben tener la misma longitud"))
end
new{T}(dates, values, name)
end
end
# Definimos otro tipo para representar un dataset financiero
struct FinancialData
ticker::String
open::TimeSeries{Float64}
high::TimeSeries{Float64}
low::TimeSeries{Float64}
close::TimeSeries{Float64}
volume::TimeSeries{Int}
end
```
A continuación, extendemos algunas funciones de las librerías estándar de Julia para trabajar con nuestro nuevo tipo `TimeSeries`. Esto nos permitirá usar funciones como `mean`, `std`, y operadores como `+` y `*` directamente con nuestras series temporales.
Comenzamos por extender algunas funciones de la librería `Statistics` para calcular la media y la desviación estándar de una serie temporal.
```Julia
# Extendemos la función `mean` de Statistics
import Statistics: mean
function mean(ts::TimeSeries)
println("Calculando media de la serie temporal '$(ts.name)'")
return mean(ts.values)
end
# Extendemos la función `std` (desviación estándar) de Statistics
import Statistics: std
function std(ts::TimeSeries)
println("Calculando desviación estándar de la serie temporal '$(ts.name)'")
return std(ts.values)
end
```
Luego, extendemos algunos operadores básicos para que funcionen con nuestras series temporales. Por ejemplo, podemos sumar dos series temporales o multiplicar una serie por un escalar.
```Julia
# Extendemos la función `+` para combinar series temporales
import Base: +
function +(ts1::TimeSeries{T}, ts2::TimeSeries{T}) where T<:Number
# Verificamos que las fechas coincidan
if ts1.dates != ts2.dates
throw(ArgumentError("Las series temporales deben tener las mismas fechas"))
end
new_values = ts1.values .+ ts2.values
new_name = "$(ts1.name) + $(ts2.name)"
println("Sumando series temporales '$(ts1.name)' y '$(ts2.name)'")
return TimeSeries(ts1.dates, new_values, new_name)
end
# Extendemos la función `-` para restar series temporales
import Base: -
function -(ts1::TimeSeries{T}, ts2::TimeSeries{T}) where T<:Number
# Verificamos que las fechas coincidan
if ts1.dates != ts2.dates
throw(ArgumentError("Las series temporales deben tener las mismas fechas"))
end
new_values = ts1.values .- ts2.values
new_name = "$(ts1.name) - $(ts2.name)"
println("Restando series temporales '$(ts1.name)' y '$(ts2.name)'")
return TimeSeries(ts1.dates, new_values, new_name)
end
# Extendemos el operador * para multiplicar una serie temporal por un escalar
import Base: *
function *(scalar::Number, ts::TimeSeries{T}) where T<:Number
new_values = scalar .* ts.values
new_name = "$(scalar) * $(ts.name)"
println("Multiplicando serie temporal '$(ts.name)' por $scalar")
return TimeSeries(ts.dates, new_values, new_name)
end
# Implementación simétrica para permitir ts * scalar
function *(ts::TimeSeries{T}, scalar::Number) where T<:Number
return scalar * ts
end
# Extendemos la función `getindex` para poder indexar series temporales
import Base: getindex
function getindex(ts::TimeSeries, i)
println("Accediendo al índice $i de la serie temporal '$(ts.name)'")
return (ts.dates[i], ts.values[i])
end
# Extendemos la función `getindex` para permitir rangos de fechas
function getindex(ts::TimeSeries, date_range::StepRange{Date})
start_date = date_range.start
end_date = date_range.stop
indices = findall(d -> start_date <= d <= end_date, ts.dates)
if isempty(indices)
throw(ArgumentError("No hay datos para el rango de fechas especificado"))
end
println("Extrayendo datos de '$(ts.name)' para el rango $(start_date) a $(end_date)")
return TimeSeries(ts.dates[indices], ts.values[indices], ts.name)
end
# Extendemos la función `size` para obtener dimensiones de nuestra serie temporal
import Base: size
function size(ts::TimeSeries)
println("Obteniendo tamaño de la serie temporal '$(ts.name)'")
return (length(ts.dates),)
end
```
Finalmente, extendemos algunas funciones de la librería `LinearAlgebra` para calcular la norma de una serie temporal y también agregamos funciones personalizadas para calcular retornos logarítmicos y proporcionar un resumen estadístico de la serie temporal.
```Julia
# Extendemos función para calcular retornos logarítmicos
function log_returns(ts::TimeSeries{T}) where T<:Number
if length(ts.values) < 2
throw(ArgumentError("Se necesitan al menos dos valores para calcular retornos"))
end
# Calculamos log(p_t / p_{t-1})
new_dates = ts.dates[2:end]
new_values = log.(ts.values[2:end] ./ ts.values[1:end-1])
new_name = "log_returns($(ts.name))"
println("Calculando retornos logarítmicos de '$(ts.name)'")
return TimeSeries(new_dates, new_values, new_name)
end
# Extendemos función `describe` para dar un resumen estadístico
function describe(ts::TimeSeries)
println("Estadísticas de la serie temporal '$(ts.name)':")
println(" - Número de observaciones: $(length(ts.values))")
println(" - Rango de fechas: $(minimum(ts.dates)) a $(maximum(ts.dates))")
println(" - Media: $(mean(ts.values))")
println(" - Desv. estándar: $(std(ts.values))")
println(" - Mínimo: $(minimum(ts.values))")
println(" - Máximo: $(maximum(ts.values))")
end
# Extendemos la función `norm` de LinearAlgebra para calcular la norma de una serie temporal
import LinearAlgebra: norm
function norm(ts::TimeSeries{T}) where T<:Number
println("Calculando norma de la serie temporal '$(ts.name)'")
return norm(ts.values)
end
```
En resumen, el ejemplo extiende tres librerías estándar de Julia y agrega funcionalidades específicas para trabajar con series temporales. Aquí hay un resumen de lo que hemos hecho:
1. **Statistics**: Extiende funciones estadísticas para que trabajen con nuestro tipo `TimeSeries`:
- `mean(ts::TimeSeries)`: Calcula la media de los valores
- `std(ts::TimeSeries)`: Calcula la desviación estándar
2. **Base**: Extiende operadores básicos y funciones fundamentales:
- Operador `+`: Para sumar series temporales
- Operador `*`: Para multiplicar series por escalares
- Función `getindex`: Para indexar por posición o rango de fechas
- Función `size`: Para obtener dimensiones
3. **LinearAlgebra**: Extiende funciones matemáticas más avanzadas:
- `norm(ts::TimeSeries)`: Calcula la norma de los valores
4. **Funciones personalizadas**: funciones específicas para análisis financiero:
- `log_returns`: Calcula retornos logarítmicos
- `describe`: Proporciona un resumen estadístico completo
Esta aproximación presenta varias ventajas:
1. **Código expresivo**: Podemos escribir código como `mean(ts_cierre)` o `ts_cierre + ts_apertura` que es intuitivo y legible.
2. **Integración perfecta**: Nuestros tipos se integran de forma natural con el ecosistema de Julia.
3. **Especialización**: Podemos adaptar algoritmos generales para que funcionen de manera óptima con nuestros tipos.
4. **Extensibilidad**: Cualquier usuario puede extender más funciones sin modificar nuestro código original.
Podemos probar nuestras extensiones creando algunos datos de ejemplo y aplicando las funciones que hemos definido:
```Julia
# Creamos datos de ejemplo
fechas = Date(2023, 1, 1):Day(1):Date(2023, 1, 10)
precios_apertura = [100.0, 101.5, 102.3, 101.8, 103.5, 104.2, 103.8, 105.1, 106.3, 105.8]
precios_cierre = [101.2, 102.1, 101.9, 103.2, 104.0, 103.7, 104.9, 106.0, 105.5, 107.2]
volumen = [15000, 18200, 14500, 22000, 19000, 17500, 21000, 23500, 20000, 25000]
# Creamos series temporales
ts_apertura = TimeSeries(collect(fechas), precios_apertura, "Precio Apertura")
ts_cierre = TimeSeries(collect(fechas), precios_cierre, "Precio Cierre")
ts_volumen = TimeSeries(collect(fechas), volumen, "Volumen")
# Probemos nuestras extensiones
println("\n=== Extendiendo Statistics ===")
println("Media de precios de apertura: $(mean(ts_apertura))")
println("Desviación estándar de precios de cierre: $(std(ts_cierre))")
println("\n=== Extendiendo operadores aritméticos ===")
spread = ts_cierre - ts_apertura
println("Media del spread (cierre - apertura): $(mean(spread))")
println("\n=== Multiplicación por escalar ===")
ts_apertura_ajustada = 1.01 * ts_apertura # Ajuste del 1%
println("Media de precios ajustados: $(mean(ts_apertura_ajustada))")
println("\n=== Indexación ===")
fecha, valor = ts_cierre[5]
println("Precio de cierre del $(fecha): $(valor)")
println("\n=== Filtrado por rango de fechas ===")
rango_fechas = Date(2023, 1, 3):Day(1):Date(2023, 1, 7)
ts_cierre_rango = ts_cierre[rango_fechas]
println("Tamaño del rango filtrado: $(size(ts_cierre_rango)[1])")
println("\n=== Calculando retornos logarítmicos ===")
retornos = log_returns(ts_cierre)
println("Primera fecha de retornos: $(retornos.dates[1])")
println("Primer valor de retorno: $(retornos.values[1])")
println("\n=== Resumen estadístico ===")
describe(ts_cierre)
println("\n=== Usando LinearAlgebra ===")
println("Norma de los precios de cierre: $(norm(ts_cierre))")
```
Esta es una de las grandes fortalezas de Julia: la capacidad de extender las funcionalidades existentes de forma elegante mediante multiple dispatch, permitiendo que nuestros tipos personalizados se integren perfectamente con el resto del ecosistema.
Este breve ejemplo transmite parte del poder de los tipos de datos personalizados y la posibilidad de usar código preexistente para trabajar con ellos.
Por supuesto, hay cientos de casos como este. Por ejemplo, existe un paquete de Julia para mediciones u otros números con incertidumbres, y existen paquetes que resuelven ecuaciones diferenciales. Se pueden combinar para generar soluciones con incertidumbres, y al solicitar la gráfica de una ecuación, se obtiene un gráfico de su solución con barras de error que muestran la incertidumbre, combinando así tres bibliotecas que no fueron diseñadas para funcionar conjuntamente y sin necesidad de modificar ninguna de ellas. También existe una biblioteca de Julia para los números exóticos llamados _cuaterniones_, que tienen cuatro componentes (como versiones ampliadas de los números complejos), y se puede usar el solucionador de ecuaciones diferenciales con estos números, combinado con el paquete de mediciones, y al representar las soluciones, se obtiene un gráfico con cuatro líneas, cada una con barras de error que repersenta cada una de las componentes del cuaternión.
### Composición vs. Herencia
La filosofía de diseño y las guías de estilo de Julia giran en torno a la idea de interfaces altamente componibles. Esto, naturalmente, se basa en el uso de despacho múltiple: las funciones no se asocian a una sola estructura, sino que se declaran globalmente, posiblemente varias veces para diferentes tipos.
Un ejemplo de esto se puede ver en `Flux.jl`. Una red neuronal en `Flux.jl` es simplemente una cadena de funciones que pueden actuar sobre diferentes tipos. Esto hace que `Flux.jl` sea mucho más ergonómico, ya que abstrae los diferentes tipos de entrada que se pueden proporcionar a una red neuronal, eliminando la necesidad de extender un módulo y formatear los datos de entrada de una manera específica (es decir, como se haría con PyTorch).
El énfasis en la composición también es útil para la gestión de paquetes. Como hay muy poco estado compartido entre diferentes estructuras definidas por el usuario debido al despacho múltiple, es menos probable que los paquetes entren en conflicto. Incluso cuando hay conflictos, el gestor de paquetes de Julia, `Pkg.jl` es mucho más fácil de usar. Por el contrario, la gestión de paquetes de Python, que depende de la gestión del entorno virtual de Python con `Pip` o `Conda`, es notoriamente propensa a errores.
La composibilidad es un principio fundamental en el lenguaje de programación Julia, que contrasta con el modelo de herencia utilizado en muchos lenguajes orientados a objetos. Te mostraré un ejemplo claro que ilustra cómo funciona la composibilidad en Julia.
En Julia, en lugar de crear jerarquías de clases mediante herencia, se construyen comportamientos complejos mediante la composición de tipos y funciones más pequeñas.
!!!ejemplo:Ejemplo: Sistema de formas geométricas
Como hemos comentado, la composibilidad es un principio fundamental en Julia, que contrasta con el modelo de herencia utilizado en muchos lenguajes orientados a objetos. Vamos a mostrar un ejemplo claro que ilustra cómo funciona la composibilidad.
En Julia, en lugar de crear jerarquías de clases mediante herencia, se construyen comportamientos complejos mediante la composición de tipos y funciones más pequeñas.
Imaginemos que queremos crear un sistema para trabajar con diferentes formas geométricas.
**En un lenguaje basado en herencia** (como Java o Python), lo normal es que definamos una clase base `Forma` y luego subclases como `Círculo`, `Rectángulo`, etc. que heredan de ella:
```python
# Enfoque de herencia (Python)
class Forma:
def area(self):
pass
class Círculo(Forma):
def __init__(self, radio):
self.radio = radio
def area(self):
return 3.14159 * self.radio * self.radio
class Rectángulo(Forma):
def __init__(self, ancho, alto):
self.ancho = ancho
self.alto = alto
def area(self):
return self.ancho * self.alto
```
**En Julia, usando composibilidad**, el enfoque es diferente:
1. Definimos tipos para representar nuestras estructuras de datos.
2. Implementamos funciones genéricas que operan sobre estos tipos.
3. El comportamiento emerge de la composición de tipos y funciones.
```julia
# Enfoque de composibilidad (Julia)
# Definimos tipos simples
struct Círculo
radio::Float64
end
struct Rectángulo
ancho::Float64
alto::Float64
end
# Definimos una función genérica que trabaja con ambos tipos
function área(c::Círculo)
return π * c.radio^2
end
function área(r::Rectángulo)
return r.ancho * r.alto
end
# Ahora podemos usar estos tipos y funciones
mi_círculo = Círculo(5.0)
mi_rectángulo = Rectángulo(4.0, 6.0)
println("Área del círculo: $(área(mi_círculo))")
println("Área del rectángulo: $(área(mi_rectángulo))")
# Podemos componer nuevas funcionalidades fácilmente
function perímetro(c::Círculo)
return 2π * c.radio
end
function perímetro(r::Rectángulo)
return 2 * (r.ancho + r.alto)
end
# Podemos crear una función que trabaje con cualquier forma
function info_forma(forma)
println("Área: $(área(forma))")
println("Perímetro: $(perímetro(forma))")
end
```
Podemos destacar las siguientes ventajas de la composibilidad en Julia:
1. **Despacho múltiple**: Las funciones se seleccionan basándose en todos sus argumentos, no solo en el primer argumento como en la programación orientada a objetos tradicional.
2. **Extensibilidad**: Se pueden añadir nuevos métodos para tipos existentes sin modificar su definición original:
```julia
# Podemos añadir nuevas funcionalidades sin modificar las definiciones originales
function diagonal(r::Rectángulo)
return sqrt(r.ancho^2 + r.alto^2)
end
# Incluso podemos extender tipos de la librería estándar
import Base: *
function *(escala::Number, c::Círculo)
return Círculo(escala * c.radio)
end
círculo_grande = 2 * mi_círculo # Círculo con radio 10.0
```
3. **Combinación flexible**: Se pueden combinar comportamientos sin necesidad de jerarquías complejas de herencia:
```julia
# Podemos crear un tipo que contenga múltiples formas
struct GrupoFormas
formas::Vector{Any}
end
# Y definir comportamientos compuestos
function área_total(grupo::GrupoFormas)
return sum(área(forma) for forma in grupo.formas)
end
mis_formas = GrupoFormas([mi_círculo, mi_rectángulo])
println("Área total: $(área_total(mis_formas))")
```
Este enfoque de composibilidad es más flexible que la herencia tradicional, ya que evita problemas como la herencia múltiple y permite extender tipos y comportamientos de forma más modular. Además, permite que el sistema de tipos de Julia sea más eficiente y que el compilador genere código optimizado para cada combinación específica de tipos.
### El problema de los dos lenguajes
El problema de los dos lenguajes plantea que un lenguaje de programación es rápido o fácil de usar, pero no ambas cosas. Por lo tanto, a menudo se escribe código crítico para el rendimiento en C o C++ y se llama desde Python. Esto dificulta el mantenimiento de los proyectos, ya que ahora existen múltiples entornos que el usuario debe controlar. Y también dificulta la reproducibilidad y la contribución, ya que requiere que todos en la comunidad científica conozcan un segundo lenguaje técnico de bajo nivel.
El ejemplo más claro de este hecho es PyTorch, que es una interfaz de Python para un backend de C++. Sin embargo, incluso las bibliotecas que ofrecen una funcionalidad mucho más simple que una red neuronal presentan este problema. Por ejemplo, `TreeCorr` también tiene una API de Python para funciones escritas en C++. Julia afirma resolver el problema de los dos lenguajes, permitiendo tanto la creación flexible de prototipos como una optimización profunda del rendimiento dentro del mismo lenguaje. Por ejemplo, las bibliotecas `Flux.jl` y `CosmoCorr.jl` pueden entrenar redes neuronales de forma eficiente y estimar funciones de correlación, todo ello con código Julia de alto nivel. En general, la interacción entre el prototipado y la optimización es un patrón de diseño fundamental al implementar soluciones, y el diseño de Julia facilita excepcionalmente esta interacción.
!!!ejemplo:Ejemplo: Cálculo de la distancia de Mandelbrot
Consideremos un algoritmo para calcular la distancia de escape en el conjunto de Mandelbrot, un problema computacionalmente intensivo típico en matemáticas.
**El enfoque tradicional con dos lenguajes**
**Versión Python (fácil de escribir pero lento):**
```python
def mandelbrot_distance(c, max_iter):
z = 0
for i in range(max_iter):
z = z*z + c
if abs(z) > 2:
return i
return max_iter
def generate_mandelbrot(width, height, x_min, x_max, y_min, y_max, max_iter):
result = []
for y in range(height):
for x in range(width):
# Mapear pixel a coordenadas complejas
real = x_min + (x_max - x_min) * x / (width - 1)
imag = y_min + (y_max - y_min) * y / (height - 1)
c = complex(real, imag)
# Calcular distancia
distance = mandelbrot_distance(c, max_iter)
result.append(distance)
return result
```
**Versión C++ (para optimizar el rendimiento):**
```cpp
#include
#include
int mandelbrot_distance(std::complex c, int max_iter) {
std::complex z(0, 0);
for (int i = 0; i < max_iter; i++) {
z = z*z + c;
if (std::abs(z) > 2.0)
return i;
}
return max_iter;
}
std::vector generate_mandelbrot(int width, int height,
double x_min, double x_max,
double y_min, double y_max,
int max_iter) {
std::vector result;
result.reserve(width * height);
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
// Mapear pixel a coordenadas complejas
double real = x_min + (x_max - x_min) * x / (width - 1);
double imag = y_min + (y_max - y_min) * y / (height - 1);
std::complex c(real, imag);
// Calcular distancia
int distance = mandelbrot_distance(c, max_iter);
result.push_back(distance);
}
}
return result;
}
```
La integración de ambos lenguajes generalmente requiere código adicional para vincular Python con C++ (usando bibliotecas como Cython, ctypes, pybind11, etc.), lo que aumenta la complejidad del proyecto.
**La solución de Julia: un solo lenguaje**
En Julia, podemos escribir código que es tan claro y conciso como Python, pero que se ejecuta tan rápido como C++:
```julia
function mandelbrot_distance(c, max_iter)
z = 0 + 0im
for i in 1:max_iter
z = z^2 + c
if abs(z) > 2
return i
end
end
return max_iter
end
function generate_mandelbrot(width, height, x_min, x_max, y_min, y_max, max_iter)
result = zeros(Int, height, width)
for y in 1:height
for x in 1:width
# Mapear pixel a coordenadas complejas
real = x_min + (x_max - x_min) * (x-1) / (width-1)
imag = y_min + (y_max - y_min) * (y-1) / (height-1)
c = complex(real, imag)
# Calcular distancia
result[y, x] = mandelbrot_distance(c, max_iter)
end
end
return result
end
# Ejemplo de uso
width, height = 1000, 1000
x_min, x_max = -2.0, 0.5
y_min, y_max = -1.25, 1.25
max_iter = 1000
# Medición del tiempo de ejecución
@time mandelbrot = generate_mandelbrot(width, height, x_min, x_max, y_min, y_max, max_iter);
```
**Demostración del rendimiento**
Para ilustrar cómo Julia resuelve el problema de los dos lenguajes, podemos comparar el rendimiento:
```julia
# En Julia, podemos medir el tiempo de ejecución para diferentes implementaciones
# 1. Versión con tipos estáticos explícitos (opcional en Julia)
function mandelbrot_typed(width::Int, height::Int,
x_min::Float64, x_max::Float64,
y_min::Float64, y_max::Float64,
max_iter::Int)
result = zeros(Int, height, width)
for y in 1:height
for x in 1:width
real = x_min + (x_max - x_min) * (x-1) / (width-1)
imag = y_min + (y_max - y_min) * (y-1) / (height-1)
c = complex(real, imag)
result[y, x] = mandelbrot_distance(c, max_iter)
end
end
return result
end
# 2. Versión optimizada con operaciones vectorizadas
function mandelbrot_vectorized(width, height, x_min, x_max, y_min, y_max, max_iter)
# Crear matrices de coordenadas
real_coords = [x_min + (x_max - x_min) * (x-1) / (width-1) for x in 1:width]
imag_coords = [y_min + (y_max - y_min) * (y-1) / (height-1) for y in 1:height]
# Calcular todas las coordenadas complejas a la vez
c = [complex(r, i) for i in imag_coords, r in real_coords]
# Aplicar mandelbrot_distance a cada elemento
return map(z -> mandelbrot_distance(z, max_iter), c)
end
# Comparar rendimiento
println("Versión básica:")
@time generate_mandelbrot(width, height, x_min, x_max, y_min, y_max, max_iter);
println("\nVersión con tipos explícitos:")
@time mandelbrot_typed(width, height, x_min, x_max, y_min, y_max, max_iter);
println("\nVersión vectorizada:")
@time mandelbrot_vectorized(width, height, x_min, x_max, y_min, y_max, max_iter);
```
El tiempo de ejecución de los 3 procedimientos es similar, lo que desmuestra que el compilador de Julia puede optimizar el código para que funcione de manera eficiente, incluso si no se especifican tipos explícitos. Esto es posible gracias a la naturaleza dinámica y al sistema de tipos de Julia, que permite al compilador inferir los tipos en tiempo de compilación.
!!!ejemplo:Ejemplo: Multplicación de matrices
Pongamos un ejemplo en el que sí se observan mejoras sustanciales pero haciendo cambios (refactorizando) desde Julia, sin tener que salir a u lenguaje adicional pensado para velocidad (como C).
La multiplicación de matrices es un buen ejemplo para demostrar las diferencias de rendimiento entre implementaciones ingenuas y optimizadas, y cómo Julia cierra la brecha del problema de los dos lenguajes.
```julia
using BenchmarkTools
# 1. Implementación ingenua (estilo Python/MATLAB)
function mul_matrices_ingenua(A, B)
m, n = size(A)
n, p = size(B)
C = zeros(eltype(A), m, p)
for i in 1:m
for j in 1:p
for k in 1:n
C[i,j] += A[i,k] * B[k,j]
end
end
end
return C
end
# 2. Implementación mejorada (con optimizaciones manuales)
function mul_matrices_optimizada(A, B)
m, n = size(A)
n, p = size(B)
C = zeros(eltype(A), m, p)
# Pre-acceder a las columnas de B para mejorar la localidad de caché
B_cols = [view(B, :, j) for j in 1:p]
for i in 1:m
A_row = view(A, i, :)
for j in 1:p
B_col = B_cols[j]
s = 0.0
for k in 1:n
s += A_row[k] * B_col[k]
end
C[i,j] = s
end
end
return C
end
# 3. Usando la función incorporada de Julia
function mul_matrices_nativa(A, B)
return A * B
end
# Tamaño de las matrices
n = 1000
A = rand(n, n)
B = rand(n, n)
# Comparar tiempos
println("Método ingenuo (estilo Python/MATLAB):")
@btime mul_matrices_ingenua($A, $B);
println("\nMétodo optimizado manualmente:")
@btime mul_matrices_optimizada($A, $B);
println("\nMétodo nativo de Julia:")
@btime mul_matrices_nativa($A, $B);
# Verificar que los resultados son equivalentes
C1 = mul_matrices_ingenua(A, B)
C2 = mul_matrices_optimizada(A, B)
C3 = mul_matrices_nativa(A, B)
println("\nLos resultados son equivalentes: ",
isapprox(C1, C2) && isapprox(C2, C3))
```
Al ejecutar este código, se pueden ver diferencias de rendimiento significativas:
1. La versión ingenua será mucho más lenta (segundos o decenas de segundos).
2. La versión optimizada manualmente será mejor pero aún no óptima.
3. La versión nativa de Julia será órdenes de magnitud más rápida (milisegundos).
Para comprender mejor cómo Julia resuelve el problema de los dos lenguajes, consideremos el enfoque tradicional:
* En Python: El código ingenuo para multiplicación de matrices sería muy lento (segundos o minutos para matrices grandes).
* Solución tradicional: Reescribir el código en C/C++ o usar NumPy (que internamente usa código C optimizado).
* Con Julia: El código ingenuo es ya relativamente rápido (comparado con Python puro). Se puede optimizar incrementalmente dentro del mismo lenguaje. Las funciones nativas de Julia son tan rápidas como las implementaciones en C/C++.
## La importancia de las herramientas
Julia no es el primer lenguaje en abordar estos problemas de organización, ni siquiera el primero en resolverlo mediante despacho múltiple. _Common Lisp_ ha contado con estas características durante 40 años. Otros lenguajes, como las versiones recientes de _Perl_, también cuentan con esta característica, y sus usuarios han escrito sobre cómo facilita enormemente la composición y extensión de bibliotecas. Una diferencia es que Julia está diseñada en torno al despacho múltiple, que en otros lenguajes es opcional y cuyo uso conlleva penalizaciones de rendimiento. El diseño del despacho múltiple se concibió para que el lenguaje fuera flexible y pudiera expresar ideas matemáticas de forma natural, pero incluso sus diseñadores se sorprendieron por la gran cantidad de reutilización de código resultante en la comunidad.
Claramente, el despacho múltiple, o alguna otra forma de solucionar el problema de organización, es necesario para el tipo de componibilidad fluida que hemos descrito anteriormente, pero no es suficiente. Julia ha tenido una gran aceptación en la comunidad científica porque combina esta característica con varias otras que la hacen muy atractiva. Permite generar código rápido desde el primer momento, sin necesidad de pasar por obstáculos.
Julia tiene una sintaxis expresiva y fácil de leer y cuenta con la ventaja de haber sido diseñada en la era de Unicode. Esto, junto con otras características sintácticas, permite que las matemáticas escritas en Julia se parezcan más a las matemáticas _reales_ que en cualquier otro lenguaje de programación:

!!!note: Uso de Unicode
Julia facilita la escritura de código matemático con apariencia similar a la notación matemática tradicional gracias a su amplio soporte de caracteres Unicode. Esto hace que el código sea más legible y cercano a las expresiones matemáticas formales.
**Consejos para usar Unicode en Julia**
1. **Completado con TAB**: Escribe el nombre LaTeX del símbolo precedido por `\` y presiona TAB.
- Ejemplo: `\alpha` + TAB → `α`
2. **Algunos símbolos comunes**:
- Letras griegas: `\alpha`, `\beta`, `\gamma`, `\delta`, `\epsilon`, etc.
- Operadores: `\sum`, `\prod`, `\int`, `\partial`, `\nabla`
- Comparadores: `\le`, `\ge`, `\ne`, `\approx`, `\equiv`
- Conjuntos: `\cup`, `\cap`, `\in`, `\notin`, `\subset`
- Subíndices y superíndices: `\_`, `\^`
3. **Caracteres especiales en el REPL de Julia**:
- Escribe `?` y luego presiona TAB dos veces para ver una lista completa de símbolos disponibles
- La ayuda del REPL también muestra cómo escribir símbolos específicos
Veamos un ejemplo completo que muestra varias formas de usar Unicode en Julia para representar conceptos matemáticos:
```julia
# Símbolos matemáticos en Julia usando Unicode
# Letras griegas
α = 0.5 # Alpha: escribir \alpha + TAB
β = 2.0 # Beta: escribir \beta + TAB
γ = 1.5 # Gamma: escribir \gamma + TAB
Δ = 0.1 # Delta mayúscula: escribir \Delta + TAB
π # Pi: escribir \pi + TAB (predefinido en Julia)
# Operadores matemáticos
x₁ = 10 # Subíndice: escribir x\\_1 + TAB
y² = 100 # Superíndice: escribir y\^2 + TAB
z₃⁴ = 81 # Combinación de sub y superíndices
# Operadores de conjuntos
A ∩ B # Intersección: escribir \cap + TAB
A ∪ B # Unión: escribir \cup + TAB
A ⊆ B # Subconjunto: escribir \subseteq + TAB
x ∈ A # Pertenencia: escribir \in + TAB
x ∉ B # No pertenencia: escribir \notin + TAB
# Símbolos de cálculo e integrales
∫ f(x) dx # Integral: escribir \int + TAB
∑_{i=1}^n i # Suma: escribir \sum + TAB
∂f/∂x # Derivada parcial: escribir \partial + TAB
∇f # Gradiente (nabla): escribir \nabla + TAB
# Comparadores
x ≤ y # Menor o igual: escribir \le + TAB
x ≥ y # Mayor o igual: escribir \ge + TAB
x ≠ y # Distinto: escribir \ne + TAB
x ≈ y # Aproximadamente igual: escribir \approx + TAB
# Ejemplo completo: resolver una ecuación cuadrática
function resolver_ecuación(a, b, c)
Δ = b² - 4a*c
if Δ < 0
return "No hay soluciones reales"
elseif Δ == 0
x₁ = -b/(2a)
return "Solución única: x = $x₁"
else
x₁ = (-b + √Δ)/(2a) # √ es el símbolo de raíz: escribir \sqrt + TAB
x₂ = (-b - √Δ)/(2a)
return "Dos soluciones: x₁ = $x₁, x₂ = $x₂"
end
end
# Ejemplo: resolver αx² + βx + γ = 0
println(resolver_ecuación(α, β, γ))
# Definición de función con notación matemática
function integral_aproximada(f, a, b, n)
h = (b-a)/n
∑ = 0.0
for i in 1:n
x = a + i*h
∑ += f(x)
end
return h * ∑
end
# Cálculo de π usando la integral ∫₀¹ 4/(1+x²) dx
π_aproximado = integral_aproximada(x -> 4/(1+x^2), 0, 1, 1000)
println("Valor aproximado de π ≈ $π_aproximado")
println("Error: |π - π_aproximado| ≈ $(abs(π - π_aproximado))")
```
Aquí hay un ejemplo más avanzado que muestra el cálculo matricial con notación matemática:
```julia
# Álgebra lineal con notación Unicode
using LinearAlgebra
# Matrices con notación especial
A = [1 2; 3 4]
B = [5 6; 7 8]
# Producto tensorial
A ⊗ B # Escribir \otimes + TAB
# Multiplicación de matrices
C = A * B
C′ # Transpuesta: escribir C\' + TAB
C† # Conjugada transpuesta: escribir C\dagger + TAB
# Valores propios y vectores propios
λ, ⃗v = eigen(A) # λ (lambda): escribir \lambda + TAB
# ⃗v (vector): escribir \vec + TAB
# Determinante y traza
det_A = det(A) # |A| en matemáticas
tr_A = tr(A) # Traza
# Norma de un vector
‖x‖₂ = norm([3, 4]) # ‖ ‖ escribir \|| + TAB
# Solución de sistemas lineales
x = A \ [1, 2] # Solución de Ax = [1, 2]
```
Ejemplo con ecuaciones diferenciales:
```julia
# Ecuaciones diferenciales con notación Unicode
using DifferentialEquations
# Definir una ecuación diferencial: dx/dt = αx - βx²
function logística!(dx, x, p, t)
α, β = p
dx[1] = α*x[1] - β*x[1]^2
end
# Condiciones iniciales y parámetros
x₀ = [0.5]
tspan = (0.0, 10.0)
p = (α, β) = (3.0, 1.0)
# Resolver la ecuación diferencial
problema = ODEProblem(logística!, x₀, tspan, p)
solución = solve(problema)
# Imprimir resultado
println("x(t=10) ≈ $(solución(10.0)[1])")
println("Valor teórico x(∞) = α/β = $(α/β)")
```
Esta capacidad de usar notación matemática en el código hace que Julia sea particularmente atractiva para científicos, matemáticos e ingenieros, ya que permite escribir algoritmos que se parecen mucho a las fórmulas en los papers académicos.
Todas estas características de Julia atrajeron a muchos científicos al lenguaje desde un principio, creando una masa crítica de usuarios incluso antes de que las ventajas particulares de su paradigma de despacho múltiple generaran la oleada de interés actual.
Una lección que queda de esto es que _las herramientas importan_: la pintura que un pintor imagina está condicionada por lo que sabe que sus pinceles y pinturas pueden crear; la sinfonía que un compositor oye en su mente debe encajar con el carácter y los registros de los instrumentos que se desplegarán en el escenario y con la destreza de los intérpretes.
La singular combinación de virtudes que Julia ofrece al científico computacional amplía el universo de cosas que un ser humano normal puede lograr en un tiempo finito. Le permite imaginar cosas que serían inimaginables sin ella.
# Limitaciones de Julia
A pesar de las ventajas de Julia, existen algunas limitaciones que pueden hacer que su adopción sea difícil o poco práctica en algunos casos. A continuación se presentan algunas de las limitaciones más importantes:
## Ingeniería del Software
En clara comparación con Python, Julia carece de muchas características de lenguaje y ecosistema orientadas a la Ingeniería del Software. Principalmente, Julia tiene una infraestructura de pruebas significativamente menos madura que Python: las bibliotecas `Unittest` y `Pytest` de Python son mucho más robustas que la biblioteca de pruebas integrada de Julia. Además, Julia prácticamente no admite métodos de prueba más avanzados, como las pruebas basadas en propiedades, la ejecución simbólica y las pruebas basadas en contratos, que se emplean universalmente en los métodos numéricos a gran escala de Python y las bibliotecas de aprendizaje automático, como `Pandas`, `NumPy`, `SciPy`, `SymPy`, `Scikit-Learn`, `Jax`, `Tinygrad`, y `Cupy` a través de las bibliotecas `Hypothesis`, `Crosshair` y `Deal`. Julia también carece de un verificador de tipos estáticos mantenido activamente. Los métodos de prueba más rigurosos son especialmente importantes en la computación científica, donde la precisión y la corrección de las implementaciones de algoritmos son fundamentales. Al poder probar a fondo las propiedades de un algoritmo, podemos conciliar mejor las incertidumbres epistémicas (del modelo) con las incertidumbres aleatorias (de datos).
## Debugging
A nivel de lenguaje, los mensajes de error de Julia han sido continuamente un problema sin resolver en la comunidad. La complejidad del despacho múltiple, así como los notoriamente largos seguimientos de pila, hacen que procesar los mensajes de error de Julia sea un proceso tedioso. Además, una encuesta reciente de [Julia Hub](https://juliahub.com/) mostró que los programadores de Julia citaron los mensajes de depuración complejos como uno de los mayores obstáculos técnicos del lenguaje.
## Adopción en la industria
Si bien Julia puede estar ganando popularidad en el ámbito académico, la investigación en ML tiene una fuerte presencia en la industria, algo que no se observa en muchas otras disciplinas. Por ello, las contribuciones de la industria al código abierto son un factor clave en la adopción general de un lenguaje o biblioteca. Una limitación clave de Julia es la falta de apoyo de los gigantes de la industria. Su mayor competidor es, sin duda, Jax, mantenido por Google Deepmind, que suele considerarse como una solución que aborda los síntomas de los problemas de Python, el más significativo de los cuales es su rendimiento. Además, empresas como HuggingFace han diseñado sus API para compartir pesos de modelos y conjuntos de datos exclusivamente en torno a las bibliotecas de aprendizaje automático de Python, lo que dificulta considerablemente que los usuarios de Julia compartan sus modelos científicos entre sí y requiere el uso de entornos de Python.
Mientras que Julia cuenta con un número cada vez mayor de patrocinadores de la industria, existe una clara ventaja de recursos para los ecosistemas basados en Python. En apoyo de esto, la encuesta de Julia Hub de 2024 se encontró que el 64% de los usuarios pensaba que uno de los mayores problemas no técnicos del lenguaje era “no hay suficientes usuarios de Julia en mi campo o industria”, un salto de aproximadamente un 6% desde el 2023. La encuesta de 2024 también encontró que, si bien el 71% de los encuestados utilizaba Julia para la investigación, sólo el 16% informó: “Utilizo Julia en producción para una tarea crítica para el negocio”. Las aplicaciones industriales requieren pruebas robustas e interoperabilidad con las herramientas existentes, lo que respalda la idea de que las limitaciones expuestas en esta sección no están del todo desconectadas.
## Interoperabilidad
A pesar de las molestias del problema de los dos lenguajes, los usuarios inevitablemente necesitarán usar varios lenguajes hasta que los científicos comiencen a escribir sus aplicaciones de dominio específico en Julia. Llamar a funciones de Python, R, C y C++ en Julia es relativamente fácil con `PythonCall.jl`, `PyCall.jl`, `RCall.jl` y la función de la biblioteca estándar de Julia `ccall`, pero la operación inversa suele ser extremadamente difícil y poco intuitiva, ya que el usuario deberá gestionar explícitamente el contexto de Julia y la transferencia de tipos de datos complejos entre lenguajes. Mientras que `PythonCall.jl` maneja la conversión de Julia a Python con mucha facilidad, todavía queda mucho camino por recorrer al llamar a Julia desde otros lenguajes.
# Conclusión
Julia no solo iguala y supera en muchos aspectos a Python con su conjunto de herramientas de SC de propósito general, sino que también proporciona muchas más herramientas específicas para resolver este tipo de problemas, algo nunca visto en ningún otro lenguaje (esto es especialmente cierto para los problemas de optimización con restricciones que surgen naturalmente en las ciencias naturales).
Desafortunadamente, esto no ha sido suficiente para que Julia se generalice. Si bien Julia ha ido ganando terreno lentamente, en comparación con el crecimiento del SC en general, su crecimiento ha sido bastante lento.
La falta de funciones centradas en la ingeniería del software de Julia, una infraestructura de depuración mediocre, una adopción por parte de la industria deficiente, su “rivalidad” con Jax y una interoperabilidad insuficiente obstaculizan su adopción. Sin embargo, ninguna de estas limitaciones por sí solas parece ser un obstáculo. En teoría, Julia debería competir con Python. Así que, de nuevo, nos preguntamos: ¿por qué no lo hace?
En el artículo [Julia: A Fresh Approach to Numerical Computing](https://arxiv.org/abs/1411.1607) la visión inicial de Julia se resume en tres puntos:
1. Un lenguaje de programación puede ser de alto nivel, dinámico y rápido.
2. Un lenguaje de programación se puede utilizar tanto para crear scripts como para implementaciones de algoritmos complejos y eficientes.
3. Un lenguaje de programación debería proporcionar un mecanismo para abstraer fácilmente los detalles innecesarios que suelen dejarse en manos de los expertos.
Se podría decir que Julia ha abordado estos tres puntos y ha madurado en ellos, pero sigue siendo un nicho de mercado muy específico a pesar de su creciente base de usuarios potenciales.
En los últimos tiempos, los usuarios de Julia se han alejado en gran medida de mejorar el propio lenguaje Julia y ahora se centran más en el desarrollo de bibliotecas para proyectos específicos. Se puede argumentar que la comunidad de Julia ha avanzado demasiado rápido y se ha alejado de una de las tareas fundamentales. El estado del ML está cambiando rápidamente, y Julia tiene el potencial de abordar muchos de los problemas de la comunidad, pero si no se abordan los problemas a nivel de lenguaje, se corre el riesgo de repetir muchos de los errores de Python.
Este cambio de rumbo parece indicar que el estado actual de Julia carece de visión, y se hace necesaria una nueva constitución: un conjunto de objetivos concretos de mejora, adopción y difusión. Si bien Python tiene una lista clara de objetivos futuros, y los ecosistemas individuales dentro de Julia, como SciML, tienen hojas de ruta claras y bien definidas, el propio lenguaje Julia en sí solo presenta problemas superficiales con GitHub. Solo identificando y resolviendo estos problemas a nivel de lenguaje puede abordarse la pregunta de si Julia es capaz de suceder a Python como el lenguaje de facto para el SC.
(insert ../menu.md.html here)