**Fundamentos Matemáticos del Machine Learning**
El objetivo de la serie de entradas que comienza aquí es el de hacer un repaso por los fundamentos matemáticos que hay detrás del concepto de aprendizaje que nos encontramos habitualmente en áreas tan actuales como el Aprendizaje Estadístico o el Machine Learning (Aprendizaje Automático).
Intentaremos presentar un marco base unificado a ambas teorías, de forma que se vea cómo cada una de ellas añade un conjunto de suposiciones adicionales a esta base (y algunas diferencias de enfoque propios de cada disciplina y los investigadores que las componen) e intentaremos, en la medida de lo posible, atacar nuestro objetivo con la ambiciosa pretensión de que el marco sea lo suficientemente general como para abarcar los distintos tipos de aprendizaje que se vienen considerando en la literatura.
Aunque alguna vez podamos enfocarnos en casos concretos de modelos de aprendizaje, el objetivo último es el de probar que existen herramientas matemáticas adecuadas para poder expresar qué entendemos por _aprendizaje_ y bajo qué condiciones este aprendizaje es posible.
En esta entrada presentaremos la motivación del problema de aprendizaje de forma muy general, y daremos el marco matemático (el de espacios de probabilidad) sobre el que montaremos el formalismo necesario para hablar de aprendizaje desde el punto de vista matemático.
# Observaciones del mundo
Aunque el término *aprendizaje* ha recibido mucha atención desde diversas áreas del conocimiento (desde ramas más clásicas y sociales, como la Filosofía o Pedagogía, hasta ramas más pragmáticas como la Estadística y Computación), no vamos a entrar en la eterna discusión acerca de qué es aprender para el ser humano, y qué condiciones hacen falta para que el aprendizaje se produzca de forma óptima... y no porque carezca de interés este tipo de preguntas, sino porque sitúan la discusión fuera del objeto propio que aborda la matemática, y que es el que aquí nos interesa.
Sin embargo, sí es necesario tomar un punto de partida que permita ver que, pese a que el objeto que tratamos quizás no tenga tantas facetas como el de *aprendizaje* general que se analiza desde otras disciplinas, estamos tratando con una sección, o una proyección, del mismo objeto. En este sentido, esperamos que la definición rígida con la que trabajaremos, aunque incompleta a todas luces para muchas aproximaciones, no representa un objeto de estudio completamente ajeno a las aproximaciones clásicas. Tampoco nos extenderemos mucho sobre los fundamentos de esta visión restringida, ya que perseguimos pasar lo antes posible a su manipulación con las teorías matemáticas adecuadas.
El elemento principal que requiere el aprendizaje es la _experiencia_, no hablamos de aprendizaje al conocimiento que se adquiere desde el vacío (es más, resulta indudable que desde el más puro vacío pueda adquirirse ningún tipo de conocimiento nuevo), sino que precisamos que haya habido una etapa de experimentación (observación) sobre un fenómeno para poder realizar posteriormente un aprendizaje sobre el mismo.
Debido a que las experiencias las recibimos por parte de sensores físicos, siempre podemos reducir estas experiencias previas a un conjunto de datos (no necesariamente numéricos, aunque posiblemente sean los más potentes e interesantes para ser tratados con algún tipo de formalismo) que podemos medir y almacenar acerca del fenómeno observado. Cada una de estas observaciones individuales proporciona pues un elemento, \(x\), formado por todo el bloque de datos perteneciente a esa observación individual.
Por ejemplo, si observamos un cuerpo en caída libre, y anotamos los diversos estados por los que pasa el cuerpo, podríamos extraer como bloque individual de medidas algunas referencias que nos den información suficientemente rica del fenómeno: instante en que se toma la medición (respecto a un reloj considerado como referencia temporal), posición del cuerpo en ese instante (respecto a un sistema de referencia espacial determinado), velocidad y dirección del movimiento, quizás dirección y velocidad del viento, a qué altura estaba el sol, en qué parte del mundo estamos haciendo la medición, la humedad relativa del aire, el día del año en el que ocurre el fenómeno, etc...
Nuestro objetivo, como estudiosos del fenómeno, suele ser reconocer un conjunto de patrones (si tenemos suerte, se convertirán en leyes) que nos permitan extraer conclusiones acerca del fenómeno observado... a cualquier extracción de este tipo la denominaríamos _aprendizaje_. Así pues, no es raro encontrar el concepto de aprendizaje relacionado con el de extracción de patrones que permiten generalizar de alguna forma las observaciones individuales obtenidas hacia reglas que informan acerca de la estructura que dichas observaciones tendrían bajo cualquier supuesto adicional.
Este patrón (o patrones) aprendido puede tomar muchas formas, que en última instancia dependerán de nuestra capacidad para dar forma a las relaciones observadas, y que van desde ser capaz de reconocer bloques de datos que sean coherentes con el fenómeno (por ejemplo, distinguir que cuerpos que se mueven en dirección vertical alejándose del suelo no están sufriendo el mismo fenómeno que cuerpos que se mueven en caída libre), hasta ser capaces de dar leyes generales que predigan las condiciones del objeto en tiempos futuros.
Por supuesto, y dependiendo del aprendizaje que estemos buscando, entre las medidas anotadas en el proceso descubriremos que habrá algunas con mayor importancia que otras para poder reconocer patrones útiles sobre el fenómeno. Además, y siguiendo el método científico de aproximación al estudio de fenómenos, podemos suponer que para un mismo fenómeno tomamos bloques de medidas con la misma estructura (es decir, que si observamos el cuerpo en caída libre, en cada instante de tiempo consideramos las mismas variables observadas y tomaremos nota de ellas). Notaremos por \(O\) el conjunto de todas las posibles observaciones del fenómeno concreto observado, y por \(S=\{o_1,\dots,\ o_n\}\subseteq O\) al conjunto finito de observaciones que hemos tomado.
Como suele ocurrir en la mayoría de descubrimientos científicos (que son un reflejo de los aprendizajes obtenidos por los científicos involucrados), este espacio de observaciones suele descomponerse como producto de dos espacios de dimensión menor, \(O=X\times Y\), donde se espera encontrar una relación de causalidad entre las variables de \(X\) y las de \(Y\), por lo que también será común escribir \(S=\{(x_1,y_1),\dots,\ (x_n,y_n)\}\). Aunque esta división no es necesaria, la búsqueda de relaciones funcionales entre las variables observadas es la que ha guiado casi toda la adquisición de conocimiento en los fenómenos del mundo natural.
Veamos algunos ejemplos de observaciones de fenómenos:
!!!ejemplo: Ejemplo 1: Observaciones no numéricas.
Una entidad bancaria concede un préstamo a un cliente en función de una serie de parámetros: su edad (puede ser joven, mediano o mayor), sus ingresos (altos, medios o bajos), un informe sobre su actividad financiera (que puede ser positivo o negativo) y, finalmente, si tiene otro préstamo a su cargo o no. La siguiente tabla presenta una serie de ejemplos en los que se especifica la acción que ha decidido el banco en relación a la concesión o no del préstamo en función de estos parámetros:

En este caso, hemos obtenido un conjunto de observaciones sobre variables no numéricas.
!!!ejemplo: Ejemplo 2: Observaciones numéricas sin relación funcional.
Estamos analizando cómo se comportan un conjunto de diferentes disciplinas de investigación con respecto al tipo de publicaciones que suelen generar, y obtenemos una tabla de observaciones que vienen dadas por dos valores medibles: el % de artículos publicados en revistas, y el % de artículos publicados en revistas de cierta categoría (E y A). Para cada observación (que es de una disciplina) podemos representar estas dos cantidades como un punto de un espacio bidimensional, tal y como muestra la siguiente gráfica:
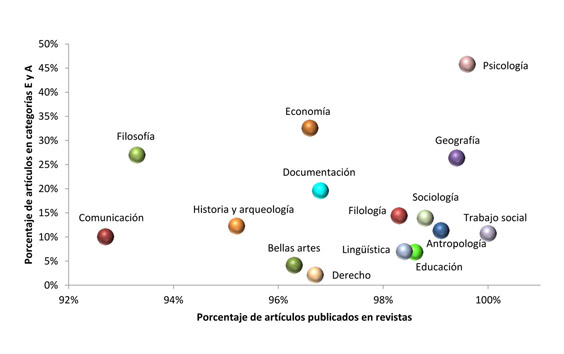
!!!ejemplo: Ejemplo 3: Observaciones numéricas con relación funcional.
Si en el ejemplo de caída libre que poníamos antes tomamos como observaciones el tiempo transcurrido desde que soltamos el cuerpo y la velocidad adquirida, podemos obtener una serie de observaciones bidimensionales que, al representarlas, podrían dar algo parecido a la siguiente gráfica:
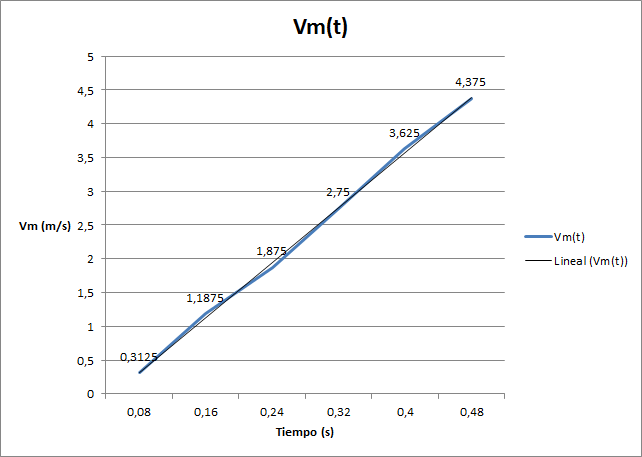
Se puede observar que, aunque la relación que muestran presenta algunas pequeñas perturbaciones debidas, posiblemente, a errores en la medición (los aparatos de medición cometen pequeñas imprecisiones en el mejor de los casos), es claramente reconocible una relación funcional lineal entre ambas variables observadas.
Normalmente, la observación y medición de un fenómeno concreto da lugar a una sucesión de puntos dependientes del tiempo, lo que nos permite trazar la curva asociada a cada fenómeno por separado, y el conjunto de muchas observaciones repetidas del mismo fenómeno daría lugar a una familia de curvas que se superponen y cruzan. Pero otras veces solo podemos disponer de observaciones aisladas que no facilitan la tarea de reconocer la dependencia funcional de una forma clara, ya que lo que obtenemos es una nube de puntos (observaciones) que, si es el caso, aproximan en cierta forma la relación funcional subyacente:
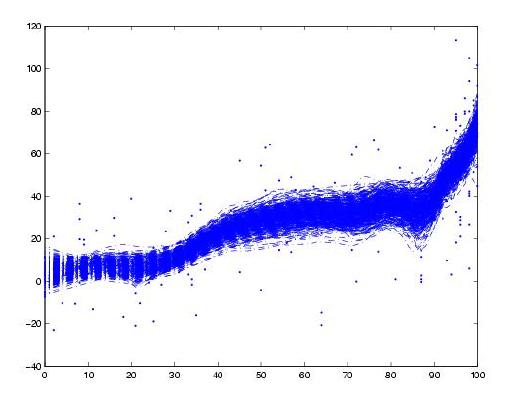
# Primeras suposiciones: El mundo real tiene una razón
La primera, y fundamental, suposición acerca de las observaciones extraídas es que provienen de algún patrón existente en el mundo real. Quizás porque el mundo es así, o porque como animales hemos de buscar reglas que expliquen las sucesiones de fenómenos observados (es mucho más barato almacenar una regla en la cabeza que un conjunto de datos inconexos), el hecho es que presuponemos que la causalidad presente en el mundo se debe a la existencia de un conjunto de patrones (a veces formalizables en forma de reglas o leyes generales) que generan estructuras reconocibles en el espacio de observaciones, \(O\). Esta suposición en realidad son dos suposiciones en una: por una parte, pensamos que en el mundo real se dan esas relaciones de causalidad y presenta una estructura, y por otra, suponemos que las medidas que hacemos del mundo (y que aquí hemos reflejado como \(O\)) mantienen de alguna forma esa estructura original.
Estas dos suposiciones, que no son nada descabelladas, se tomarán como punto de partida de nuestra teoría del aprendizaje, y desde ahora, salvo pequeños comentarios, trabajaremos con \(O\) como único representante y puerta de acceso al fenómeno analizado.
Junto a estas dos suposiciones, hay una tercera, de carácter un poco más técnico, pero que estamos usando desde el principio, y es que el mundo real, y en su defecto \(O\), es un espacio con una estructura medible. No en vano hemos estado diciendo desde el principio que tomamos medidas de él, sino que la suposición va un poco más allá de los términos semánticos y suponemos que en \(O\) hay definida una medida, \(\rho\), en sentido matemático, que permite medir la importancia, probabilidad, peso, de conjuntos de observaciones.
El problema principal al que tendremos que enfrentarnos es que esta medida es completamente desconocida, y casi todos los resultados irán encaminados a poder extraer conclusiones a partir de lo único que podemos saber del espacio... y es que bajo las condiciones adecuadas podemos ver que las observaciones medidas del mundo, \(S\), se corresponden con una sucesión de extracciones de elementos de \(O\) que siguen la medida subyacente (es decir, \(S\) refleja todo el conocimiento que podemos tener de \(\rho\)).
# Algunas notas sobre Espacios de Medida
!!!def
Formalmente, una medida \(\rho\) es una función definida en una \(\sigma\)-álgebra sobre el conjunto \(O\) (es decir, una familia de subconjuntos de \(O\) que verifica algunas propiedades adicionales, y sus elementos se dicen **medibles**) con valores en el intervalo \([0,\ \infty]\), que verifica:
1. La medida del conjunto vacío es cero: \(\rho(\emptyset) = 0\).
2. Si \(A_1,\ A_2,\ \dots\) es una sucesión numerable de conjuntos disjuntos dos a dos medibles, entonces:\( \rho \left(\bigcup_{i=1}^{\infty}A_i\right)=\sum _{i=1}^{\infty}\rho(A_i)\)
!!!teorema
De la definición se pueden extraer algunas propiedades, como son:
1. Monotonía: Si \(A\subseteq B\), entonces \(\rho(A)\leq \rho(B)\).
2. Si \(A_1,\ A_2,\ \dots\) es una sucesión numerable de conjuntos medibles, entonces: \( \rho \left(\bigcup_{i=1}^{\infty}A_i\right)\leq \sum _{i=1}^{\infty}\rho(A_i)\).
3. Si además \(A_i\subseteq A_{i+1}\), entonces \( \rho \left(\bigcup_{i=1}^{\infty}A_i\right)= \lim_{i\rightarrow \infty}\rho(A_i)\).
4. Si \(A_{i+1}\subseteq A_i\), entonces \( \rho \left(\bigcap_{i=1}^{\infty}A_i\right)= \lim_{i\rightarrow \infty}\rho(A_i)\).
!!!def
Un conjunto medible, \(A\), se dice **nulo**, o de **medida nula**, si \(\rho(A)=0\). Y la medida se dice **completa** si todo subconjunto de un conjunto medible de medida nula es también medible (y, en consecuencia, de medida nula).
En la mayoría de los casos podemos suponer que el espacio completo tiene medida finita, bien sea porque trabajamos con un trozo finito o compacto de él, o bien porque a pesar de ser infinito presenta algunas características de concentración haciendo que algunas partes (relativamente pequeñas) observables concentren casi todo el interés mientras que el resto tiene casi medida nula. Por ello, y para no tener que estar considerando el tamaño del espacio total, supondremos que no solo hay una medida en \(O\), sino que además es una medida de probabilidad, es decir, que la medida del espacio completo es \(\rho(O)=1\) (si no fuese así, bastaría considerar una medida adicional, pequeña variante de la anterior, que sea \(\rho'(A)=\frac{1}{\rho(O)}\rho(A)\)).
En este sentido, podemos ver \(\rho\) como una probabilidad que indica cómo de probable es que se den ciertas observaciones en el mundo. En caso de que \(\rho\) sea capaz de medir observaciones aisladas, entonces indicaría la probabilidad de que cada observación sea posible, pero la realidad es que si \(O\) es no numerable la mayoría de las observaciones aisladas tienen medida \(0\).
En muchos casos es habitual considerar una función asociada a la medida, que llamamos **función de densidad**, y que indica el peso de cada punto del espacio \(O\) respecto a la medida. No debemos confundir esta función de densidad con la propia medida, ya que \(\rho\) está definida en los subconjuntos de la \(\sigma\)-álgebra y da la medida de éstos, mientras que la función de densidad está definida directamente en los puntos de \(O\) y devuelve el peso de cada punto respecto a la medida, algo que, aunque en general no tiene sentido porque asociaría en la mayoría de los casos el valor \(0\), puede servir de ayuda para hacerse una idea visual de cómo se distribuye la medida en el espacio.
En el caso finito (y en el numerable), podríamos escribir \(\rho(O)=\sum_{o\in O}\rho(o)=1\). En el caso general se escribe usando el símbolo integral:
$$\rho(O)=\int_O d\rho = 1$$
En general, si queremos conocer la medida de un conjunto medible de observaciones, \(A\subseteq O\), escribirmos:
$$\rho(A)=\int_A d\rho =\int_O \mathbf{1}_A d\rho$$
donde \(\mathbf{1}_A\) es la función característica de \(A\) (que vale \(1\) en los puntos de \(A\), y \(0\) fuera).
Si tenemos definida una función \(f:O\rightarrow \mathbf{R}\) en el espacio de observaciones, entonces su **valor medio integral** es el valor que debería tomar una función constante en todos los puntos de \(O\) para que las integrales de ambas (es decir, el peso de la función en todo el espacio) sean iguales. En general, este valor se puede calcular como:
$$\overline{f}=\frac{1}{\rho(O)}\int_O f d\rho$$
que en el caso especial de estar trabajando sobre un espacio de probabilidad (de medida \(1\)) queda reducido a:
$$\mathbf{E}_\rho[f]=\int_O f d\rho$$
y se denomina **Esperanza** de \(f\), o **valor esperado** de \(f\). En cierta forma, este cálculo nos da el valor medio de los valores que toma la función \(f\), pero ponderados según la medida \(\rho\) (es decir, pesan más en esta media aquellos valores que se tomen en zonas con mayor medida respecto de \(\rho\)).
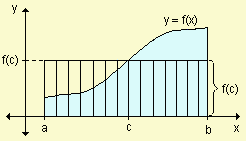
Aunque la esperanza de una función proporciona información interesante acerca de ella, no es suficiente para hacerse una idea acerca de cómo se diferencia de este valor medio, por lo que resulta de interés medir también esta variación de la media, que se denomina **varianza**, y se calcula de forma similar como:
$$\sigma^2(f)=\mathbf{E}[(f-\mathbf{E}[f])^2]=\mathbf{E}[f^2]-\mathbf{E}^2[f]$$
El par formado por esparanza y varianza proporciona una información más concreta acerca del comportamiento de \(f\) en el espacio.
Si consideramos que el espacio de observaciones se puede poner como producto de dos espacios, \(O=X\times Y\), entonces podemos calcular una integral en el espacio completo como una descomposición de integrales iteradas en cada uno de los espacios, pero considerando en los subespacios componentes las medidas adecuadas (derivadas de la medida global). en concreto, siguiendo el **Teorema de Fubini**:
$$\int_{X\times Y} f(x,y) d\rho = \int_X (\int_Y f(x,y) d\rho(y|x) ) d\rho_X$$
donde \(\rho_X\) es la medida que se obtiene directamente proyectando \(\rho\) sobre \(X\) (en estadística, estaría relacionada con la **medida de probabilidad marginal**):
$$\rho_X(V)=\rho(V\times Y)$$
y para cada \(x\in X\), la medida \(\rho(y|x)\) es la **medida de probabilidad condicionada** definida en \(Y\), es decir, la medida \(\rho\) restringida al corte \(\{x\}\times Y\).

Suele ser más común ver este teorema usando como medidas base las definidas en \(X\) y \(Y\) (\(\rho_X\) y \(\rho_Y\), respectivamente), y usar éstas para construir una medida de probabilidad en el espacio producto, \(X\times Y\) (además, para cada \(x\in X\) la medida condicionada es la misma \(\rho(y|x)=\rho_Y\)), y en este caso se puede escribir la descomposición en cualquier orden.
# Aprendizaje Matemático
Tras el contexto matemático que hemos estado introduciendo en los párrafos anteriores, ¿qué entendemos pues por **Aprendizaje**?
En general, y una vez hecha la suposición de que existe una medida subyacente (no conocida) que es la que *genera* las observaciones que podemos medir, resolver matemáticamente el problema del aprendizaje para el fenómeno del que extraemos esas observaciones se traduciría en ser capaces de dar una reconstrucción formal (matemática) de la medida \(\rho\) última. Por supuesto, nos conformaremos con obtener una aproximación de \(\rho\) que se comporte de forma parecida a la observada no solo en los entornos de los puntos observados, sino también en zonas completamente desconocidas por experimentación (cuando hemos construido la aproximación) pero que pueden ser verificadas con observaciones posteriores.
Así pues, estamos buscando métodos matemáticos que nos permitan, a partir del conjunto de observaciones que hemos extraído del fenómeno, \(S\) (y que suele ser finito), reconstruir \(\rho\in med(O)\) (las medidas definibles en \(O\)):
$$\cal{A}:\bigcup_{n\in \mathbf{N} } O^n \rightarrow med(O)$$
$$S\mapsto \rho_S$$
Frente a la, aparentemente sencilla, tarea de encontrar \(\rho_S\) que se comporte como \(\rho\) en \(S\), el verdadero interés es conseguir que aproxime adecuadamente a \(\rho\) en el mundo no observado, fuera de \(S\), ya que de esa forma se confirma que el patrón aprendido realmente capta la esencia del fenómeno observado. En este caso, se dice que \(\rho_S\) **generaliza** bien, y la única forma de verificarlo es por medio de la adquisición de conjuntos adicionales de datos \(S'\subseteq O\) que sean distintos de \(S\).
La aproximación realizada por las distintas disciplinas se refleja en el tipo de herramientas que usan para construir \(\rho_S\) a partir de \(\rho\). Frente al posible uso de funciones de clases como \(\cal{C}^k\), o espacios \(\cal{L}^p\), que define las **aproximaciones funcionales**, encontramos la **aproximación estadística**, que construye la probabilidad \(\rho_S\) a partir de funciones de densidad en determinados conjuntos de hipótesis (por ejemplo, familias de gaussianas), la **aproximación computacional** (de Machine Learning) que hace uso de funciones computables que aproximan determinadas familias de funciones simples muy determinadas a priori, o la aproximación de la **Física**, haciendo uso de funciones definibles por medio de ecuaciones diferenciables que reflejan la dinámica inherente a los sistemas físicos reales.
A partir de la siguiente entrada analizaremos de qué forma podemos extraer conclusiones acerca de las posibles aproximaciones, estableciendo cotas que nos permitan conocer la factibilidad del aprendizaje incluso sin hacer suposiciones adicionales acerca de \(\rho\).
(insert menu.md.html here)