**PageRank y el Surfista Aleatorio**
De forma genérica, se denomina **PageRank** a las diversas versiones de un algoritmo de ranking de páginas web que fue diseñado por [Larry Page](https://es.wikipedia.org/wiki/Larry_Page) y [Sergey Brin](https://es.wikipedia.org/wiki/Sergu%C3%A9i_Brin) cuando ambos estaban en la **Universidad de Stanford**. De hecho, además de la importancia computacional que este algoritmo tiene por el problema que resuelve, tiene una gran importancia histórica, tecnológica y social porque la creación de este algoritmo fue lo que dio origen a la creación del buscador **Google**.
Este algoritmo fue concebido como herramienta **SEO** (**Search Engine Optimization**), aunque en esta entrada lo veremos más como un algoritmo de ranking en una red cualquiera (del que el uso como herramienta SEO es un caso particular). Destaca la curiosidad de que en 1997 los creadores ofrecieron a **Yahoo** (el principal buscador de la época) este algoritmo por 1 millón de US $. Yahoo declinó la oferta para, unos años después, en 2002, ofrecer a Google la cantidad de 3.000 millones de US $ por su propiedad. En esta ocasión, fue Google quien rechazó la oferta.
!!!side:1
 El problema de medir la importancia de los nodos de una red en función de cómo están conectados entre sí es un problema antiguo que ya se conocía y se había abordado desde distintos ángulos. Además, había soluciones conocidas, aunque no fuesen eficientes desde un punto de vista práctico cuando el número de nodos en la red crecía mínimamente. Quizás la primera aplicación práctica conocida de este problema se deba al economista **Wassily Leontief** (**Universidad de Harvard**, y premio Nobel en 1971) que lo utilizó para modelar el funcionamiento de una economía representada mediante una red con el fin de dar una valoración relativa (ranking) entre los distintos componentes del sistema económico.
El algoritmo proporciona un método para medir la **autoridad** de una página web, su **importancia** dentro de un sistema de páginas, basándose en la cantidad y calidad de los enlaces que apuntan hacia ella. Pero no nos adelantemos, en las siguientes secciones podremos ver con detalle cómo funciona e, igual de importante, las razones para que funcione y los trucos para acelerar su cálculo [1].
Aunque el algoritmo de PageRank que veremos aquí permitió hacer despegar una pequeña empresa hasta alcanzar el tamaño descomunal que presenta hoy en día, pronto se vieron los problemas que presentaba en su forma original y, a pesar de ser la mejor opción del momento, ha sufrido sucesivas mejoras y modificaciones enfocadas principalmente a impedir que el valor asignado a una página en concreto sea manipulable por medios externos con el fin de posicionarla artificialmente con una valoración superior a la original. Muchas de estas mejoras fueron públicas, así como el ranking obtenido por las páginas, hasta que en el 2016 Google decidió no publicar ninguna información adicional con el fin de dificultar la creación de métodos artificiales de influir en los resultados. Hoy en día se sabe que el algoritmo que usa Google para el ranking de páginas para, por ejemplo, dar respuesta a una consulta en su buscador, es realmente una combinación de varios algoritmos, donde PageRank juega un papel cada vez menor.
# Contextualización del problema
En al artículo fundacional en el que se publica el algoritmo PageRank podemos encontrar un abstract que dice:
!!!alg
*La importancia de una página web es un problema inherentemente subjetivo que depende del interés de los lectores, de su conocimiento y de sus inclinaciones. Aun así, se puede decir objetivamente mucho sobre la importancia relativa de las páginas web. Este artículo describe PageRank, un método para valorar las páginas web de forma objetiva y mecánica, midiendo de forma efectiva la atención e interés humanos dirigidos hacia cada página. Comparamos PageRank con un `web surfer` aleatorio idealizado. Mostramos cómo calcular de forma eficiente el PageRank para un número grande de páginas y mostramos cómo utilizar el PageRank para la búsqueda y navegación de los usuarios.*
!!!side:2
Para saber algo más de este tema, se puede consultar esta [otra entrada](Estructurando_consultando_informacion_grafos.md.html).
Y se debe poner en contexto la importancia de un resultado así. Tras la revolución del acceso a la información con la aparición de internet y la facilidad para publicar que ofrece, aparece la necesidad de poner orden en ese inmenso y creciente mar de información desordenada. En este sentido, aparece un problema que se acrecenta con el tiempo, y es la convivencia de una gran cantidad de **Información Estructurada** con **Información No Estructurada** [2].

Es este el problema que está en la raíz de la tarea de recuperación de información que debe resolverse para hacer de ese mar de datos un sitio navegable con ciertas garantías de éxito. Y puede verse (y debe verse) como un problema de Ingeniería Matemática:
1. Es preciso un **modelado matemático adecuado** para confirmar que los algoritmos que se usen para resolverlo son **correctos**.
2. Es necesario el uso de **resultados matemáticos robustos** para su **resolución efectiva**.
3. Es necesario el uso de **técnicas computacionales adecuadas** para su **resolución eficiente**.
!!!side:3
Como puedes observar si realizas una búsqueda en cualquier buscador, el número de resultados que pasan el filtro suele superar las centenas de miles (salvo que se haga una búsqueda excesivamente restringida, que podría bajar a *solo* unos pocos miles).
Supongamos que, como resultado de una consulta en un buscador (siguiendo el protocolo que sea, por ejemplo, por la aparición de los términos de búsqueda en su cuerpo), hemos determinado que un conjunto de páginas contiene información que, de una manera u otra, puede resultar relevante para el usuario [3]. Así pues, surge de forma natural la siguiente duda: **¿En qué orden mostramos esos resultados para que al usuario le resulte más sencillo (y factible) revisarlos con ciertas garantías de éxito?**
Lo lógico es usar un ranking de forma que se muestren primero las fuentes con más probabilidad de ser las más adecuadas a la búsqueda. Pero con una consulta de apenas unos términos es complicado diferenciar objetivamente un resultado de otro, salvo que usemos alguna información adicional, interna en la propia red de páginas que el usuario navega (la WWW), que nos permita diferenciar la importancia de unas páginas frente a otras.

!!!side:4
No hay que asustarse, intentaremos usar requisitos matemáticos relativamente bajos (quizás de primer curso de cualquier licenciatura de ciencias), e incluso si no tienes los conocimientos de ese nivel, espero que algunas explicaciones adicionales (y algunos métodos) te permitan entender intuitivamente cómo funciona el algoritmo.
Vamos a pasar a formalizar (matemáticamente) un poco el problema para representarlo adecuadamente y poder abordarlo con herramientas (matemáticas) ya existentes y comprobadas [4].
# Formalización del problema
 Si etiquetamos por $P_1,\dots,P_n$ las páginas que queremos ordenar, nuestro objetivo es asignar a cada $P_i$ una importancia numérica $x_i$. Como solo nos interesa la importancia relativa entre ellas (es decir, quién está delante de quién), podemos suponer que $x_i\in [0,1]$.
Vamos a usar un modelo que hace uso únicamente de las etiquetas asignadas a las páginas y los enlaces entre ellas, por lo que podemos hablar de una **red dirigida de páginas**. Así pues, notaremos por $M=(m_{ij})$ a la matriz de adyacencias asociada a dicha red, donde:
$$m_{ij}=\begin{cases}
1, & \text{si } P_i\rightarrow P_j \\
0, & \text{en otro caso}\end{cases}$$
Nuestro primer postulado es que la importancia de una página *está relacionada* con las páginas que la enlazan:
!!!alg
Si muchas páginas enlazan con $P_j$ será porque la información que esta contiene ha sido considerada por muchos participantes/constructores de la red como **recomendable**.
Así pues, nuestro primer supuesto es que los enlaces de la red (no cada uno de ellos, sino el conjunto de enlaces existentes) mantienen y reflejan información colectiva acerca de la importancia de las páginas.
En consecuencia, y aventurándonos un poco, podríamos dar ya un primer intento de definir la importancia:
!!!def
$x_j$ es proporcional al grado (entrante) del nodo $P_j$.
Este valor se puede obtener a partir de $M$ por medio de la suma de los valores de su fila j-ésima.
!!!warn
Esta primera aproximación plantea algunos problemas:
1. No recoge adecuadamente el hecho de que una página que es citada desde pocas páginas, pero importantes, debe ser también importante.
2. Aunque no es un problema grave, sí se debe tener en cuenta que necesitamos que el modelo asigne importancia alta a páginas que sean citadas desde páginas importantes... lo que nos lleva a una definición recursiva.
De hecho, podemos hacer uso de este segundo *problema* para dar una definición más adecuada, aunque quizás más compleja, pero que nos permitirá dar una solución muy elegante matemáticamente:
!!!def
$x_j$ es proporcional a la suma de las importancias, $x_i$, de las páginas $P_i$ que enlazan con $P_j$.
!!!side:5
Recuerda que si $P_i$ no apunta a $P_j$ entonces $m_{ij}=0$, por lo que $x_i$ no aporta nada a $x_j$.
Como el orden se debe seguir manteniendo inalterable, podemos suponer que la constante de proporcionalidad es la misma para todas las páginas, lo que nos lleva al siguiente sistema de ecuaciones [5]:
$$\begin{array}{cccccc}
m_{11} x_1 &+ &m_{21} x_2 &+ &\dots &+ &m_{n1}x_n &= &\lambda x_1 \\
m_{12} x_1 &+ &m_{22} x_2 &+ &\dots &+ &m_{n2}x_n &= &\lambda x_2 \\
\vdots &+ &\vdots &+ &\ddots &+ &\vdots &= &\vdots\\
m_{1n} x_1 &+ &m_{2n} x_2 &+ &\dots &+ &m_{nn}x_n &= &\lambda x_n
\end{array}$$
que, matricialmente, se puede escribir como:
$$M^T \vec{x}= \lambda \vec{x}$$
donde $\vec{x}=(x_1,\dots,x_n)$, y la ecuación expresa la importancia de cada página a partir de las importancias de las demás páginas que están conectadas a ella.
De esta forma, hemos transformado el problema de calcular las importancias en un problema de **autovalores** ($\lambda$) y **autovectores** ($\vec{x}$), del que disponemos herramientas suficientes para dar una solución y resultados que nos orientan acerca de la viabilidad de los métodos usados.
!!!warn
A pesar de estas buenas noticias, surgen algunos problemas importantes con esta aproximación:
1. Puede haber muchos autovectores (impondremos que todas sus coordenadas sean positivas, y podríamos ver en qué condiciones hay un único autovector).
2. La matriz $M$ es enorme (millones de páginas), así que los métodos habituales (exactos) para calcular autovectores pueden ser completamente inabordables.
Respecto al primer problema, se sabe que bajo determinadas condiciones (que se verifican aquí) un autovector en las condiciones impuestas siempre existe (además, está asociado al autovalor de mayor tamaño) y se puede calcular. De hecho, y aunque ahora mismo puede parecernos un poco extraño, existen varios métodos de cálculo, algunos pasan por la factorización de la matriz en producto de matrices con ciertas estructuras fijas (matrices diagonales, triangulares, etc.), y otros se basan en un proceso de aproximación del autovector por iteración de la aplicación de $M$.
Por ejemplo, se sabe que para cualquier vector $\vec{y}$:
$$M^n \vec{y} \rightarrow K \vec{v}$$
donde $\vec{v}$ es el autovector asociado al autovalor mayor (con todas las coordenadas positivas).

De esta forma, hemos convertido el problema de calcular las importancias de los nodos de una red en el cálculo de las potencias sucesivas de la matriz de adyacencias asociada a dicha red... ¿realmente se puede considerar una mejora de eficiencia?
Aunque creamos que no, porque su complejidad computacional sigue siendo muy elevada, en la siguiente sección veremos cómo esta nueva aproximación permite proporcionar una solución alternativa, aproximada, pero mucho más rápida y con muy buenas características para extenderla a otros contextos.
# El surfista aleatorio
Vamos a presentar una aproximación, en principio diferente, que va a permitir obtener aproximaciones bastante buenas de las importancias de los nodos de una forma distribuida y asíncrona.
Supongamos un individuo (un agente, que será nuestro surfista) que navega por la red. Su forma de navegar por la red es completamente al azar, siguiendo las conexiones existentes:
!!!alg
_en un cierto instante este individuo se encuentra en una página, entonces selecciona al azar (y siguiendo una probabilidad uniforme) alguna de las páginas que están conectadas desde donde está y salta a ella._
Matemáticamente, el individuo realiza lo que se llama un **paseo aleatorio** por la red.
Vamos a formalizar este proceso:
1. Denotemos por $N_j$ el número de enlaces salientes de $P_j$ (que se puede calcular simplemente como la suma de la columna j de $M$).
2. Sea $M'$ la matriz **estocástica** que se obtiene de $M$ normalizando sus columnas (es decir, los elementos de la columna j se dividen por $N_j$). De esta forma, en la nueva matriz todas las columnas tienen suma 1, y ahora el nuevo elemento $m_{ij}'=m_{ij}/N_j$ se puede interpretar como la probabilidad de que, estando el surfista en la página $P_i$, visite la página $P_j$ en el siguiente paso.
Consecuentemente, las potencias de esta nueva matriz estocástica proporcionan información acerca de la probabilidad de llegar de un nodo a otro de la red en $n$ pasos. Concretamente, el elemento $ij$ de la potencia $n$-ésima de $M'$ ($[(M')^n]_{ij}$) indica la probabilidad de que, habiendo comenzado en la página $P_i$, tras $n$ pasos el surfista se encuentre en la página $P_j$.
Viéndolo recíprocamente, el elemento $ij$ de la matriz potencia se puede aproximar moviendo aleatoriamente un surfista comenzando desde el nodo $P_i$ y ver con qué probabilidad alcanza el nodo $P_j$. Aunque pueda parecer un poco extraño, bastaría ir moviendo al azar al surfista siguiendo las conexiones de la red, anotar cuántas veces está en cada nodo (convertirlo en una probabilidad), y esos valores nos darían una aproximación de la matriz potencia, a partir de la cual tendríamos una buena aproximación de las importancias de todos los nodos.

Por supuesto, así expresado podemos encontrarnos con algunos casos que dificultarían su uso directo. Por ejemplo, hay que resolver problemas como:
1. ¿Qué hacer con los nodos que no tienen conexiones salientes (**sumideros**)?, si un surfista llegara a uno de tales nodos, no podría continuar su paseo aleatorio. Este problema se puede presentar como sumideros simples (un solo nodo), o compuestos (hordas de nodos que, conjuntamente, no tienen salida, aunque puedan presentar conexiones entre ellos).
2. ¿Qué hacer con los ciclos (**referencias circulares**)? Se puede considerar como un caso particular de sumidero de tipo compuesto. El problema de este tipo de estructuras es que las visitas se incrementarían artificialmente en sus nodos, pero no reflejaría fielmente la importancia del resto de nodos.
En la mayoría de los casos, una forma de resolver el problema es haciendo saltos aleatorios, es decir, de vez en cuando el surfista salta al azar a cualquier nodo (esté conectado con él o no desde su posición actual) y continúa su camino aleatorio.
Pese a estos pequeños inconvenientes, fácilmente solucionables, este método tiene algunas ventajas claras como, por ejemplo:
* Es robusto a cambios en las conexiones, porque la mayoría de las probabilidades se verán poco afectadas si los cambios son locales.
* Es fácilmente paralelizable, basta para ello tener varios surfistas moviéndose por la red de forma simultánea.
* Es distribuido. Incluso en el caso en que estemos trabajando sobre una red **simulada**, es fácil hacer que diversos procesos independientes (ni siquiera necesitan ser sincronizados) trabajen con distintos surfistas.
* Es local (a la topología de la red), lo que significa que si queremos tener información de la importancia de una parte de la red, podemos situar originalmente los surfistas en esa parte y ver los resultados locales que producen.
Además, también tiene ventajas para la generación de variantes que pueden ser interpretadas como análisis alternativos al estudio de las redes. Por ejemplo:
!!!side:6
Si pensamos en páginas web, por ejemplo el tamaño y vistosidad de unos enlaces frente a otros.
* Es fácil considerar casos en los que las probabilidades de visitar los vecinos desde un nodo no son uniformes, por lo que puede haber preferencia de visitas [6].
* Es fácil introducir variantes en las que los agentes tienen preferencias (no la red, sino los surfistas), de forma que puedo tener algunos de ellos especializados (o preferentes) en algunos tipos de conexiones o hacia cierto tipo de nodos.
* Se pueden obtener condiciones de **importancia de un conjunto de nodos respecto de uno fijo**, haciendo que el surfista siempre comience desde un nodo concreto.
* Se puede considerar la importancia de estructuras superiores a nodos simples, considerando las visitas provocadas por conjuntos de nodos desde conjuntos de nodos.
* Se puede considerar la importancia de aristas, y no solo de nodos, anotando las visitas que reciben en los caminos aleatorios.
# Procesos de Difusión
Aunque aquí nos hemos centrado más en justificar la relación que existe entre la formalización matemática y el algoritmo basado en el Surfista Aleatorio, suele ser más común analizar la relación que existe entre la primera y un proceso de difusión que produce el mismo resultado. Este proceso iterado de difusión simplemente simula el proceso por el que la importancia de una página se distribuye uniformemente entre las páginas a las que ella apunta:
$$I (j)= (1-d) + d \sum_{i:\ (i,j)\in E}\frac{I(i)}{Gr(i)}$$
Donde:
* $I(j)$ es la importancia del nodo $j$,
* $d\in [0,1]$ es un factor de amortiguación, que indica qué proporción de importancia va a distribuir entre los vecinos,
* el sumatorio se considera entre los nodos que conectan con $j$, y
* $Gr(i)$ es el grado saliente de $i$.
En realidad, este proceso de difusión se puede ver como una versión **semi-continua** del surfista aleatorio, en la que disponemos de muchos surfistas que ponderan continuamente las conexiones establecidas en la red.

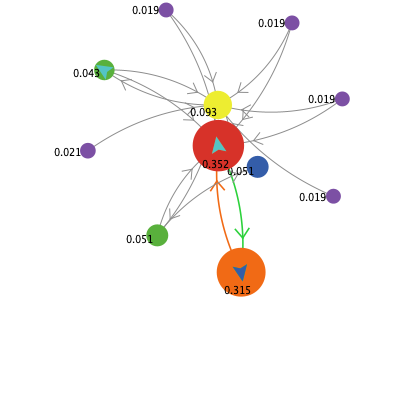
# Simulando el cálculo de PageRank
Todo lo anterior puede quedar un poco como papel mojado si uno no puede comprobar cómo funciona desde un punto de vista práctico y ver cuán eficiente es. Pero hay solución sencilla, basta ejecutar el modelo [PageRank](https://ccl.northwestern.edu/netlogo/models/PageRank) que trae la fantástica herramienta [NetLogo](https://ccl.northwestern.edu/netlogo/) para empezar a hacer pruebas y ver de qué forma se comportan los surfistas (y el proceso de difusión) sobre distintos tipos de redes.
(insert menu.md.html here)