**Teoría de la Probabilidad: Lo Mínimo**
!!!side:
[Basado en *Review of Probability Theory* de Arian Maleki y Tom Do](http://cs229.stanford.edu/section/cs229-prob.pdf)
La teoría de la probabilidad es el estudio de la **incertidumbre**. Con este resumen se intentan dar los fundamentos necesarios para poder entender los algoritmos más habituales en **Ciencias de la Computación** (en particular, algoritmos de aprendizaje automático). Esta entrada solo trata de cubrir la parte más fundamental de la Teoría de la Probabilidad, pero ha de tenerse en cuenta que la teoría matemática de la probabilidad es mucho más sofisticada, y profundiza en una rama del análisis conocida como **Teoría de la Medida**. Nosotros no entraremos aquí en ver las demostraciones de los resultados que presentemos, ni entraremos en detalles de más nivel que los necesarios para formar la intuición necesaria para nuestro objetivo. Además, con el fin de aligerar un poco algunas de las presentaciones, se han eliminado algunas restricciones que tienen sentido matemático, pero que podrían confundir a los interesados por la Teoría de la Probabilidad desde un ángulo menos formal. Así pues, pedimos disculpas por adelantado por las imprecisiones que seguro hay.
# Elementos de Probabilidad
Para definir una probabilidad en un conjunto necesitamos algunos elementos básicos que compondrán los ladrillos con los que construir un edificio suficientemente robusto:
!!!def:Espacios Muestrales, Eventos y Medidas
Consideraremos las siguientes estructuras:
1. **Espacio de muestras**, $\Omega$: El conjunto de todos los resultados de un experimento aleatorio. Cada elemento $w\in \Omega$ se puede considerar como una descripción (más o menos completa, dependiendo de nuestra capacidad para conocer) del estado del mundo real.
2. **Espacio de eventos**, $\mathscr{F}$: Un conjunto cuyos elementos, $A \in \mathscr{F}$ (llamados **eventos**) son subconjuntos de $\Omega$ (es decir, $A \subseteq \Omega$ es una colección de posibles resultados de un experimento, o un conjunto de posibles observaciones del mundo). Este conjunto debe verificar:
* $\emptyset \in \mathscr{F}$.
* Si $A \in \mathscr{F}$, entonces $\Omega - A \in \mathscr{F}$.
* Si $A_1,A_2,\dots \in \mathscr{F}$, entonces $\bigcup_i A_i\in \mathscr{F}$.
3. **Medida de probabilidad**: Una función $P : \mathscr{F} \to \mathbb{R}$ que satisface las siguientes propiedades (**Axiomas de Probabilidad**) y permite _medir_ la probabilidad de un evento:
* $P(A) \geq 0$, para todo $A \in \mathscr{F}$.
* $P(\Omega) = 1$.
* Si $A_1, A_2,\dots$ son eventos disjuntos (es decir, $A_i\cap A_j=\emptyset$ para $i\neq j$), entonces: $$P(\cup_i A_i) = \sum_í P(A_i)$$
A partir de los axiomas de probabilidad se puede deducir la siguiente serie de propiedades de forma más o menos directa:
!!!teorema:Propiedades
Se verifica que:
* Si $A \subseteq B$, entonces $P(A) \leq P(B)$.
* $P(A \cap B) \leq min(P(A),P(B))$.
* $P(A \cup B) \leq P(A) + P(B)$.
* $P(\Omega - A) = 1 - P(A)$.
* Si $A_1,\dots,A_k$ son eventos disjuntos tales que $\Omega=\bigcup_{i=1}^k A_i$, entonces: $$\sum_i P(A_i)=1$$
!!!def: Probabilidad Condicional
Sea $B\in \mathscr{F}$, con $P(B)>0$. La **probabilidad condicional** de cualquier evento, $A$, respecto a $B$ se define como:
$$P(A|B)=\frac{P(A\cap B)}{P(B)}$$
En otras palabras, $P(A|B)$ es la medida de probabilidad del evento $A$ tras observar la ocurrencia del evento $B$.
!!!def:Independencia
Dos eventos se llaman **independientes** si y sólo si $P(A\cap B) = P(A)P(B)$ o, equivalente, $P(A|B) = P(A)$. Por lo tanto, la independencia equivale a decir que la observación de $B$ no tiene ningún efecto en la probabilidad de que $A$ ocurra.
# Variables Aleatorias
Una **variable aleatoria** es, simplemente, una función $X: \Omega \to \mathbb{R}$. Normalmente, denotaremos las variables aleatorias por letras mayúsculas $X$, y usaremos letras minúsculas, $x$, para denotar el valor que puede tomar.
Si la variable toma un número finito de valores (por ejemplo, el número de caras en 100 tiradas de una moneda) se dice que la variable es **discreta**, en caso contrario se dice que es **continua**. De forma habitual usaremos la siguiente notación (abreviada):
$$P(X = k) = P(\{ω : X(ω) = k\})$$ $$P(a \leq X \leq b) := P(\{ω : a \leq X(ω) \leq b\})$$
## Función de Distribución Acumulada
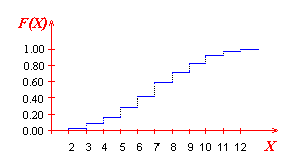
!!!def: Función de Distribución Acumulada
Una **Función de Distribución Acumulada** (CDF) es una función $F_X : \mathbb{R} \to [0,1]$ que se relaciona con una medida de probabilidad de la siguiente forma:
$$F_X(x)= P(X \leq x)$$
Usando esta función se puede calcular la probabilidad de cualquier evento.
!!!teorema:Propiedades
Debido a la relación anterior y las propiedades de las medidas de probabilidad, se verifican las siguientes propiedades:
* $0 \leq F_X(x) \leq 1$.
* $\lim_{x\to -\infty} F_X(x) = 0$.
* $\lim_{x\to +\infty} F_X(x) = 1$.
* Si $x \leq y$ entonces $F_X(x) \leq F_X(y)$.
## Función de Masa de Probabilidad
Cuando una variable aleatoria es discreta hay formas más simples de representar la medida de probabilidad asociada especificando directamente la probabilidad de cada valor que puede tomar la variable. En este caso, usamos la notación $Val(X)$ para denotar el conjunto de posibles valores de $X$, y podemos definir:
!!!def:Función de Masa de Probabilidad
La **Función de Masa de Probabilidad** (PMF) asociada como la función $p_X : \Omega \to \mathbb{R}$ tal que:
$$p_X(x) = P(X = x)$$

!!!teorema:Propiedades
Es fácil probar que se verifican las siguientes propiedades:
* $0 \leq p_X(x) \leq 1$.
* $\sum_{x\in Val(X)} p_X(x) = 1$.
* $\sum_{x\in A} p_X(x) = P(X \in A)$.
## Funciones de Densidad
Para algunas variables aleatorias continuas la función de distribución acumulada, $F_X(x)$ es diferenciable en todos sus puntos. En este caso se define:
!!!def: Función de Densidad
La **Función de Densidad** (PDF) como la derivada de $F_X$:
$$f_X(x)=\frac{dF_X(x)}{dx}$$
En este sentido, teniendo en cuenta la definición anterior, para valores pequeños de $\Delta x$ se tiene que:
$$P(x \leq X \leq x + \Delta x) \approx f_X(x)\Delta x$$

!!!teorema:Propiedades
Debido a las propiedades de $F_X$ se puede probar que se verifican las siguientes propiedades en $f_X$:
* $f_X(x) \geq 0$.
* $\int_{-\infty}^{+\infty} f_X(x) = 1$.
* $\int_A f_X(x)dx = P(X \in A)$.
## Esperanza
!!!def:Esperanza
Supongamos que $X$ es una variable aleatoria discreta con PMF $p_X(x)$ y sea $g : \mathbb{R} \to \mathbb{R}$ una función arbitraria. En este caso, $g(X)$ se puede considerar una nueva variable aleatoria, y podemos definir la **esperanza** (o **valor esperado**) de $g(X)$ como:
$$E[g(X)]= \sum_{x\in Val(X)} g(x)p_X(x)$$
Si $X$ es una variable aleatoria continua con PDF $f_X(x)$, entonces el valor esperado de $g(X)$ se define como:
$$E[g(X)] = \int_{-\infty}^{+\infty} g(x) f_X(x) dx$$
Intuitivamente, la esperanza de $g(X)$ se puede ver como una _media ponderada_ de los valores que $g(x)$ puede tomar para los diferentes valores de $x$, donde los pesos vienen dados por $p_X(x)$ o $f_X(x)$. Como caso especial, obsérvese que la esperanza de la propia variable aleatoria, $E[X]$, se obtiene tomando $g(x) = x$, y también se le conoce como **media** de $X$.

!!!teorema:Propiedades
Se verifican las siguientes propiedades:
* $E[a] = a$ para cualquier constante $a\in R$ (considerando $a$ como la función constante que siempre devuelve $a$).
* $E[af(X)] = aE[f(X)]$ para cualquier constante $a\in R$.
* (Linealidad de la Esperanza) $E[f(X) + g(X)] = E[f(X)] + E[g(X)]$.
* $E[\mathbf{1}_{ X = k }] = P(X = k)$.
## Varianza
!!!def:Varianza
La **varianza** de una variable aleatoria, $X$, es una medida de cómo de concentrada está la distribución alrededor de su media. Formalmente, se define como:
$$Var[X] = E[(X - E(X))^2]$$
Usando las propiedades de la sección anterior podemos dar expresiones alternativas de la varianza:
$$\begin{aligned}
Var[X] &= E[(X - E[X])^2] \\
&= E[X^2 - 2E[X]X + E[X]^2]\\
&= E[X^2 ] - 2E[X]E[X] + E[X]^2\\
&= E[X^2 ] - E[X] ^2
\end{aligned}$$
!!!teorema:Propiedades
Se verifican las siguientes propiedades:
* $Var[a] = 0$, para cualquier constante $a\in \mathbb{R}$.
* $Var[af(X)] = a^2 Var[f(X)]$, para cualquier constante $a\in \mathbb{R}$.
## Algunas variables aleatorias habituales
### Discretas
!!!ejemplo
Consideraremos habitualmente las siguientes variables discretas:
* $X \sim Bernoulli(p)$ (donde $0 \leq p \leq 1$): 1, con probabilidad $p$; 0, en caso contrario.
$$p(x) =\begin{cases}
p, & \text{si } x = 1 \\
1 - p, &\text{si } x = 0
\end{cases}$$
* $X \sim Binomial(n,p)$ (donde $0 \leq p \leq 1$): El número de 1's en $n$ ejecuciones independientes de una $Bernoulli(p)$.
$$p(x) =\binom{n}{x} p^x (1-p)^{n-x}$$
* $X \sim Geometric(p)$ (donde $p > 0$): el número de intentos de una $Bernoulli(p)$ hasta que salga un 1.
$$p(x) = p(1 - p)^{x-1}$$
* $X \sim Poisson(\lambda)$ (donde $\lambda > 0$): una probabilidad sobre los enteros no negativos para modelar la frecuencia de eventos raros.
$$p(x) = e^{-\lambda}\frac{\lambda^x}{x!}$$
### Continuas
!!!ejemplo
Consideraremos habitualmente las siguientes variables continuas:
* $X \sim Uniform(a,b)$ (donde $a < b$): igual densidad de probabilidad para todos los valores reales entre $a$ y $b$.
$$f(x) =\begin{cases}
\frac{1}{(b-a)}, &\text{si } a \leq x \leq b\\
0, &\text{en otro caso}
\end{cases}$$
* $X \sim Exponential(\lambda)$ (donde $\lambda > 0$): densidad de probabilidad exponencial decreciente en $\mathbb{R}^+$.
$$f(x) =\begin{cases}
\lambda e^{.\lambda x}, &\text{si } x\geq 0\\
0, &\text{en otro caso}
\end{cases}$$
* $X \sim Normal(\mu,\sigma^2)$: también conocida como distribución Gaussiana.
$$f(x) =\frac{1}{\sqrt{2\pi} \sigma} e^{- \frac{1}{2\sigma^2}(x-\mu)^2}$$
La siguiente tabla resume las propiedades de las variables anteriores:

# Dos Variables Aleatorias
En muchas situaciones puede haber más de una cantidad que nos interese conocer durante un experimento aleatorio. Por ejemplo, en un experimento en el que tiramos una moneda diez veces, puede que nos importe tanto el número de caras que aparecen como la longitud de la serie más larga de caras consecutivas. Por ello, vamos a considerar en esta sección el trabajo con dos variables simultáneamente.
## Distribuciones conjuntas y marginales
Supongamos que tenemos dos variables aleatorias $X$ e $Y$ que miden distintas observaciones de un mismo experimento. Una manera de trabajar con estas dos variables aleatorias es considerar cada una de ellas por separado. Si lo hacemos, sólo necesitaremos $F_X(x)$ y $F_Y(y)$. Pero si queremos conocer los valores que $X$ e $Y$ toman simultáneamente durante los resultados del experimento aleatorio, necesitamos una estructura más complicada:
!!!def:Distribución Acumulativa Conjunta
La función de **distribución acumulativa conjunta** de $X$ e $Y$, definida por:
$$F_{XY}(x,y) = P(X \leq x,Y \leq y)$$
Puede demostrarse que, conociendo la función de distribución acumulativa conjunta anterior, se puede calcular la probabilidad de cualquier evento que involucre a $X$ e $Y$.
!!!teorema
La CDF conjunta, $F_{XY}(x,y)$ y las CDFs de las variables por separado, $F_X(x)$ y $F_Y(y)$, están relacionadas por:
$$F_X(x) = \lim_{y\to \infty} F_{XY}(x,y)$$ $$F_Y(y) = \lim_{x\to \infty} F_{XY}(x,y)$$
!!!def:Funciones de Distribución Marginales
En este contexto, a las funciones $F_X(x)$ y $F_Y(y)$ se les llama **funciones de distribución marginales** de $F_{XY}(x,y)$.
!!!teorema:Propiedades
Se verifican las siguientes propiedades:
* $0 \leq F_{XY}(x,y) \leq 1$.
* $\lim_{x,y\to \infty} F_{XY}(x,y) = 1$.
* $\lim_{x,y\to -\infty} F_{XY}(x,y) = 0$.
## Funciones de Masa Conjuntas y Marginales
!!!def:Función de Masa Conjunta
Si $X$ e $Y$ son variables aleatorias discretas, entonces la **función de masa conjunta** se define como $p_{XY} : \mathbb{R}\times \mathbb{R} \to [0,1]$, definida por:
$$p_{XY}(x,y) = P(X = x,Y = y)$$
Donde $0 \leq P_{XY}(x,y) \leq 1$ para todo $x,y$. y $\sum_{x\in Val(X)}\sum_{y\in Val(Y )} P_{XY}(x,y) = 1$.
La relación que existe entre la PMF conjunta y las de cada variable es:
$$p_X(x) =\sum_y p_{XY}(x,y)$$
y similarmente para $p_Y(y)$, y se denominan también **funciones de masa marginales**. En estadística, a este proceso de construir las distribuciones marginales a partir de las conjuntas se le denomina _marginalización_.
## Funciones de Densidad Conjuntas y Marginales
Sean $X$ e $Y$ variables aleatorias continuas con función de distribución conjunta $F_{XY}$. En caso de que esta función sea diferenciable en todo $x$ e $y$, podemos definir la función de densidad conjunta como:
$$f_{XY}(x,y) =\frac{\partial^2 F_{XY}(x,y)}{\partial x\partial y}$$
Como en el caso unidimensional, $f_{XY}(x,y) \neq P(X = x,Y = y)$ (es decir, que no dan información puntual, porque en el caso continuo un punto tiene medida de probabilidad nula), pero:
$$\int\int_{x\in A} f_{XY}(x,y)dxdy = P((X,Y ) \in A)$$
Podemos definir:
$$f_X(x) = \int_{-\infty}^{\infty} f_{XY}(x,y)dy$$
como la **función de densidad marginal** para $X$ (análogo para $Y$).
## Distribuciones Condicionales
Las distribuciones condicionales buscan responder preguntas que relacionan los valores que pueden tomar dos variables dentro de un mismo experimento, por ejemplo: ¿Cuál es la distribución de probabilidad sobre $Y$ cuando sabemos que $X$ toma cierto valor?.
En el caso discreto, la función de masa condicional de $X$ dado $Y$ es simplemente:
$$p_{Y|X} (y|x) = \frac{p_{XY}(x,y)}{p_X(x)}$$
suponiendo que $p_X(x)\neq 0$.

En el caso continuo la situación es técnicamente un poco más complicada porque la probabilidad de que una variable aleatoria continua tome un valor específico es 0. Ignorando este detalle, simplemente definimos, por analogía con el caso discreto, la **densidad condicional de $Y$ dado $X=x$** como
$$f_{Y|X}(y|x) =\frac{f_{XY}(x,y)}{f_X(x)}$$
suponiendo que $f_X(x) \neq 0$.
## Regla de Bayes
Una fórmula muy útil que a menudo aparece cuando intentamos derivar la expresión de la probabilidad condicional de una variable en función de otra es la **regla de Bayes**:
!!!def:Regla de Bayes
En el caso discreto:
$$P_{Y|X}(y|x) =\frac{P_{XY}(x,y)}{P_X(x)}=\frac{P_{X|Y}(x|y) P_Y(y)}{\sum_{y'\in Val(Y)} P_{X|Y}(x|y') P_Y(y')}$$
Si las variables son continuas:
$$f_{Y|X}(y|x) =\frac{f_{XY}(x,y)}{f_X(x)}=\frac{f_{X|Y}(x|y) f_Y(y)}{\int_{-\infty}^{\infty} f_{X|Y}(x|y') f_Y(y')dy'}$$
## Independencia
!!!def: Independencia
Dos variables aleatorias, $X$ e $Y$, son independientes si $F_{XY}(x,y) = F_X(x) F_Y(y)$ para todos los valores de $x$ e $y$.
!!!teorema
Equivalentemente:
* Para variables discretas: $p_{XY}(x,y) = p_X(x) p_Y(y)$, para todos $x\in Val(X)$, $y\in Val(Y)$.
* Para variables discretas: $p_{Y|X}(y|x) = p_Y(y)$, siempre que $p_X(x) \neq 0$, para todo $y\in Val(Y)$.
* Para variables continuas: $f_{XY}(x,y) = f_X(x)f_Y(y)$, para todos $x,y \in \mathbb{R}$.
* Para variables continuas: $f_{Y|X}(y|x) = f_Y(y)$, siempre que $f_X(x) \neq 0$, para todo $y\in \mathbb{R}$.
Informalmente, dos variables aleatorias, $X$ e $Y$, son independientes si _conocer_ el valor de una de ellas no tiene ningún efecto en la distribución condicional de probabilidad de la otra variable. Formalmente:
!!!teorema
Equivalentemente:
Si $X$ e $Y$ son independientes entonces para cualesquiera subconjuntos $A,B \subseteq \mathbb{R}$, se tiene que
$$P(X \in A,Y \in B) = P(X \in A)P(Y \in B)$$
Usando el resultado anterior se puede probar que si $X$ es independiente de $Y$ entonces cualquier función de $X$ es independiente de cualquier función de $Y$.
## Esperanza y Covarianza
!!!def
Supongamos que tenemos dos variables aleatorias discretas, $X$, $Y$ y $g : \mathbb{R}^2\to \mathbb{R}$. Entonces el valor esperado de $g$ viene definido como:
$$E[g(X,Y )] =\sum_{x\in Val(X)}\sum_{y\in Val(Y)} g(x,y)p_{XY}(x,y)$$
Para variables continuas la expresión análoga es:
$$E[g(X,Y )] =\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} g(x,y)f_{XY}(x,y)dxdy$$
Podemos hacer uso de este concepto para estudiar la relación entre ambas variables.
!!!def:Covarianza
En particular, la **covarianza** de ambas variables se define como:
$$Cov[X,Y ] = E[(X - E[X])(Y - E[Y ])]$$
Usando un argumento similar al que vimos para la varianza podemos reescribir:
$$\begin{aligned}
Cov[X,Y ] &= E[(X - E[X])(Y - E[Y ])] \\
&= E[XY - XE[Y ] - Y E[X] + E[X]E[Y]] \\
&= E[XY ] - E[X]E[Y ] - E[Y ]E[X] + E[X]E[Y] \\
&= E[XY ] - E[X]E[Y ]
\end{aligned}$$
Cuando $Cov[X,Y ] = 0$ decimos que $X$ y $Y$ están **no correlacionadas** (esto no significa que sean independientes).
!!!teorema:Propiedades
Se verifican las siguientes propiedades:
* (Linealidad de la esperanza) $E[f(X,Y ) + g(X,Y )] = E[f(X,Y )] + E[g(X,Y )]$.
* $Var[X + Y ] = Var[X] + Var[Y ] + 2Cov[X,Y ]$.
* Si $X$ e $Y$ son independientes, entonces $Cov[X,Y ] = 0$. El recíproco es falso, es decir, se pueden dar ejemplos de variables no correlacionadas que no son independientes.
* Si $X$ e $Y$ son independientes, entonces $E[f(X)g(Y )] = E[f(X)]E[g(Y )]$.

# Múltiples Variables Aleatorias
Las nociones e ideas introducidas en las secciones anteriores pueden generalizarse a más de dos variables aleatorias: $X_1(ω)$, $X_2(ω)$, $\dots$, $X_n(ω)$. Los resultados y definiciones se mantienen, aunque desde el punto de vista técnico obtengamos expresiones más complicadas.
(insert menu.md.html here)