**IAIC**
Búsquedas con incertidumbre
# Aproximaciones Clásicas
Cuando se trata el tema de la IA aplicada a juegos normalmente se comienza hablando de los llamados **Juegos con Información Perfecta**, generalmente basados en turnos, en los que todos los jugadores pueden acceder a toda la información disponible de los demás jugadores y donde no hay elementos de azar en la mecánica del juego (como podría ser el uso de dados). Algunos ejemplos de juegos de este tipo son el 3 en raya (Tic Tac Toe), Conecta 4, Damas, Reversi, Ajedrez, y Go, entre muchos otros.
Para este tipo de juegos se puede construir, al menos en teoría, un árbol de estados completo que contiene todos los resultados posibles, y bastaría asignar un valor de victoria o pérdida a las posibles ramas que parten del estado inicial para encontrar una estrategia con la mejor jugada posible (sería como evaluar todos los posibles futuros a partir del estado actual y seleccionar aquel que convenga más al jugador). Un algoritmo como **Minimax** se basa precisamente en esta idea evaluando la bondad de las jugadas por medio de etiquetas en los estados finales (hojas) que se propagan hasta el estado actual para decidir qué camino en el árbol (jugada) es el que ofrece mejores resultados al jugador.
El problema que presenta un algoritmo como Minimax, y otros algoritmos similares, es que el tamaño del árbol de jugadas/estados puede ser tan grande que tanto la construcción como la búsqueda dentro del árbol se vuelva impracticable, algo que ocurre con relativa facilidad si el juego tiene un mínimo de complejidad (por ejemplo, un alto promedio de movimientos disponibles por turno), haciendo que el tamaño del árbol crezca exponencialmente por niveles.
Por supuesto, en todos estos algoritmos se han proporcionado métodos para mitigar este problema, como por ejemplo **acotar la profundidad de búsqueda hacia adelante** (y posteriormente usar una función de evaluación para estimar cómo de buena es esa vía, aunque no hayamos llegado a un estado final del juego), o **podar ramas** para evitar visitar aquellas opciones de juego que, a priori, puedan resultar menos beneficiosas. Sin embargo, la mayoría de estas técnicas requieren de un conocimiento previo del juego que puede resultar difícil de obtener, y podemos encontrar casos que cubren todas las opciones, desde juegos en los que esta aproximación es óptima (como en el caso del 3 en raya), hasta aquellos para los que es posible generar jugadores artificiales de una calidad aceptable (como en el caso del ajedrez), o incluso algunos en los que estas técnicas se muestran claramente insuficientes (como en el caso del Go, sobre todo en sus versiones con tableros completos de tamaño $19\times 19$).
# Monte Carlo Tree Search
Como respuesta a este tipo de aproximaciones hace unos años surgió la técnica de **Monte Carlo Tree Search** (**Búsqueda en Árboles con MonteCarlo**) que ofrece algunas ventajas inherentes:
* se puede aplicar a **juegos con un factor de ramificación** tan **grande** que resultan inabordables con las técnicas tradicionales anteriores;
* se puede **configurar para que se detenga después de una cantidad de tiempo prefijada**, haciendo que con tiempos mayores se obtengan jugadores más fuertes;
* **no requiere** necesariamente de un **conocimiento específico del juego**, por lo que puede ser utilizado como motor de juego general;
* y es **adaptable a juegos** que incorporan **aleatoriedad** en las reglas.
Y también algunas desventajas insalvables:
* es un **método probabilístico**, por lo que no siempre tiene porqué encontrar la solución óptima;
* si realizar simulaciones de jugadas es costoso, el proceso completo puede ser inabordable.
El origen de este método se encuentra en la Tesis Doctoral de Bruce Abramson, de 1987, de título *"[The Expected-Outcome Model of Two-Player Games](http://academiccommons.columbia.edu/download/fedora_content/download/ac:142327/CONTENT/CUCS-315-87.pdf)"*, donde, en vez de usar una función de evaluación estática, combinaba una búsqueda minimax con un modelo probabilístico para generar al azar jugadas completas. Esta técnica fue depurada en trabajos posteriores, hasta que en 1992 se aplica por primera vez al juego del Go en una forma muy similar a como se entiende hoy en día. En 2006, inspirado por estos trabajos, [Remi Coulom](https://www.remi-coulom.fr/) ([Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search](https://www.remi-coulom.fr/CG2006/)) describe por primera vez la aplicación general del método de Monte Carlo aplicado a la búsqueda en árboles de juego, y acuña el término **Monte Carlo Tree Search**. Desde entonces ha sido aplicado a multitud de juegos, ampliado para trabajar sobre juegos con incertidumbre, y usado también para resolver problemas de búsqueda fuera del ámbito de los juegos, en problemas de planificación y de toma de decisiones.
En este capítulo mostraremos cómo funciona esta técnica, y nos centraremos específicamente en una variante llamada **UCBT** (**Upper Confidence Bound applied to Trees**, o en español **Cota de Confianza Superior aplicada a Árboles**).
La idea general de ir haciendo jugadas al azar desde la posición actual para muestrear cómo se comportan las distintas opciones que podemos tomar no es nueva. El problema es que, hasta ese momento, no se sabía cómo muestrear el árbol de jugadas para que los resultados obtenidos representasen con cierta fiabilidad la bondad de las opciones existentes. Esencialmente, podemos ver **cada uno de los movimientos posibles como una variable aleatoria cuyo muestreo nos informa acerca de lo bueno o malo que es dicho movimiento**. Pero, ¿qué ocurre si el árbol de jugadas se ramifica tanto (como suele ser habitual en la mayoría de los juegos interesantes) que no podemos estar seguros de que el muestreo puramente al azar realmente sea capaz de captar la estructura intrínseca del árbol? Lo ideal sería disponer de algún mecanismo que, tras el menor número posible de pruebas, indique qué jugadas son más prometedoras y en las que merece la pena invertir más tiempo de explotación. Como se puede observar, el problema sigue siendo el mismo que hemos encontrado en los algoritmos de búsqueda más básicos: ¿cómo saber cuándo explorar el árbol y cuándo explotar una rama prometedora?
La respuesta a esta pregunta vino de la mano de UCBT, y para entender cómo funciona vamos a pasar a un problema que tiene una raíz equivalente y que se había estudiado con anterioridad en relación con la toma de decisiones: **el problema de las tragaperras múltiples**.
!!!note
**Edición**: Tras la escritura de esta entrada se ha publicado [un post similar](https://int8.io/monte-carlo-tree-search-beginners-guide/) que quizás también pueda interesar al lector, ya que introduce algunas notas acerca de cómo se ha usado esta técnica para crear los famosos Alpha Go (que se [enfrentó con Lee Sedol](https://es.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol)) y [Alpha Zero](https://deepmind.com/blog/alphago-zero-learning-scratch/) (que generaliza el método para otros juegos de tablero, consiguiendo niveles increíblemente altos a partir de un conocimiento inicial nulo del juego).
## Problema de las Tragaperras Múltiples
Imaginemos que nos enfrentamos a una fila de máquinas tragaperras (al estilo de las que hay en los casinos), cada una con características diferentes, tanto en probabilidad de generar un premio como en el valor de éstos. Lo ideal sería disponer de una estrategia que permitiera maximizar la ganancia total cuando jugamos con ellas. Supongamos, además, que no hay nadie cerca jugando a las mismas máquinas, por lo que no podemos obtener información adicional sobre cuál es la mejor máquina para jugar (es decir, no podemos definir una heurística óptima a priori). La única opción es recopilar esta información personalmente, intentando equilibrar la cantidad jugada en todas las máquinas y concentrando el mayor número de jugadas en la mejor máquina observada hasta el momento.
En su versión más simple, un problema de $K$ **tragaperras** se puede definir haciendo uso de conceptos básicos de estadística por medio de una sucesión de **variables aleatorias** $\{X_{i,n}:\ 1\leq i\leq K,\ n\geq 1\}$, donde $i$ es el índice de cada tragaperras. Las jugadas sucesivas de la máquina $i$ dan lugar a una sucesión $X_{i,1}$, $X_{i,2}$, ..., **independientes e idénticamente distribuidas** siguiendo una distribución desconocida de **media** $\mu_i$. Además, también pedimos que haya **independencia entre las máquinas**, es decir, que para cada $1\leq i < j\leq K$, y $s,t \geq 1$, se tiene que $X_{i,s}$ y $X_{j,t}$ son independientes (aunque, normalmente, no serán idénticamente distribuidas, ya que cada máquina puede seguir una distribución distinta).
En estas condiciones, una **estrategia** (**policy**) es un algoritmo $A$ que elige la siguiente máquina en la que jugar basándose en la secuencia de jugadas anteriores y en los premios recibidos. Si $T_i(n)$ es el número de veces que el algoritmo $A$ ha seleccionado la máquina $i$ durante las primeras $n$ jugadas, entonces la **pérdida esperada** de la estrategia $A$ (es decir, lo que no hemos ganado por no haber elegido siempre la mejor máquina posible) se puede calcular como:
$$\mu^* n - \sum_{i=1}^K \mu_i\ E[T_i(n)]$$
donde $\mu^*=max_{1\leq i\leq K}\mu_i$ representa la mejor jugada posible (desconocida).
Apoyándonos en algunos resultados de estadística, podemos hacer uso de una estrategia, llamada **UCB1** (**Upper Confidence Bound**, [Kocsis y Szepesvári](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.102.1296&rep=rep1&type=pdf)), que construye intervalos estadísticos de confianza para cada máquina de la forma:
$$\left[ \overline{X_i}(n) - \sqrt{\frac{2\ln n}{T_i(n)} }\ ,\ \overline{X_i}(n) + \sqrt{\frac{2\ln n}{T_i(n)} } \right]$$
donde, $\overline{X_i}(n)$ es la media de ganancias experimental que ofrece la máquina $i$ tras los $n$ pasos (que se puede calcular como la suma de los premios recibidos en esa máquina dividido entre el número de veces que se ha jugado en ella, si en un paso $j\leq n$ no se ha jugado esa máquina, entonces $X_{i,j}=0$): $$\overline{X_i}(n) = \frac{\sum_{j\leq n} X_{i,j} } {T_i(n)}$$
La [Ley de los Grandes Números](https://es.wikipedia.org/wiki/Ley_de_los_grandes_n%C3%BAmeros) nos asegura que $\lim_{T_i(n)\to \infty} \overline{X_i}(n) = \mu_i$. Por tanto, una estrategia válida sería escoger siempre la máquina que tenga el mayor límite superior de este intervalo. Al usar esa máquina, el valor medio observado en ella se desplazará a su valor real y su intervalo de confianza se reducirá (ya que en esta máquina $T_i(n)$ aumenta más rápido que $\ln n$), a la vez que todos los intervalos de las otras máquinas se van ampliando (ya que, para esas otras máquinas, el valor de $T_i(n)$ permanece constante mientras no las usemos, pero $\ln n$ crece). Eventualmente, alguna de las otras máquinas podrá tener un límite superior mayor al de la máquina seleccionada actual, y entonces lo mejor será cambiar a esa otra máquina.
Esta estrategia verifica que la diferencia entre lo que hubiéramos ganado jugando únicamente en la mejor máquina y las ganancias esperadas bajo la estrategia usada crece sólo como $O(\ln n)$ (es decir, perdemos poco respecto a la mejor jugada posible), que es la misma tasa de crecimiento que la mejor estrategia teórica para este problema (denominado **Problema de Tragaperras Múltiples**), y tiene el beneficio adicional de ser muy fácil de calcular, ya que basta llevar un contador para cada máquina.
Existen otras estrategias que ofrecen un rendimiento similar, pero UCB1 es posiblemente la estrategia más simple con este buen comportamiento, así que será suficiente para la primera aproximación que estamos ofreciendo aquí.
Puedes ver cómo funciona esta estrategia con ayuda de [este modelo](./modelos/MultiBandits.nlogo).
## Aplicación a Búsquedas
Y aquí es donde entra en juego el **método de Monte Carlo aplicado a búsquedas** usando la estrategia anterior, donde el papel que juegan las diferentes tragaperras se cambian por las diversas transiciones válidas en la búsqueda (en juegos, las jugadas válidas), y los premios de las máquinas se cambian por la bondad del camino encontrado (en juegos, por la recompensa de la sucesión de movimientos realizados).
En un proceso estándar de MonteCarlo aplicado a un juego:
1. Se generan un gran número de simulaciones aleatorias desde el estado actual para el que se desea encontrar el mejor movimiento siguiente;
2. se almacenan las estadísticas para cada movimiento posible a partir de este estado inicial y,
3. se devuelve el movimiento con los mejores resultados generales.
Así descrito, la desventaja de este método general es que, para cualquier turno, puede haber muchos movimientos posibles pero sólo uno o dos que son buenos, por lo que, si se elige un movimiento aleatorio en cada turno, es extremadamente improbable que la simulación proporcione el mejor camino hacia la solución perfecta.
Ante este problema se han propuesto variantes, como la llamada **UCT** que presentaremos a continuación, que suponen una mejora que permite minimizar los riesgos, y que se basa en la idea de que, si tenemos estadísticas de bondad disponibles para todos los estados sucesores del estado actual, entonces podemos extraer una estadística de bondad para el mismo... de forma similar a como se hace en el problema de las tragaperras múltiples anterior.
En vez de hacer muchas simulaciones puramente aleatorias, esta variante hace muchas iteraciones de un proceso que consta de varias fases y que tiene como objetivo mejorar nuestra información del sistema (**exploración**) a la vez que potencia aquellas opciones más prometedoras (**explotación**):
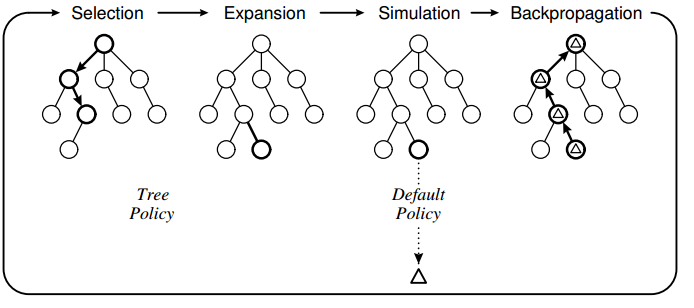
1. La primera fase, **Selección**, se realiza mientras tengamos las estadísticas necesarias para tratar cada nodo/estado alcanzado como un problema de tragaperras múltiples. Comenzando por el nodo raíz, que representa el estado actual del juego/problema, seleccionamos recursivamente el nodo más urgente de acuerdo a una función de utilidad (en nuestro caso, por medio del algoritmo UCB1), hasta que se alcanza un nodo que, o bien representa un estado terminal, o bien no está completamente extendido (es decir, un nodo en el que hay posibles movimientos o acciones que no han sido consideradas).
2. La segunda fase, **Expansión**, ocurre cuando ya no se puede aplicar la fase anterior. Para ello, se elige aleatoriamente una posición sucesora no visitada del nodo que no estaba completamente extendido y se añade un nuevo nodo al árbol de estadísticas con el fin de completar dicha información.
3. Tras la expansión, nos encontramos en la fase de **Simulación**, que sigue los mismos parámetros de una simulación típica de MonteCarlo. Es decir, partiendo del estado recién añadido se simula una partida completa, ya sea al azar, con una simple heurística de ponderación, o utilizando heurísticas y evaluaciones computacionalmente costosas para una estrategia más elaborada (para juegos con un factor de ramificación pequeño, como el 3 en raya, una simple heurística de ponderación puede dar buenos resultados). Junto a la partida completa se obtiene un valor (premio, recompensa, etc) que determina la utilidad de esa rama para el jugador.
4. Finalmente, la cuarta fase es la de **Actualización** o **Retropropagación**. Con el estado final de juego alcanzado en la fase anterior se actualizan las estadísticas de todas las posiciones previas visitadas durante la simulación completa que se ejecutó a partir del nuevo nodo (incluyendo la cuenta de ganancias si el jugador ganó la simulación).

Obsérvese que en este proceso hay tres estrategias involucradas:
* Estrategia de **selección de nodos del árbol** según su utilidad (en la fase de selección). Hay muchas opciones, por ejemplo: seleccionar el sucesor con mayor ganancia, el que ha sido visitado en mayor número de partidas ganadoras, el que verifique las dos condiciones anteriores (si no lo hay, se sigue realizando la búsqueda hasta que haya uno que lo verifique), o el que maximiza la estrategia UCB1 explicada anteriormente.
* Estrategia de **creación de nuevos nodos** (en la fase de expansión). Es normal elegir una creación aleatoria uniforme entre las acciones disponibles, pero si se dispone de alguna información adicional del problema se puede usar para decidir qué acción tomar (y, en consecuencia, qué nodo se crea).
* Estrategia de **generación de una partida completa** a partir del nuevo nodo creado (en la fase de simulación). Aquí es relativamente común introducir, si se considera necesario, algún conocimiento específico del dominio del problema (del juego).
Este algoritmo se puede configurar para detenerse tras un período de tiempo deseado, o bajo cualquier otra condición deseada. A medida que se van ejecutando más y más simulaciones, el árbol de estadísticas crece en memoria y el movimiento que finalmente se elija converge hacia el movimiento óptimo real (aunque esta convergencia puede requerir muchísimo tiempo, dependiendo del juego), como ocurre en el problema de las tragaperras múltiples.
En el caso de aplicar el algoritmo UCB1 como estrategia de selección del nodo siguiente el objetivo es maximizar la fórmula equivalente siguiente (y que al aplicarla a la búsqueda en árboles pasa a llamarse **UCT**, **Upper Confidence on Trees**):
$$UCT(s)=\frac{Q(s)}{N(s)}+2 C_p\sqrt{\frac{\ln N(s_0)}{N(s)} }$$
donde $N(s_0)$ es el número de veces que el nodo $s_0$ (el padre de $s$) ha sido visitado, $N(s)$ es el número de veces que el nodo hijo, $s$, ha sido visitado, $Q(s)$ es la recompensa total de todas las jugadas que pasan a través del nodo $s$, y $C_p > 0$ es constante.
El término $\overline{X_i}(s)$ de UCB1 se reemplaza aquí por $\frac{Q(s)}{N(s)}$, que representa la recompensa media de todas las jugadas. Cuando $N(s)=0$, es decir, el sucesor nunca se ha visitado (todavía), el valor de UCT toma el valor infinito y, por tanto, el sucesor sería elegido por la estrategia. Esta es la razón por la que esta fórmula solo se utiliza en caso de que todos sus hijos hayan sido visitados al menos una vez. Al igual que en la fórmula de UCB1, hay un equilibrio entre el primer término (explotación) y el segundo (exploración). La contribución del término de exploración decrece a medida que se visita cada estado (que se visita), ya que aparece en el denominador. Por otra parte, el término de exploración crece cuando se visita otro sucesor de su nodo padre (un hermano suyo). De esta forma, el término de exploración asegura que incluso sucesores con recompensas bajas sean seleccionados si se da el tiempo suficiente.

La constante del término de exploración $C_p$ se puede escoger para ajustar el nivel de exploración deseado. Kocsis y Szepesvári demostraron que $C_p = 1/\sqrt{2}$ es un valor óptimo cuando las recompensas/ganancias se encuentran en el intervalo $[0, 1]$, pero en otros casos el valor adecuado de $C_p$ debe ser determinado experimentalmente.
Además, Kocsis y Szepesvári también demostraron que la probabilidad de seleccionar una acción subóptima (es decir, no la mejor) para la raíz del árbol tiende a $0$ a velocidad polinomial si el número de iteraciones tiende a infinito, lo que significa que, con suficiente tiempo y memoria, UCT tiende al árbol Minimax y por tanto es óptimo.
## El Algoritmo
El algoritmo descrito informalmente puede expresarse en pseudocódigo como sigue: donde `n` es el nodo del árbol MCTS que se está construyendo; `s(n)` es el estado del problema asociado al nodo `n`; `A(s)` es el conjunto de acciones que se pueden aplicar en el estado `s`; y, si `a ∈ A(s)`, entonces `a(s)` es el estado resultante de aplicar la acción `a` sobre `s`.
!!!alg: Algoritmo UCT
~~~~~~none
Función: MCTS-UCT(s₀)
Crear nodo raíz n₀ con estado s₀
Mientras haya recursos computacionales
n ← Seleccion(n₀)
G ← Simula(s(n))
Retropropaga(n,G)
Devuelve a tal que a(s(n₀)) = MejorHijo(n₀)
Función: Seleccion(n)
Mientras s(n) no sea terminal
Si n no está completamente expandido, entonces
Devuelve Expande(n)
si n está completamente expandido, entonces:
n ← MejorSucesorUCT(n,c)
Devuelve n
Función: Expande(n)
a ← elige acción no probada de A(s(n))
Añadir un nuevo sucesor m de n
s(m) ← a(s(n)))
a(m) ← a
Devuelve m
Función: MejorSucesorUCT(n)
Devuelve argmax UCT(n)
Función: Simula(s)
Mientras s no sea terminal
a ← un elemento de A(s)
s ← a(s)
Devuelve ganancia del estado s
Procedimiento: Retropropaga(n,G)
Mientras n no sea nulo
N(n) ← N(n) + 1
Q(n) ← Q(n) + G
n ← Padre de n
~~~~~~~~
Una versión simplificada de este algoritmo se consigue haciendo que la recompensa esté limitada a 3 posibles valores: 1, cuando el jugador gana; 0, cuando el jugador pierde; y 0'5, cuando se produce un empate entre ambos jugadores (llamado tablas en algunos juegos de tablero).

Puedes encontrar en [este link](https://citeseerx.ist.psu.edu/pdf/c37f1baac3c8ba30250084f067167ac3837cf6fd) un estudio muy interesante sobre MCTS y sus variantes y aplicaciones. La [página de la wikipedia](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search) (fuertemente basada en el estudio anterior) puede ser también un primer punto de contacto para aprender algo más sobre el método.