**Toma de Decisiones bajo Incertidumbre**
**(y Aprendizaje por Refuerzo ... con Julia)**
Máster Propio en Data Science y Big Data
Fernando Sancho Caparrini
Dpt. Ciencias de la Computación e Inteligencia Artificial
Universidad de Sevilla
---
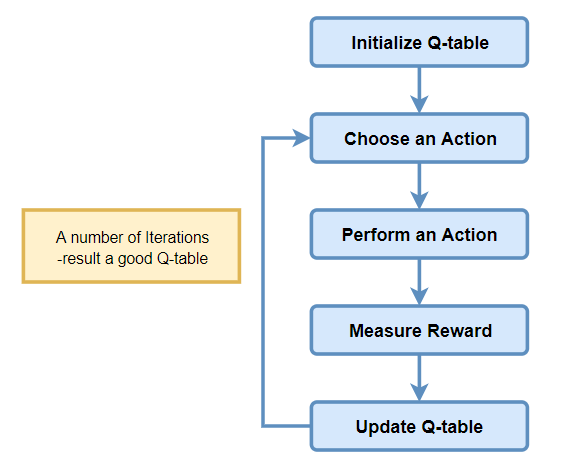
## Objetivos
!!!def: Doble objetivo:
1. Presentar los fundamentos de la Toma de Decisiones bajo Incertidumbre (y Aprendizaje por refuerzo).
1. Presentar Julia como lenguaje para la Computación Científica (definiremos los conceptos desde la base, y usaremos también el paquete `POMDPs.jl`).
!!!Tip:Tareas a abordar:
1. ¿Por qué Julia?.
1. Fundamentos de la Toma de Decisiones y sus aplicaciones.
1. Primer contacto con la librería `POMDPs.jl`.
... será un recorrido liviano e incompleto ...
---
# Por qué Julia
---
## ¿Por qué se creó Julia?
Julia ha sido diseñado para ser rápido y dinámico. En palabras de sus desarrolladores:
!!!Tip
*Queríamos un lenguaje que fuera de código abierto, con una licencia liberal. Queremos la velocidad de C con el dinamismo de Ruby. Queremos un lenguaje que sea homoicónico, con verdaderas macros como Lisp, pero con una notación matemática obvia y familiar como Matlab. Queremos algo tan útil para la programación general como Python, tan fácil para la estadística como R, tan natural para el procesamiento de cadenas como Perl, tan potente para el álgebra lineal como Matlab, tan bueno para unir programas como el shell de Linux. Algo que sea sencillísimo de aprender, pero que mantenga contentos a los hackers más serios. Lo queremos interactivo y compilado.*
([Why We Created Julia](https://julialang.org/blog/2012/02/why-we-created-julia/), por Jeff Bezanson, Stefan Karpinski, Viral B. Shah, Alan Edelman)
Pero más famoso que este texto de motivación, un famoso lema que quedó en las primeras versiones de Julia (2012):
!!!warning
*Camina como Python, corre como C.*
De hecho, hay una comparación más que se perdió con el tiempo, quizás por lejanía con el programador más actual:
!!!
*Camina como Python, se siente como Lisp, corre como C.*
---
## Velocidad
Julia es uno de los pocos lenguajes que forman parte del exclusivo club de los `petaflops` (junto con C, C++ y Fortran).

---
## El problema de los dos lenguajes
* Los lenguajes *interpretados*, como Python y R, traducen las instrucciones línea a línea.
* Los lenguajes compilados, como C/C++ y Fortran, son traducidos por un compilador antes de ejecutar el programa.
Lenguajes interpretados:
* Más fáciles de leer y escribir (hay que proporcionar menos información sobre tipos y memoria, ...).
* Por tanto, la productividad del programador es mayor.
Lenguajes compilados:
* Suelen ser órdenes de magnitud más rápidos (optimización durante la traducción a ensamblador).
Julia:
* Julia parece un lenguaje interpretado.
* Antes de una ejecución, la LLVM del motor de Julia la compilará **JIT**.
* Se obtiene la flexibilidad de un lenguaje interpretado y la velocidad de un lenguaje compilado.
* Hay que esperar un poco más para la primera ejecución de cualquier función (pero se cachean).
---
## Componibilidad
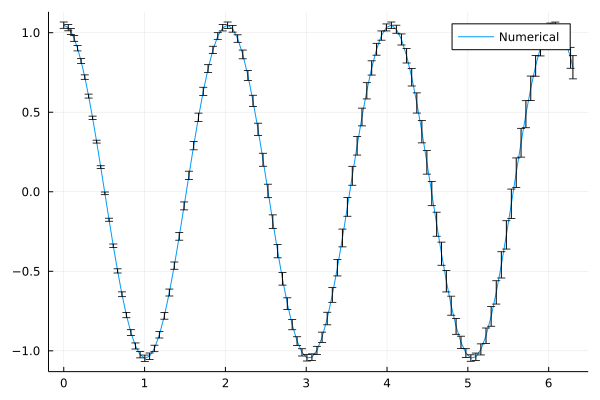
Ejemplo: Interacción entre `DifferentialEquations.jl` (ecuaciones diferenciales) y `Measurements.jl`(magnitudes con incertidumbre). La ecuación diferencial (de segundo orden) que rige el movimiento del péndulo es: $\ddot{\theta} + \frac{g}{L}\theta = 0$
!!!def:Ejemplo Componibilidad
```C
using DifferentialEquations, Measurements, Plots
g = 9.79 ± 0.02; # Constante Gravitacional
L = 1.00 ± 0.01; # Longitud del Péndulo
# Condiciones Iniciales
u₀ = [0 ± 0, π / 3 ± 0.02] # Velocidad y Ángulos iniciales
tspan = (0.0, 6.3)
function simplependulum(du,u,p,t) # Definición del problema
θ = u[1]
dθ = u[2]
du[1] = dθ
du[2] = -(g/L) * sin(θ)
end
# Llamada al solver
prob = ODEProblem(simplependulum, u₀, tspan)
sol = solve(prob, Tsit5(), reltol = 1e-6)
plot(sol.t, getindex.(sol.u, 2), label = "Péndulo")
```
---
## Componibilidad
El resultado es una aproximación numérica que ofrece, además, el error esperado en cada evaluación, y que se debe a la imprecisión de los datos de entrada que se dieron al solver diferencial:
---
## Inconvenientes y soluciones
Algunas de las características que más llaman la atención del programador recién llegado a Julia (positivas y negativas):
* Tiempo empleado para la primera ejecución y primera carga de librerías.
- `PackageCompiler.jl` permite crear un paquete precompilado que incluye las librerías base de Julia y que se pueda ejecutar en un ordenador diferente.
* Ecosistema menos extenso que, por ejemplo, los de Python y R.
- Puede usar librerías externas de Python, R o C/C++.
- Escribir código de Julia usando la componibilidad y potencia de sus paquetes.
* Ecosistema menos maduro.
- Gestor de paquetes muy potente y sencillo con extensa creación de entornos personalizados.
---
# Toma de Decisiones bajo Incertidumbre
---
## Generalidades
!!!def: Toma de decisiones
Proceso dinámico mediante el cual un **agente inteligente** selecciona una acción entre varias opciones posibles para lograr un objetivo o resolver un problema.
!!!Tip
En este sentido, muchas veces se distingue entre:
* objetivos de **un paso** (si toda nuestra meta se obtiene en una sola acción del agente),
* de **horizonte finito** (cuando el número de acciones del agente está acotado por una longitud conocida a priori),
* de **horizonte infinito** (cuando no estamos en las condiciones anteriores).
!!!def: Agente
Programa o entidad autónoma que puede percibir su entorno y actuar en, y sobre, él para alcanzar sus objetivos.
La toma de decisiones en agentes se basa en la utilización de algoritmos y técnicas de inteligencia artificial que permiten al agente evaluar las opciones disponibles y seleccionar la acción más adecuada. Para ello, el agente debe contar con información sobre su entorno, los objetivos que se pretenden alcanzar y las posibles acciones que puede tomar.
---
## Generalidades
En general, la toma de decisiones por parte de agentes se divide en dos fases:
* En la **fase de observación**, el agente recopila información sobre su entorno mediante *sensores* y procesa la información para obtener una representación adecuada del estado actual del entorno.
* En la **fase de acción**, el agente selecciona la acción más adecuada para lograr sus objetivos y la ejecuta mediante *actuadores*.
!!!def: Ciclo Observación-Acción
Más detalladamente, el **ciclo de observación-acción** que se genera por la interacción entre el agente y el entorno puede modelarse como:
1. El agente, en el momento $t$, recibe una **observación** del entorno, $o_t$. Las observaciones son a menudo incompletas o ruidosas.
2. Con el fin de alcanzar un **objetivo predefinido**, el agente elige entonces una **acción**, $a_t$, a través de un proceso de **toma de decisiones**, que puede tener un efecto (a veces, no determinista, debido a múltiples fuentes de incertidumbre) en el entorno.
---
## Incertidumbre
Entre las diversas fuentes de incertidumbre que pueden intervenir en la capacidad del agente para **elegir la acción** que le acerque a sus objetivos de **la mejor manera posible** podemos destacar, fundamentalmente, las cuatro siguientes (no excluyentes entre sí):
!!!def: Tipos de Incertidumbre
- **Incertidumbre en los resultados**: los efectos de las acciones realizadas por el agente son inciertos.
- **Incertidumbre del modelo**: nuestro modelo del problema es incierto.
- **Incertidumbre de estado**: el estado real del entorno es incierto.
- **Incertidumbre de interacción**: el comportamiento de los demás agentes que interactúan en el entorno es incierto.
La toma de decisiones en presencia de incertidumbre debería ser óptimo incluso bajo fuertes condiciones de incertidumbre:
!!!Tip
Los **algoritmos** que buscamos para tomar decisiones tendrán como requisito ser **robustos frente a la incertidumbre**.
---
## Métodos
Los métodos más comunes para abordar este diseño son:
1. **Programación explícita**.
El método más directo, y más ingenuo, para diseñar un agente con capacidad de decisión es **anticipar todos los escenarios** en los que el agente podría encontrarse **y programar explícitamente la respuesta** que el agente debería dar a cada uno de ellos.
Este enfoque puede funcionar bien para problemas sencillos, pero supone una gran carga para el diseñador a la hora de proporcionar una estrategia completa y es difícil tener en cuenta la casuística combinada de eventos simultáneos.
Aunque se han propuesto varios lenguajes y marcos de programación de agentes para facilitar la programación de los mismos, todos ellos presentan limitaciones frente a problemas complejos del mundo real. Por ello, cada vez es más frecuente combinar la programación explícita en un marco especializado en agentes con cualquiera de los otros métodos.
---
## Métodos
2. **Aprendizaje supervisado**.
En aquellos problemas en los que disponemos de suficiente casuística almacenada en forma de datos puede ser más fácil y provechoso mostrar a un agente lo que debe hacer que escribir un programa explícito que lo dirija. El diseñador proporciona un conjunto de ejemplos de entrenamiento que incluyen la acción ideal a tomar, y un **algoritmo de aprendizaje automático debe generalizar** a partir de estos ejemplos para seleccionar la acción óptima y responder ante situaciones novedosas (aunque cercanas a ejemplos presentes en el aprendizaje). Este enfoque se conoce como **aprendizaje supervisado** (en el contexto que estamos también se le denomina *clonación del comportamiento*), y funciona bien cuando un diseñador experto conoce realmente la elección de la mejor acción para una colección representativa de situaciones.
Aunque existe una gran variedad de algoritmos de aprendizaje supervisado, por lo general no suelen funcionar mejor que los diseñadores humanos en situaciones nuevas, pero sí permiten extraer un comportamiento automático óptimo en muchos casos en los que no se tienen ejemplos representativos, y facilita enormemente el diseño del agente cuando la casuística es variada.
---
## Métodos
3. **Optimización**.
Otro enfoque consiste en que el diseñador especifique el **espacio de posibles estrategias de decisión y una medida de rendimiento que debe maximizarse**. La evaluación del rendimiento de una estrategia de decisión suele implicar la ejecución de un lote de simulaciones. Por medio de la aplicación de un algoritmo de optimización, se realiza entonces una búsqueda de la estrategia óptima en este espacio.
Su validez y forma de optimización depende en gran medida de las condiciones del espacio (por ejemplo, de su tamaño, de si la medida de rendimiento no tiene muchos óptimos locales, etc.), lo que puede orientar acerca del método para encontrar el óptimo.
---
## Métodos
4. **Planificación**.
La planificación es una forma de **optimización que utiliza un modelo de la dinámica del problema para ayudar a guiar la búsqueda del óptimo**. Una gran parte de la literatura explora diversos problemas de planificación, **habitualmente centrada en problemas deterministas**, que es una aproximación aceptable para algunos problemas porque permite utilizar métodos que pueden escalar más fácilmente a problemas de alta dimensión. Para otros problemas, sin embargo, es fundamental tener en cuenta la incertidumbre futura, que es el marco en el que nos queremos centrar.
---
## Métodos
5. **Aprendizaje por refuerzo**.
El aprendizaje por refuerzo **relaja la suposición que se impone en la planificación de que se conoce un modelo de antemano**. En su lugar, la **estrategia de toma de decisiones se aprende mientras el agente interactúa con el entorno**. El diseñador proporciona una medida de rendimiento, y es el algoritmo de aprendizaje el que debe optimizar el comportamiento del agente.
Uno de los problemas más interesantes que surgen en el aprendizaje por refuerzo es que la elección de la acción no solo afecta al éxito inmediato del agente en la consecución de sus objetivos, sino también a la capacidad del agente para aprender sobre el entorno e identificar las características del problema que puede explotar.
---
# Decisiones Secuenciales
---
## Decisiones Secuenciales
Es el caso más interesante:
!!!def: Decisiones Secuenciales
El agente no toma una única decisión, sino que ha de tomar una sucesión de decisiones secuenciales de las que depende el éxito o no del objetivo a cumplir.
En la **toma de decisiones secuenciales** resolver un problema consiste en:
* realizar acciones (tomar decisiones) de forma consecutiva y
* que aseguren la consecución de los objetivos planteados al agente.
!!!Tip
La ejecución de cada una de las acciones puede conllevar un cambio dinámico en el propio entorno del problema: las acciones que se tomen en un momento afectarán al mundo y, consecuentemente, a las posibles acciones que se puedan tomar en el futuro y a las condiciones concretas del entorno de resolución.
!!!def: Programación Dinámica
La aproximación más famosa para la resolución de este tipo de problema son los **Procesos de Decisión de Markov** (MDP). Presentada originalmente por R.E. Bellman en la década de los 50 (_Dynamic Programming_).
---
## Elementos de la Toma de Decisiones Secuencial
Además del agente y el entorno, se pueden identificar cuatro elementos principales de un sistema de toma de decisiones secuencial:
!!!def:Elementos
1. **Política**: define la forma de actuar del agente en un momento dado. Es un mapeo desde los estados percibidos del entorno hasta las acciones que se deben tomar cuando se encuentra ante cada estado. En general, son estocásticas.
1. **Señal de recompensa**: define el objetivo de la toma de decisiones. En cada paso de tiempo, el entorno envía al agente un único valor real llamado **recompensa**, que define cuáles son los eventos *buenos* y *malos* a corto plazo. La señal de recompensa es la base principal para modificar la política.
1. **Función de Valor**: el valor de un estado es la cantidad total de recompensa que un agente puede esperar acumular en el futuro partiendo de ese estado y usando su política como medio de decisión.
1. **Modelo del Entorno**: *algo* que *imita* el comportamiento del entorno o que permite hacer inferencias sobre cómo se comportará el entorno. Si disponemos de un modelo, podemos adelantarnos a la evolución del sistema e inferir más sencillamente en qué situación nos encontraríamos si realizáramos ciertas acciones sin necesidad de ejecutarlas (permite la previsión).
---
## Procesos de Decisión de Markov
!!!def:Proceso de Decisión de Markov
Un **Proceso de Decisión de Markov** (**MDP**) se define por la tupla $(S, A, T, R, γ)$, donde:
* $S$: **conjunto de estados**, $s$, del entorno.
* $A$: **conjunto de acciones**, $a$, que puede realizar un agente. En algunos estados, ciertas acciones no están permitidas, es decir, sólo se puede realizar un subconjunto de las acciones, denotado por $A_s$.
* $T$: **función de transición**. $T(s'|s,a)$ indica la probabilidad de que el entorno pase al estado $s'$ desde el estado $s$ cuando un agente realiza la acción $a$.
* $R$: **recompensa**. $R(s'|s,a)$ denota la recompensa recibida cuando se realiza la acción $a$ y el entorno pasa del estado $s$ al estado $s'$.
* $γ$: **factor de descuento**, $γ ∈ [0, 1)$, que da más peso a la recompensa presente que a la recompensa futura.
El estado evoluciona de forma probabilística en función del estado actual y de la acción que realicemos.
!!!
**Propiedad o suposición de Markov**: el siguiente estado depende solo del estado y la acción actuales y no de ningún estado o acción anteriores.
---
## Procesos de Decisión de Markov
Para un mundo **determinista**, $T(s'|s,a)$ será $0$ para todos los $s'$ excepto uno, para el que será $1$. En un entorno **no determinista** la acción de un agente podría conducir a un conjunto de estados diferentes, dependiendo del valor de esta función de probabilidad fija.
![Figura [MDP]: Ejemplo sencillo de MDP](img\sma1-1.png width="75%")
---
## Procesos de Decisión de Markov
En un problema de **horizonte finito** con $n$ decisiones, la **utilidad** asociada a una secuencia de recompensas $\{r_i\}_{1\leq i\leq n}$ es:
$$U=\sum_{t=1}^n r_t$$
!!!Tip
En un problema de **horizonte infinito** en el que el número de decisiones es ilimitado, la suma de recompensas puede llegar a ser infinita.
En este caso, la forma más habitual es considerar un **factor de descuento**, $\gamma \in [0,1)$, y entonces:
$$U=\sum_{t=1}^\infty \gamma^{t-1}r_t$$
Podemos representar un MDP en Julia usando la siguiente estructura de datos, que sigue completamente la formalización matemática que hemos dado, es decir: `(𝒮, 𝒜, T, R, γ)`.
!!!def: Estructura MDP
~~~~C
struct MDP
𝒮 # Espacio de Estados
𝒜 # Espacio de Acciones
T # Función de Transición
R # Función de Recompensa
γ # Factor de Descuento
end
~~~~
---
## Ejemplo MDP: Grid World
!!!
En el problema **Grid World** un agente se mueve por una malla intentando recolectar la mayor cantidad de recompensa posible (señalados como celdas verdes), evitando las recompensas negativas (celdas rojas).

---
## Ejemplo MDP: Estados
!!!
Los posibles estados pueden representarse como el conjunto de celdas $(x,y)$ de la malla $10\times 10$ (por tanto, $S$ es discreto y $|S|=100$).

---
## Ejemplo MDP: Estados
!!!def: Estados
~~~~~~C
using POMDPs, POMDPModelTools, QuickPOMDPs
struct State # Defición del Estado
x::Int
y::Int
end
𝒮 = [[State(x,y) for x=1:10, y=1:10]..., State(-1,-1)] # Espacio de Estados
~~~~
---
## Ejemplo MDP: Acciones
!!!
Las posibles acciones son los movimientos en las 4 direcciones cardinales (arriba/up, abajo/down, izquierda/left, derecha/right) (por tanto, $A$ es discreto y $|A|=4$).

---
## Ejemplo MDP: Acciones
!!!def:Acciones
~~~~~~C
@enum Action UP DOWN LEFT RIGHT # Definición de Acciones
𝒜 = [UP, DOWN, LEFT, RIGHT] # Espacio de Acciones
const MOVEMENTS = Dict( # Movimientos / Ejecución de Acciones
UP => State(0,1),
DOWN => State(0,-1),
LEFT => State(-1,0),
RIGHT => State(1,0)
)
Base.:+(s1::State, s2::State) = State(s1.x + s2.x, s1.y + s2.y) # Auxiliar para ejecutar acciones
~~~~
---
## Ejemplo MDP: Función de Transición
!!!
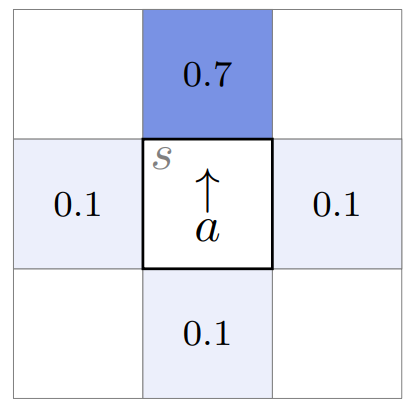
La función de transición es estocástica (incorpora aleatoriedad/incertidumbre): una vez que el agente decide realizar una acción (de las 4 disponibles) tiene un 70% ($0.7$) de posibilidad de ejecutarla, y un 10% ($0.1$) de ejecutar cualquier de las otras 3.
---
## Ejemplo MDP: Función de Transición
!!!def: Función de Transición
~~~~~~C
function T(s, a)
R(s) != 0 && return Deterministic(State(-1,-1))
Nₐ = length(𝒜)
next_states = Vector{State}(undef, Nₐ + 1)
probabilities = zeros(Nₐ + 1)
for (i, a′) in enumerate(𝒜)
prob = (a′ == a) ? 0.7 : (1 - 0.7) / (Nₐ - 1)
s' = s + MOVEMENTS[a′]
next_states[i+1] = s'
if 1 ≤ s'.x ≤ 10 && 1 ≤ s'.y ≤ 10
probabilities[i+1] += prob
end
end
(next_states[1], probabilities[1]) = (s, 1 - sum(probabilities))
return SparseCat(next_states, probabilities)
end
~~~~~~
---
## Ejemplo MDP: Función de Recompensa
!!!
La función de recompensa se da explícitamente: dos celdas (verdes) de recompensa positiva, y dos celdas (rojas) de recompensa negativa. El resto de celdas tienen recompensas nulas.

---
## Ejemplo MDP: Función de Recompensa
!!!def: Función de Recompensa
~~~~~~C
function R(s, a=missing)
if s == State(4,3)
return -10
elseif s == State(4,6)
return -5
elseif s == State(9,3)
return 10
elseif s == State(8,8)
return 3
end
return 0
end
~~~~~~
---
## Ejemplo MDP: Factor de Descuento
!!!
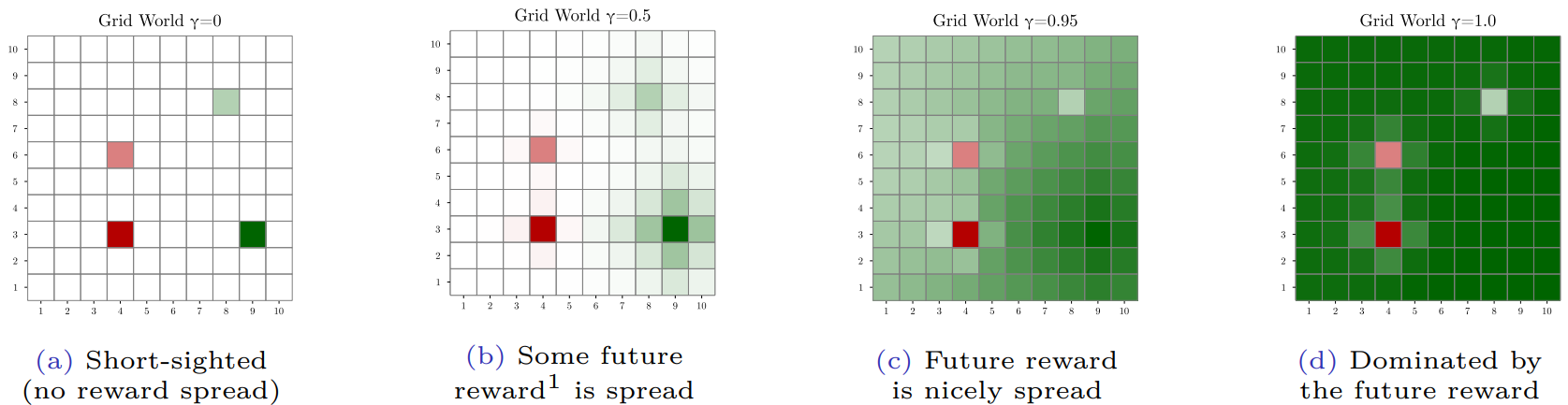
El factor de descuento controla lo miope (corto de miras) que es el agente en su toma de decisiones (por ejemplo, cuando $γ = 0,$ el agente sólo se preocupa por las recompensas inmediatas (miope) y a medida que $γ → 1$, el agente tiene en cuenta la información potencial futura en su proceso de toma de decisiones.
---
## Ejemplo MDP: Definición MDP
!!!def: Definición MDP
~~~~~~C
abstract type GridWorld <: MDP{State, Action} end
mdp = QuickMDP(GridWorld,
states = 𝒮,
actions = 𝒜,
transition = T,
reward = R,
discount = 0.95,
isterminal = s -> s == State(-1,-1)
)
~~~~~~
---
## Políticas y Funciones de Valor
!!!def:Políticas y Utilidades
Una **política** es una función: $\pi:S\to A$.
La **utilidad esperada/función de valor** de ejecutar $\pi$ desde el estado $s$ se denota como $U^\pi(s)$.
Una **política óptima** $\pi^*$ es una política que maximiza la utilidad esperada o función de valor:
$$\pi^*(s)=\arg \max_\pi U^\pi(s),\ \forall s\in S$$
Dependiendo del modelo, puede haber múltiples políticas que sean óptimas. La función de valor asociada a una política óptima $\pi^*$ se denomina **función de valor óptima** y se denota como $U^*$.
!!!Tip
Se puede encontrar una **política óptima** utilizando **programación dinámica**.
En general, los algoritmos que utilizan programación dinámica para resolver MDPs son mucho más eficientes que los métodos de fuerza bruta.
---
## Evaluación de políticas
!!!def: Evaluación de la Política
Cálculo de la función de valor $U^\pi$ a partir de una política prefijada $\pi$.
La evaluación de la política puede hacerse de forma iterativa:
1. Si la política se ejecuta para un solo paso, la utilidad es $U_1^\pi(s)=U^\pi(s) = R(s, \pi(s))$.
2. Los pasos posteriores pueden obtenerse a partir de la ecuación de **lookahead**, donde simplemente tenemos en cuenta la acumulación de utilidades esperadas a partir del recorrido que puede seguirse en el grafo de aplicación de acciones:
$$U^\pi_{k+1}(s) = R(s, \pi(s)) + \gamma \sum_{s'} T(s' | s, \pi(s))U^\pi_k(s')$$
!!!def:Lookahead
~~~~C
function lookahead(𝒫::MDP, U, s, a)
𝒮, T, R, γ = 𝒫.𝒮, 𝒫.T, 𝒫.R, 𝒫.γ
return R(s,a) + γ*sum(T(s,a,s')*U(s') for s' in 𝒮)
end
~~~~
---
## Evaluación de políticas
 $U^\pi$ puede calcularse con una precisión arbitraria si se realizan suficientes iteraciones de la ecuación lookahead. Hay convergencia porque, si $\gamma < 1$ y $R$ está acotada, la actualización en la ecuación es una contracción.
!!!def: Ecuación de Bellman
En la convergencia se verifica la igualdad (basta tomar límites en ambos términos):
$$U^\pi(s) = R(s, \pi(s)) + \gamma \sum_{s'} T(s' | s, \pi(s))U^\pi(s')$$
a la que se denomina **ecuación de Bellman**.
!!!def:Evaluación Iterativa
~~~~C
function iterative_policy_evaluation(𝒫::MDP, π, k_max)
𝒮, T, R, γ = 𝒫.𝒮, 𝒫.T, 𝒫.R, 𝒫.γ
U = [0.0 for s in 𝒮]
for k in 1:k_max
U = [lookahead(𝒫, U, s, π(s)) for s in 𝒮]
end
return U
end
~~~~
---
## Evaluación de políticas
Si $S$ es finito ($S=\{s_1,\dots,s_N\}$), entonces la evaluación de la política puede hacerse sin iteración resolviendo directamente el sistema de ecuaciones que refleja la ecuación de Bellman (un conjunto de $N$ ecuaciones lineales con $N$ incógnitas: $U^\pi(s_1),\dots,U^\pi(s_N)$).
!!!Tip: Resolución Exacta
Una forma de resolver este sistema de ecuaciones es convertirlo primero a forma matricial:
$${\mathbf U}^\pi = {\mathbf R}^\pi + \gamma\mathbf{T}^\pi \mathbf{U}^\pi$$
donde ${\mathbf U}^\pi$ y ${\mathbf R}^\pi$ son las **funciones de utilidad y recompensa** representadas en forma vectorial con $N$ componentes. La matriz ($N\times N$) $\mathbf{T}^\pi$ contiene las **probabilidades de transición** de los estados, donde $T^\pi_{ij}$ es la probabilidad de transición del estado $s_i$ al estado $s_j$.
!!!def:Evaluación de políticas
~~~~C
function policy_evaluation(𝒫::MDP, π)
𝒮, R, T, γ = 𝒫.𝒮, 𝒫.R, 𝒫.T, 𝒫.γ
R' = [R(s, π(s)) for s in 𝒮]
T' = [T(s, π(s), s') for s in 𝒮, s' in 𝒮]
return (I - γ*T')\R'
end
~~~~
---
## Políticas de la función de valor
!!!def: Política Voraz
Dada $U$, podemos construir $\pi$ que maximice la ecuación de lookahead:
$$\pi(s) = \arg \max_a \Big( R(s, a) + \gamma \sum_{s'} T(s' | s, a) U(s') \Big)$$
Nos referimos a esta política como una **política voraz** con respecto a $s$, ya que se preocupa de optimizar la política considerando solo un paso adelante. Si $U$ es la función de valor óptima, entonces la política extraída es óptima.
!!!def:Política Voraz
~~~~C
struct ValueFunctionPolicy
𝒫 # Problema
U # Función de Utilidad
end
function greedy(𝒫::MDP, U, s)
u, a = findmax(a->lookahead(𝒫, U, s, a), 𝒫.𝒜)
return (a=a, u=u)
end
(π::ValueFunctionPolicy)(s) = greedy(π.𝒫, π.U, s).a
~~~~
---
## Función $Q$
!!!def:$Q$-Función
Una forma alternativa de representar una política es utilizar la **función de valor de la acción**, a veces llamada **$Q$-función**, que representa el rendimiento esperado cuando se empieza en el estado $s$, se toma la acción $a$, y luego se continúa con la política voraz con respecto a $Q$:
$$Q(s, a) = R(s, a) + \gamma \sum_{s'} T(s' | s, a) U(s')$$
!!!Tip
A partir de esta función de valor de la acción, podemos obtener la función de valor y la política,
$$U(s) = \max_a Q(s, a)$$
$$\pi(s) = \arg \max_a Q(s, a)$$
!!!
Almacenar $Q$ requiere $O(|S| \times |A|)$ unidades en lugar de $O(|S|)$ para $U$, pero no tenemos que usar $R$ y $T$ para extraer la política.
---
## Iteración de la Política
La **iteración de la política** es una forma de calcular una política óptima: se itera entre la evaluación de la política y la mejora de la política mediante una política voraz.
Converge para cualquier política inicial, y en un número finito de iteraciones cuando hay un número finito de políticas.
!!!def: Iteración de la Política
~~~~C
struct PolicyIteration
π # Política Inicial
k_max # Máximo número de iteraciones
end
function solve(M::PolicyIteration, 𝒫::MDP)
π, 𝒮 = M.π, 𝒫.𝒮
for k = 1:M.k_max
U = policy_evaluation(𝒫, π)
π′ = ValueFunctionPolicy(𝒫, U)
if all(π(s) == π′(s) for s in 𝒮)
break
end
π = π′
end
return π
end
~~~~
---
## Iteración de la Política
* Tiende a ser costosa porque debemos evaluar la política en cada iteración.
* La variante **iteración de políticas modificada** aproxima la función de valor utilizando una evaluación de políticas iterativa en lugar de una evaluación de políticas exacta. Podemos elegir el número de iteraciones de evaluación de la política entre los pasos de mejora de la política.
* Si utilizamos solo una iteración entre pasos, este enfoque es idéntico a la iteración de valores.
---
## Iteración del Valor
Alternativa a la iteración de la política que se utiliza a menudo debido a su simplicidad: actualiza la función de valor directamente.
Comienza con cualquier función de valor $U$ acotada (por ejemplo, $U(s) = 0$ para todo $s$). La función de valor puede mejorarse aplicando la actualización de Bellman:
$$U_{k+1}(s) = \max_a \Big( R(s, a) + \gamma \sum_{s'} T(s' | s, a) U_k(s') \Big)$$
!!!def: Backup
~~~~C
function backup(𝒫::MDP, U, s)
return maximum(lookahead(𝒫, U, s, a) for a in 𝒫.𝒜)
end
~~~~
---
## Iteración del Valor
Se puede probar su convergencia, y se garantiza que esta política óptima satisface la ecuación de optimalidad de Bellman:
$$U^*(s) = \max_a \Big( R(s, a) + \gamma \sum_{s'} T(s' | s, a) U^*(s') \Big)$$
Se puede extraer una política óptima de $U^*$ de forma similar a como vimos antes:
!!!def:Iteración del Valor
~~~~C
struct ValueIteration
k_max # Máximo número de iteraciones
end
function solve(M::ValueIteration, 𝒫::MDP)
U = [0.0 for s in 𝒫.𝒮]
for k = 1:M.k_max
U = [backup(𝒫, U, s) for s in 𝒫.𝒮]
end
return ValueFunctionPolicy(𝒫, U)
end
~~~~
---
## Iteración del Valor
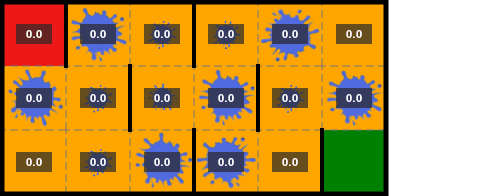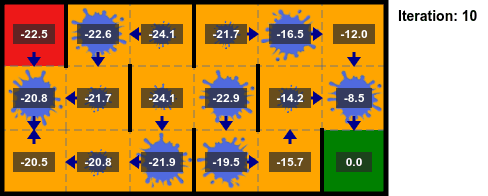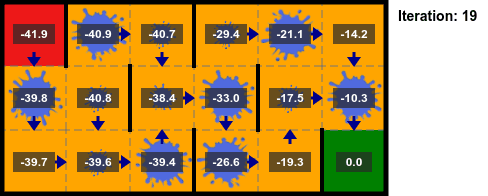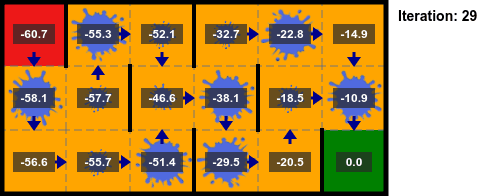
* La implementación se detiene después de un número fijo de iteraciones.
* Es común terminar las iteraciones según el valor $||U_{k+1} - U_k||_\infty$, llamado el **residuo de Bellman**:
* Si $||U_{k+1} - U_k||_\infty < \delta$ entonces $||U_k - U^*||_\infty < \epsilon=\delta \gamma/(1 - \gamma)$.
* Si $\gamma$ es cercano a $1$, la convergencia es más lenta, si $\gamma$ es más cercano a $0$, entonces no necesitamos realizar tantas iteraciones.
---
## Iteración asíncrona del valor
La iteración del valor es muy costosa, ya que cada entrada de $U_k$ se actualiza en cada iteración para obtener $U_{k+1}$.
En la **iteración de valor asíncrona**, sólo se actualiza un subconjunto de estados en cada iteración. Si cada estadp se actuliza un número infinito de veces, se garantiza la convergencia a $U^*$.
Un método común de iteración de valor asíncrono, la **iteración de valor Gauss-Seidel**, hace un barrido a través de un ordenamiento de los estados y aplica la actualización de Bellman en su lugar. El ahorro computacional reside en no tener que construir una segunda función de valor en memoria con cada iteración.
!!!def: Iteración Asíncrona del Valor
~~~~C
struct GaussSeidelValueIteration
k_max # Máximo número de iteraciones
end
function solve(M::GaussSeidelValueIteration, 𝒫::MDP)
U = [0.0 for s in 𝒫.𝒮]
for k = 1:M.k_max
for (i, s) in enumerate(𝒫.𝒮)
U[i] = backup(𝒫, U, s)
end
end
return ValueFunctionPolicy(𝒫, U)
end
~~~~
---
# Aprendizaje por Refuerzo (RL)
---
## Aprendizaje por Refuerzo
* En lo anterior, asumimos que los modelos de transición y recompensa son conocidos.
* Pero en muchos problemas es falso, y el agente debe aprender a actuar a través de la experiencia:
!!!Tip
Observando los resultados de sus acciones en forma de transiciones de estado y recompensas, el agente debe elegir acciones que maximicen su acumulación de recompensas a largo plazo.
!!!Note: **Aprendizaje por Refuerzo** (RL)
Aborda problemas en los que existe *incertidumbre sobre el modelo*.
!!!warning: Metodología:
1. Para poder conocer cómo funciona el mundo, el agente debe equilibrar la **exploración** del entorno con la **explotación** del conocimiento adquirido a través de las experiencias anteriores.
2. Como las recompensas pueden recibirse mucho después de las decisiones importantes, el crédito debe asignarse para *reforzar* las acciones correctas, y no todas las de la trayectoria.
3. El agente debe generalizar a partir de una experiencia limitada: habrá muchas partes no exploradas, y acciones no consideradas donde sí ha podido explorar.
---
## Aprendizaje por Refuerzo
!!!def: Tipos de RL
RL puede tener dos orientaciones principales:
1. Reconstruir un modelo de $T$ y $R$ que permita ejecutar las aproximaciones vistas anteriormente.
2. **Buscar un mecanismo para optimizar la recompensa final sin pasar por este aprendizaje intermedio de forma explícita**.
Evitar representaciones explícitas es atractivo, especialmente cuando el problema tiene una dimensión muy alta.
!!!Tip
Notas:
* Aunque el RL se ha centrado en problemas en los que se desconoce el modelo del entorno, también se utiliza a menudo para problemas con modelos conocidos.
* Los métodos libres de modelo que veremos pueden ser especialmente útiles en entornos complejos como una forma de programación dinámica aproximada.
* Pueden utilizarse para producir políticas en diferido (*offline*), o como medio para generar la siguiente acción en un contexto en tiempo real (*online*).
---
## Estimación Incremental de la Media
Muchos métodos libres de modelo estiman incrementalmente la función de valor de la acción $Q(s, a)$ a partir de muestras.
La estimación incremental de una variable cualquiera $X$ a partir de $m$ muestras, $x^{(1)},\dots,x^{(m)}$ sería:
$$\hat{x}_m = \frac{1}{m} \sum_{i=1}^m x^{(i)} = \frac{1}{m} \Big( x^{(m)} + \sum_{i=1}^{m−1} x^{(i)}\Big)=\frac{1}{m}\Big(x^{(m)} + (m − 1) \hat{x}_{m−1}\Big)=\hat{x}_{m−1} + \frac{1}{m} \Big(x^{(m)} − \hat{x}_{m−1}\Big)$$
Podemos reescribir esta ecuación con la introducción de una función de ratio de aprendizaje $\alpha_m$:
$$\hat{x}_m = \hat{x}_{m−1} + \alpha_m \Big(x^{(m)} − \hat{x}_{m−1}\Big)$$
$\alpha$ puede ser una función distinta de $1/m$.
!!!def: Regla de actualización
Si es constante, entonces los pesos de las muestras más antiguas decaen exponencialmente con una tasa de $(1 - \alpha)$. En este caso, podemos actualizar nuestra estimación después de observar $x$ utilizando la siguiente regla:
$$\hat{x}\leftarrow \hat{x} + \alpha(x − \hat{x})$$
---
## Q-Learning
Operemos...
$$Q(s, a) = R(s, a) + \gamma \sum_{s'} T(s' | s, a) U(s') = R(s, a) + \gamma \sum_{s'} T(s' | s, a) \max_{a'} Q(s', a')=\mathbb{E}_{r,s'}[r + \gamma \max_{a'} Q(s', a')]$$
Que podemos reescribir aplicando la estimación incremental como:
$$Q(s, a) \leftarrow Q(s, a) + \alpha \Big( r + \gamma \max_{a'} Q(s', a') − Q(s, a)\Big)$$
!!!def:Q- Learning
~~~~~~C
mutable struct QLearning
𝒮 # Espacio de Estados
𝒜 # Espacio de Acciones
γ # Factor de Descuento
Q # Función de Valor de Acción
α # Ratio de Aprendizaje
end
function update!(model::QLearning, s, a, r, s′)
γ, Q, α = model.γ, model.Q, model.α
Q[s,a] += α*(r + γ*maximum(Q[s′,:]) - Q[s,a])
return model
end
~~~~~~
---
## Q-Learning
La elección de acciones afecta a los estados en los que terminamos y a nuestra capacidad para estimar $Q(s, a)$ con precisión. Para garantizar la convergencia necesitamos adoptar alguna forma de política de exploración, como $\epsilon$-voraz.
---
## Sarsa
**Sarsa** es una alternativa a Q-Learning. Utiliza $(s, a, r, s', a')$ para actualizar $Q$ en cada paso:
$$Q(s, a) \leftarrow Q(s, a) + \alpha \Big( r + \gamma Q(s', a' ) − Q(s, a)\Big)$$
Con una estrategia de exploración adecuada, $a'$ convergerá a $\arg \max_{a'} Q(s', a')$, que es lo que se utiliza en Q-Learning.
!!!def: Sarsa
~~~~~~C
mutable struct Sarsa
𝒮 # Espacio de Estados
𝒜 # Espacio de Acciones
γ # Factor de Descuento
Q # Función de Valor de Acción
α # Factor de Aprendizaje
ℓ # Tupla de experiencia más reciente (s,a,r)
end
function update!(model::Sarsa, s, a, r, s′)
if model.ℓ != nothing
γ, Q, α, ℓ = model.γ, model.Q, model.α, model.ℓ
model.Q[ℓ.s,ℓ.a] += α*(ℓ.r + γ*Q[s,a] - Q[ℓ.s,ℓ.a])
end
model.ℓ = (s=s, a=a, r=r)
return model
end
~~~~~~
---
## Comparación Sarsa / Q-Learning
Este precambio hace que ambos métodos se clasifiquen de forma muy distinta:
* Sarsa es basado en políticas, intenta estimar directamente el valor de la política de exploración mientras la sigue.
* Q-Learning es no basado en políticas, intenta encontrar el valor de la política óptima mientras sigue la estrategia de exploración.
* Ambos convergen a una estrategia óptima, pero la velocidad de convergencia depende de la aplicación.

---
## Comparación Sarsa / Q-Learning
Lo que da lugar a la diferente implementación que se aprecia entre ellos:

---
# ML en la Toma de Decisiones
---
!!!def: Problemas:
* Las estructuras de datos que hemos de manipular para poder actualizar los valores asociados a las diversas funciones que calculamos ($U$, $Q$, $\pi$,...).
* El número de entradas que hemos de considerar son del orden de $|S|$ o $|S| \times |A|$.
* Intratable para los problemas interesantes (o imposibles para estados/acciones continuos).
* El problema radica en nuestra aproximación: estamos intentando representar funciones a partir de tablas de asociación (arrays, diccionarios, etc.).
!!!Tip: Soluciones
A lo largo del máster hemos encontrado métodos alternativos para aproximar estas funciones de forma mucho más compacta y eficiente: el **Aprendizaje Automático**, en general, y las **Redes Neuronales**, en particular.
 Si representamos adecuadamente los datos que usa el agente para su toma de decisiones (el estado actual, o la trayectoria de estados/acciones/recompensas de varios pasos de ejecución), podríamos usar ML para aproximar las funciones que, iterativamente, aproximan el conocimiento completo que requiere para una correcta toma de decisiones.
---
El uso de modelos de ML para aproximar este comportamiento se remonta a varios años atrás.
!!!Tip:**Deep Reinforcement Learning**
La aparición del Deep Learning ha multiplicado en varios órdenes de magnitud la capacidad de aproximación de entornos complejos, permitiendo que una sola red aproxime simultáneamente $U$, $Q$ y $\pi$, aprovechando que hacen uso de las mismas entradas y son interdependientes.

---
## Representaciones y Solvers para `POMDPs.jl`
El paquete `POMDPs.jl` se ha pensado como un sistema extensible donde definir interfaces de representación de problemas por medio MPDs (más generales que los que hemos visto aquí) y métodos de resolución de los mismos. Algunos de los más usados son (la lista crece continuamente gracias a las facilidades que ofrece Julia, que ofrece la posibilidad de que sea una comunidad de usuarios abierta la que mantenga con vida los paquetes):


!!!Tip
¡Atentos al papel fundamental que juegan los espacios de Estados y Acciones!
---
# Aplicaciones
---
---
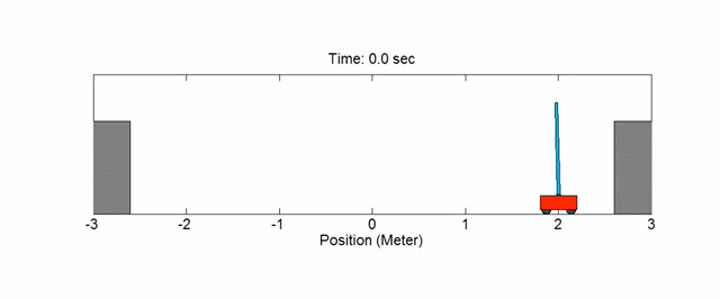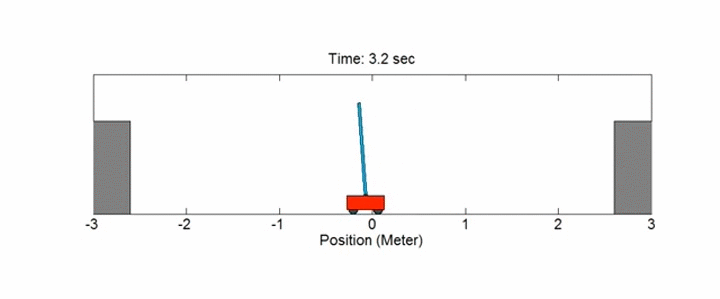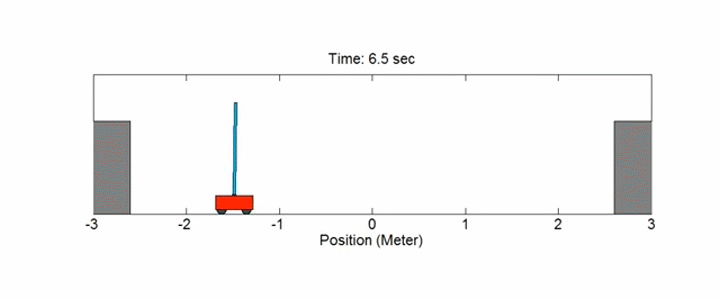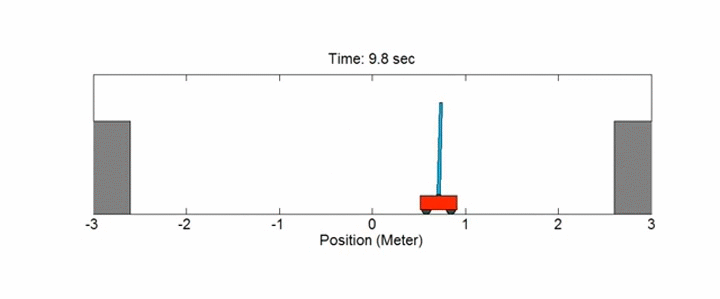
## MDPs no discretos: Cart-Pole
Este ejemplo se corresponde con la versión del problema **cart-pole** (carro con pértiga) descrito por Barto, Sutton y Anderson en [Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problem](https://ieeexplore.ieee.org/document/6313077):
!!!def: Cart-Pole
Una pértiga está unida por una articulación no accionada a un carro, que se mueve a lo largo de una pista sin fricción. La pértiga se coloca en posición vertical sobre el carro y el objetivo es equilibrarla aplicando fuerzas en la dirección izquierda y derecha sobre el carro.
---
## Espacio de Estados
El estado viene determinado por 4 observables (que se corresponden con 4 variables continuas):
!!!def:Espacio de estados
~~~~C
@with_kw struct CartPole
γ::Float64 = 1.0
force_magnitude::Float64 = 10.0
pole_length::Float64 = 1.0 # Longitud de la Pértiga
mass_cart::Float64 = 1.0
mass_pole::Float64 = 0.1
gravity::Float64 = 9.8
Δt::Float64 = 0.02 # Avance de tiempo en cada paso
Δx_max::Float64 = 4.8 # Máxima desviación en la posición
Δθ_max::Float64 = deg2rad(24) # Máxima desviación angular
end
struct CartPoleState
x::Float64 # Posición carro [m]
v::Float64 # Velocidad carro [m/s]
θ::Float64 # Ángulo Pértiga [rad]
ω::Float64 # Velocidad angular Pértiga [rad/s]
end
~~~~
---
## Espacio de Acciones | Estado Inicial | Estado Terminal
Hay dos acciones posibles: Empujar el carro a la derecha (1) o a la izquierda (2):
!!!def: Espacio de acciones
~~~~C
n_actions(mdp::CartPole) = 2
actions(mdp::CartPole) = [1,2]
~~~~
A todas las variables del estado se les asigna un valor aleatorio uniforme en `(-0,05, 0,05)`:
!!!def: Estado inicial
~~~~C
function generate_start_state(mdp::CartPole)
U = Uniform(-0.05,0.05)
return CartPoleState(rand(U), rand(U), rand(U), rand(U))
end
~~~~
El episodio para si el carro se sale de unos ciertos márgenes o si la pértiga se inclina en exceso:
!!!def: Estado Terminal
~~~~C
function is_terminal(mdp::CartPole, s::CartPoleState)
return abs(s.x) > mdp.Δx_max || abs(s.θ) > mdp.Δθ_max
end
~~~~
---
## Función de Transición
!!!def:Función de transición
~~~~C
function cart_pole_transition(mdp::CartPole, s::CartPoleState, a::Int)
if is_terminal(mdp, s)
return s
end
x, v, θ, ω = s.x, s.v, s.θ, s.ω
force = a == 1 ? mdp.force_magnitude : -mdp.force_magnitude
cθ, sθ = cos(θ), sin(θ)
half_length = mdp.pole_length / 2
mass_tot = mdp.mass_cart + mdp.mass_pole
temp = (force + half_length*sθ*ω^2) / mass_tot
# Pole acceleration
pole_α = (mdp.gravity*sθ - temp*cθ) / (half_length * (4.0/3.0 - mdp.mass_pole * cθ^2 / mass_tot))
# Cart acceleration
cart_a = temp - half_length * mdp.mass_pole * pole_α * cθ / mass_tot
# Euler integration
Δt = mdp.Δt
x += Δt*v
v += Δt*cart_a
θ += Δt*ω
ω += Δt*pole_α
return CartPoleState(x,v,θ,ω)
end
~~~~
---
## Función de Recompensas | MDP
Como el objetivo es mantener la pértiga vertical el mayor tiempo posible, se asigna una recompensa de `+1` por cada paso dado, incluido el paso de finalización.
!!!def: Función de Recompensas
~~~~C
function reward(mdp::CartPole, s::CartPoleState, a::Int)
if is_terminal(mdp, s)
return 0.0
else
return 1.0
end
end
~~~~
!!!def: MDP
~~~~C
function MDP(mdp::CartPole; γ::Float64=mdp.γ)
return MDP(
γ,
nothing, # Sin Espacio de Estados explícito (se genera)
actions(mdp),
nothing, # Sin función de transición explícita (se genera)
(s,a) -> reward(mdp, s, a),
(s, a)-> begin
s′ = cart_pole_transition(mdp, s, a)
r = reward(mdp, s, a)
return (s′, r)
end )
end
~~~~
---
# ¡Gracias!